Advancing Grounded Multimodal Named Entity Recognition via LLM-Based Reformulation and Box-Based Segmentation

0

Sign in to get full access
Overview
- This paper proposes an approach for advancing grounded multimodal named entity recognition (NER) by leveraging large language models (LLMs) for reformulation and box-based segmentation.
- The key innovations include using LLMs to rephrase entity mentions, integrating the Segment Anything Model (SAM) for box-based segmentation, and a contrastive training scheme that aligns visual and textual representations.
- The proposed method demonstrates state-of-the-art performance on several multimodal NER benchmarks, showcasing its effectiveness in grounding language understanding with visual information.
Plain English Explanation
The paper introduces a new technique for improving named entity recognition (NER) in multimodal settings, where both text and images are available. The core idea is to leverage large language models (LLMs) - powerful AI systems trained on vast amounts of text data - to help the NER model better understand and locate entities within a given image and text.
Specifically, the approach has three main components:
-
LLM-Based Reformulation: The model uses an LLM to rephrase or "reformulate" the entity mentions in the text, which can help the NER system better grasp the intended meaning.
-
Box-Based Segmentation: The model integrates the Segment Anything Model (SAM), a specialized AI system that can identify and outline relevant visual regions in the image. This allows the NER model to focus on the most salient parts of the image when identifying entities.
-
Contrastive Training: The researchers use a "contrastive" training approach, which aligns the visual and textual representations learned by the model. This helps the model better connect the language it understands with the visual information it observes, improving its ability to ground language in the real world.
By combining these innovative techniques, the researchers were able to demonstrate state-of-the-art performance on several benchmark datasets for multimodal NER. This suggests that their approach is a promising step forward in advancing grounded multimodal NER, a key challenge in combining language and vision for more robust natural language understanding.
Technical Explanation
The paper presents a novel approach for advancing grounded multimodal named entity recognition (NER) by leveraging large language models (LLMs) and the Segment Anything Model (SAM) for reformulation and box-based segmentation, respectively.
The key technical components are:
-
LLM-Based Reformulation: The authors use an LLM to rephrase the entity mentions in the input text, generating alternative formulations that can help the NER model better understand the intended meaning. This LLM-based reformulation is integrated into the overall model architecture.
-
Box-Based Segmentation: The researchers incorporate the Segment Anything Model (SAM), a state-of-the-art segmentation model, to identify relevant visual regions corresponding to the entities in the text. This allows the NER model to focus on the most salient parts of the image when making its predictions.
-
Contrastive Training: The model is trained using a contrastive learning objective, which aligns the visual and textual representations learned by the system. This encourages the model to develop a stronger connection between the language it understands and the visual information it observes, improving its ability to ground language in the real world.
The researchers evaluate their approach on several multimodal NER benchmarks, including GRIT and M2NER, and demonstrate state-of-the-art performance. This suggests that their LLM-based reformulation and box-based segmentation techniques are effective in enhancing multimodal NER capabilities.
Critical Analysis
The paper presents a compelling approach for advancing grounded multimodal NER, with several notable strengths:
-
The use of LLM-based reformulation is a clever way to leverage the rich language understanding capabilities of large language models to improve the NER system's comprehension of entity mentions.
-
Integrating the Segment Anything Model for box-based segmentation is an effective strategy for focusing the NER model on the most relevant visual regions, which can enhance its ability to ground language in the image.
-
The contrastive training scheme aligns the visual and textual representations in a principled manner, helping the model develop a stronger connection between language and vision.
However, the paper also has a few potential limitations:
-
The performance gains, while impressive, may be somewhat dependent on the specific benchmarks and datasets used. Further evaluation on a wider range of multimodal NER tasks would help establish the broader applicability of the approach.
-
The paper does not provide a detailed analysis of the types of errors the model makes or the specific cases where the LLM-based reformulation and box-based segmentation are most beneficial. Such insights could help guide future research and refinements of the technique.
-
The computational and memory requirements of the integrated SAM model may pose challenges for real-world deployment, especially on resource-constrained devices. Exploring more efficient alternatives or model compression techniques could be a valuable direction for future work.
Overall, the paper presents a well-designed and effective approach for advancing grounded multimodal NER, demonstrating the potential of leveraging LLMs and specialized computer vision models to enhance language understanding in multimodal settings. Further research and refinement of the technique could lead to even more robust and versatile multimodal NER systems.
Conclusion
This paper presents an innovative approach for advancing grounded multimodal named entity recognition (NER) by combining large language model (LLM)-based reformulation and box-based segmentation techniques. The key innovations include using LLMs to rephrase entity mentions, integrating the Segment Anything Model (SAM) for focused visual processing, and a contrastive training scheme that aligns visual and textual representations.
