Advancing Depth Anything Model for Unsupervised Monocular Depth Estimation in Endoscopy

0

Sign in to get full access
Overview
- This paper presents an "Advancing Depth Anything Model" for unsupervised monocular depth estimation in endoscopic images.
- The key innovations are using self-supervised pretraining on large-scale unlabeled data and architectural improvements to the Depth Anything model.
- The model achieves state-of-the-art performance on endoscopic depth estimation benchmarks.
Plain English Explanation
The researchers developed a new machine learning model called the "Advancing Depth Anything Model" to estimate the depth (distance from the camera) of objects in endoscopic images. Endoscopes are small cameras used to look inside the body during medical procedures.
Estimating depth from a single endoscopic image is challenging because the camera only captures a 2D flat image, but we need 3D depth information. The researchers tackled this problem using a technique called "self-supervised learning." This means they trained the model on a large amount of unlabeled endoscopic image data, without needing expensive human-annotated depth information.
The researchers also made some technical improvements to the model's architecture, which helped it better estimate depth in these complex endoscopic scenes. As a result, the Advancing Depth Anything Model achieved the best performance so far on standard benchmarks for endoscopic depth estimation.
This advance could help doctors better understand the 3D structure of the body during endoscopic procedures, potentially leading to improved surgical planning and outcomes for patients.
Technical Explanation
The paper introduces the "Advancing Depth Anything Model" for unsupervised monocular depth estimation in endoscopic images. The key innovations are:
-
Self-Supervised Pretraining: The model is first pretrained on a large-scale dataset of unlabeled endoscopic images using self-supervised learning techniques. This allows the model to learn general visual representations without needing expensive human-annotated depth data.
-
Architectural Improvements: The researchers make several architectural modifications to the original Depth Anything model, including a new multi-scale feature fusion module and attention-based depth refinement. These changes improve the model's ability to estimate depth accurately in the complex endoscopic domain.
The paper evaluates the Advancing Depth Anything Model on standard endoscopic depth estimation benchmarks and shows state-of-the-art performance compared to prior methods. Ablation studies demonstrate the importance of both the self-supervised pretraining and the architectural innovations.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the Advancing Depth Anything Model, including comparison to prior work, ablation studies, and visualization of results. However, the authors acknowledge some limitations:
- The model was only evaluated on endoscopic images, so its generalization to other medical imaging modalities is unclear.
- The self-supervised pretraining was done on a large but still limited dataset of endoscopic images. Expanding the pretraining dataset further could potentially improve performance.
- The model's performance on real-world clinical endoscopic data, as opposed to research datasets, is not assessed.
Additionally, while the paper demonstrates strong quantitative results, the practical implications for improved surgical guidance or patient outcomes are not explored in depth. Further research is needed to fully understand the clinical utility of this technology.
Conclusion
This paper presents the "Advancing Depth Anything Model," a novel approach for unsupervised monocular depth estimation in endoscopic images. The key innovations are self-supervised pretraining on large-scale unlabeled data and architectural improvements to the Depth Anything model.
The resulting model achieves state-of-the-art performance on endoscopic depth estimation benchmarks, suggesting it could be a valuable tool for improved 3D understanding during endoscopic medical procedures. While the paper has some limitations, it represents a significant advance in the field of endoscopic depth estimation with potential real-world clinical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Advancing Depth Anything Model for Unsupervised Monocular Depth Estimation in Endoscopy
Bojian Li, Bo Liu, Jinghua Yue, Fugen Zhou
Depth estimation is a cornerstone of 3D reconstruction and plays a vital role in minimally invasive endoscopic surgeries. However, most current depth estimation networks rely on traditional convolutional neural networks, which are limited in their ability to capture global information. Foundation models offer a promising avenue for enhancing depth estimation, but those currently available are primarily trained on natural images, leading to suboptimal performance when applied to endoscopic images. In this work, we introduce a novel fine-tuning strategy for the Depth Anything Model and integrate it with an intrinsic-based unsupervised monocular depth estimation framework. Our approach includes a low-rank adaptation technique based on random vectors, which improves the model's adaptability to different scales. Additionally, we propose a residual block built on depthwise separable convolution to compensate for the transformer's limited ability to capture high-frequency details, such as edges and textures. Our experimental results on the SCARED dataset show that our method achieves state-of-the-art performance while minimizing the number of trainable parameters. Applying this method in minimally invasive endoscopic surgery could significantly enhance both the precision and safety of these procedures.
Read more9/14/2024
0
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
This work presents Depth Anything, a highly practical solution for robust monocular depth estimation. Without pursuing novel technical modules, we aim to build a simple yet powerful foundation model dealing with any images under any circumstances. To this end, we scale up the dataset by designing a data engine to collect and automatically annotate large-scale unlabeled data (~62M), which significantly enlarges the data coverage and thus is able to reduce the generalization error. We investigate two simple yet effective strategies that make data scaling-up promising. First, a more challenging optimization target is created by leveraging data augmentation tools. It compels the model to actively seek extra visual knowledge and acquire robust representations. Second, an auxiliary supervision is developed to enforce the model to inherit rich semantic priors from pre-trained encoders. We evaluate its zero-shot capabilities extensively, including six public datasets and randomly captured photos. It demonstrates impressive generalization ability. Further, through fine-tuning it with metric depth information from NYUv2 and KITTI, new SOTAs are set. Our better depth model also results in a better depth-conditioned ControlNet. Our models are released at https://github.com/LiheYoung/Depth-Anything.
Read more4/9/2024
2
Depth Anything V2
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, Hengshuang Zhao
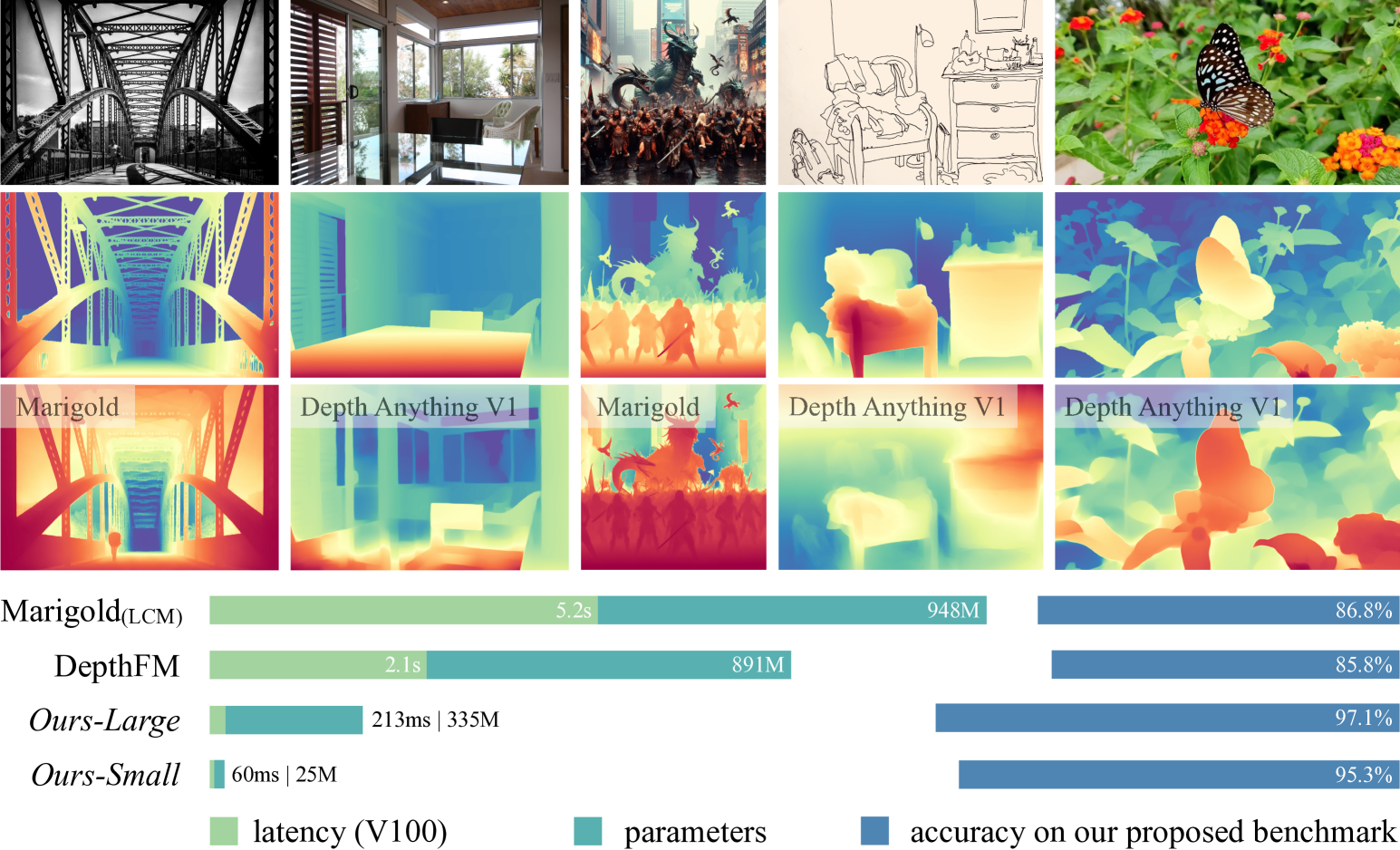
This work presents Depth Anything V2. Without pursuing fancy techniques, we aim to reveal crucial findings to pave the way towards building a powerful monocular depth estimation model. Notably, compared with V1, this version produces much finer and more robust depth predictions through three key practices: 1) replacing all labeled real images with synthetic images, 2) scaling up the capacity of our teacher model, and 3) teaching student models via the bridge of large-scale pseudo-labeled real images. Compared with the latest models built on Stable Diffusion, our models