The proposed method achieves state-of-the-art performance on several multimodal NER benchmarks, showcasing its effectiveness in grounding language understanding with visual information. This work represents an important step forward in combining language and vision for robust natural language processing, with potential applications in a wide range of real-world scenarios that require grounding language in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Advancing Grounded Multimodal Named Entity Recognition via LLM-Based Reformulation and Box-Based Segmentation
Jinyuan Li, Ziyan Li, Han Li, Jianfei Yu, Rui Xia, Di Sun, Gang Pan
Grounded Multimodal Named Entity Recognition (GMNER) task aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging attributes: 1) The tenuous correlation between images and text on social media contributes to a notable proportion of named entities being ungroundable. 2) There exists a distinction between coarse-grained noun phrases used in similar tasks (e.g., phrase localization) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as connecting bridges. This reformulation brings two benefits: 1) It enables us to optimize the MNER module for optimal MNER performance and eliminates the need to pre-extract region features using object detection methods, thus naturally addressing the two major limitations of existing GMNER methods. 2) The introduction of Entity Expansion Expression module and Visual Entailment (VE) module unifies Visual Grounding (VG) and Entity Grounding (EG). This endows the proposed framework with unlimited data and model scalability. Furthermore, to address the potential ambiguity stemming from the coarse-grained bounding box output in GMNER, we further construct the new Segmented Multimodal Named Entity Recognition (SMNER) task and corresponding Twitter-SMNER dataset aimed at generating fine-grained segmentation masks, and experimentally demonstrate the feasibility and effectiveness of using box prompt-based Segment Anything Model (SAM) to empower any GMNER model with the ability to accomplish the SMNER task. Extensive experiments demonstrate that RiVEG significantly outperforms SoTA methods on four datasets across the MNER, GMNER, and SMNER tasks.
Read more6/12/2024
👁️
0
LLMs as Bridges: Reformulating Grounded Multimodal Named Entity Recognition
Jinyuan Li, Han Li, Di Sun, Jiahao Wang, Wenkun Zhang, Zan Wang, Gang Pan
Grounded Multimodal Named Entity Recognition (GMNER) is a nascent multimodal task that aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging properties: 1) The weak correlation between image-text pairs in social media results in a significant portion of named entities being ungroundable. 2) There exists a distinction between coarse-grained referring expressions commonly used in similar tasks (e.g., phrase localization, referring expression comprehension) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as a connecting bridge. This reformulation brings two benefits: 1) It maintains the optimal MNER performance and eliminates the need for employing object detection methods to pre-extract regional features, thereby naturally addressing two major limitations of existing GMNER methods. 2) The introduction of entity expansion expression and Visual Entailment (VE) module unifies Visual Grounding (VG) and Entity Grounding (EG). It enables RiVEG to effortlessly inherit the Visual Entailment and Visual Grounding capabilities of any current or prospective multimodal pretraining models. Extensive experiments demonstrate that RiVEG outperforms state-of-the-art methods on the existing GMNER dataset and achieves absolute leads of 10.65%, 6.21%, and 8.83% in all three subtasks.