are significantly more efficient (more than 10x faster) and more accurate. We offer models of different scales (ranging from 25M to 1.3B params) to support extensive scenarios. Benefiting from their strong generalization capability, we fine-tune them with metric depth labels to obtain our metric depth models. In addition to our models, considering the limited diversity and frequent noise in current test sets, we construct a versatile evaluation benchmark with precise annotations and diverse scenes to facilitate future research.
Read more6/14/2024
0
EndoDAC: Efficient Adapting Foundation Model for Self-Supervised Depth Estimation from Any Endoscopic Camera
Beilei Cui, Mobarakol Islam, Long Bai, An Wang, Hongliang Ren
Depth estimation plays a crucial role in various tasks within endoscopic surgery, including navigation, surface reconstruction, and augmented reality visualization. Despite the significant achievements of foundation models in vision tasks, including depth estimation, their direct application to the medical domain often results in suboptimal performance. This highlights the need for efficient adaptation methods to adapt these models to endoscopic depth estimation. We propose Endoscopic Depth Any Camera (EndoDAC) which is an efficient self-supervised depth estimation framework that adapts foundation models to endoscopic scenes. Specifically, we develop the Dynamic Vector-Based Low-Rank Adaptation (DV-LoRA) and employ Convolutional Neck blocks to tailor the foundational model to the surgical domain, utilizing remarkably few trainable parameters. Given that camera information is not always accessible, we also introduce a self-supervised adaptation strategy that estimates camera intrinsics using the pose encoder. Our framework is capable of being trained solely on monocular surgical videos from any camera, ensuring minimal training costs. Experiments demonstrate that our approach obtains superior performance even with fewer training epochs and unaware of the ground truth camera intrinsics. Code is available at https://github.com/BeileiCui/EndoDAC.
Read more5/15/2024