Read more5/30/2024
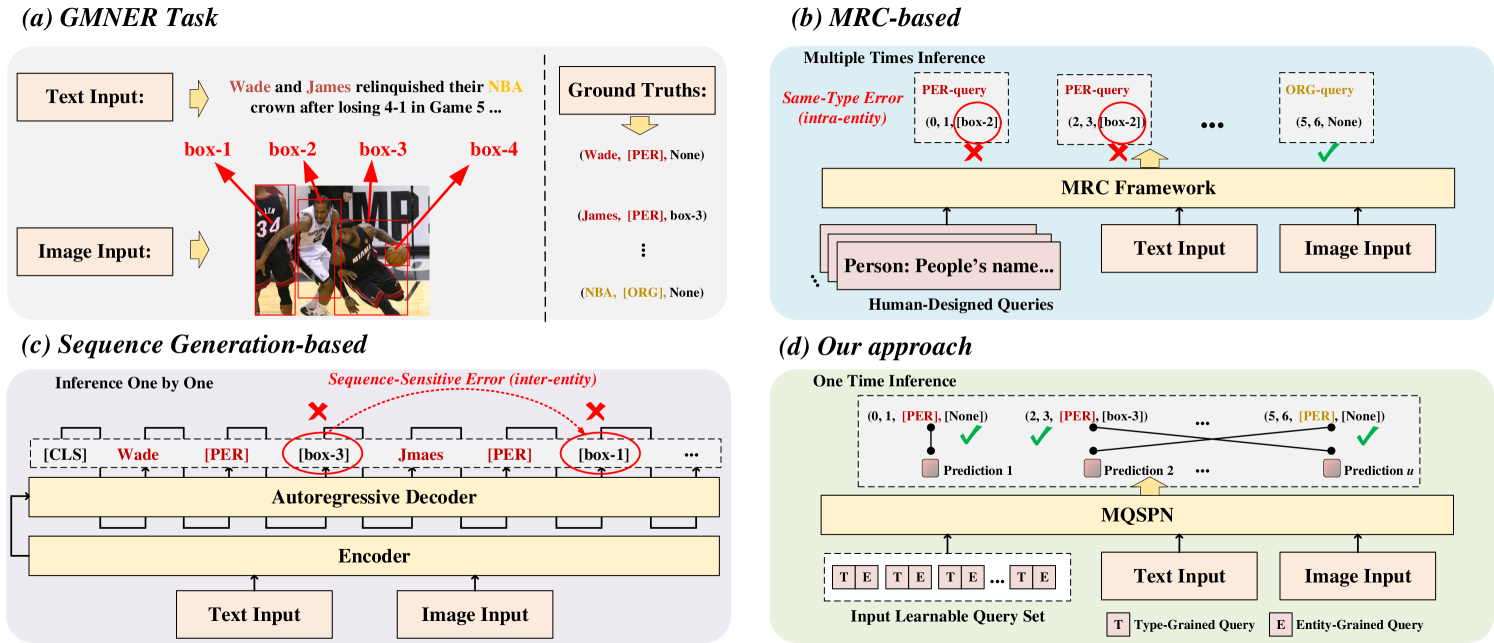
0
Multi-Grained Query-Guided Set Prediction Network for Grounded Multimodal Named Entity Recognition
Jielong Tang, Zhenxing Wang, Ziyang Gong, Jianxing Yu, Xiangwei Zhu, Jian Yin
Grounded Multimodal Named Entity Recognition (GMNER) is an emerging information extraction (IE) task, aiming to simultaneously extract entity spans, types, and corresponding visual regions of entities from given sentence-image pairs data. Recent unified methods employing machine reading comprehension or sequence generation-based frameworks show limitations in this difficult task. The former, utilizing human-designed queries, struggles to differentiate ambiguous entities, such as Jordan (Person) and off-White x Jordan (Shoes). The latter, following the one-by-one decoding order, suffers from exposure bias issues. We maintain that these works misunderstand the relationships of multimodal entities. To tackle these, we propose a novel unified framework named Multi-grained Query-guided Set Prediction Network (MQSPN) to learn appropriate relationships at intra-entity and inter-entity levels. Specifically, MQSPN consists of a Multi-grained Query Set (MQS) and a Multimodal Set Prediction Network (MSP). MQS explicitly aligns entity regions with entity spans by employing a set of learnable queries to strengthen intra-entity connections. Based on distinct intra-entity modeling, MSP reformulates GMNER as a set prediction, guiding models to establish appropriate inter-entity relationships from a global matching perspective. Additionally, we incorporate a query-guided Fusion Net (QFNet) to work as a glue network between MQS and MSP. Extensive experiments demonstrate that our approach achieves state-of-the-art performances in widely used benchmarks.
Read more8/22/2024
💬
0
2M-NER: Contrastive Learning for Multilingual and Multimodal NER with Language and Modal Fusion
Dongsheng Wang, Xiaoqin Feng, Zeming Liu, Chuan Wang
Named entity recognition (NER) is a fundamental task in natural language processing that involves identifying and classifying entities in sentences into pre-defined types. It plays a crucial role in various research fields, including entity linking, question answering, and online product recommendation. Recent studies have shown that incorporating multilingual and multimodal datasets can enhance the effectiveness of NER. This is due to language transfer learning and the presence of shared implicit features across different modalities. However, the lack of a dataset that combines multilingualism and multimodality has hindered research exploring the combination of these two aspects, as multimodality can help NER in multiple languages simultaneously. In this paper, we aim to address a more challenging task: multilingual and multimodal named entity recognition (MMNER), considering its potential value and influence. Specifically, we construct a large-scale MMNER dataset with four languages (English, French, German and Spanish) and two modalities (text and image). To tackle this challenging MMNER task on the dataset, we introduce a new model called 2M-NER, which aligns the text and image representations using contrastive learning and integrates a multimodal collaboration module to effectively depict the interactions between the two modalities. Extensive experimental results demonstrate that our model achieves the highest F1 score in multilingual and multimodal NER tasks compared to some comparative and representative baselines. Additionally, in a challenging analysis, we discovered that sentence-level alignment interferes a lot with NER models, indicating the higher level of difficulty in our dataset.
Read more4/29/2024