Multi-Grained Query-Guided Set Prediction Network for Grounded Multimodal Named Entity Recognition

0
Sign in to get full access
Overview
- This paper proposes a novel architecture called Multi-Grained Query-Guided Set Prediction Network (MGQSP) for Grounded Multimodal Named Entity Recognition.
- It combines multi-modal and multi-granular features to predict a set of named entities in an image, guided by a text query.
- The model achieves state-of-the-art performance on benchmark datasets for Multimodal Named Entity Recognition.
Plain English Explanation
The paper describes a new AI system that can identify and extract named entities (like people, places, and organizations) from images, based on a text query. For example, if you show the system an image and ask "Who are the people in this photo?", it can detect and label the individuals in the image.
This is a challenging task because it requires understanding both the visual information in the image and the semantic meaning of the text query. The key innovation in this paper is the use of "multi-grained" features - the system looks at the image and text at multiple levels of detail to get a more comprehensive understanding.
The model first extracts visual and textual features at different scales (e.g. the whole image, individual objects, words in the query). It then uses a "query-guided" approach, where the text query helps focus the model's attention on the most relevant parts of the image. Finally, the model predicts a set of named entities that match the image and query.
By combining these multi-modal and multi-granular techniques, the system is able to outperform previous approaches to Grounded Multimodal Named Entity Recognition. This could have applications in areas like Multilingual Multimodal NER and Few-Shot NER.
Technical Explanation
The paper introduces the Multi-Grained Query-Guided Set Prediction Network (MGQSP), a novel architecture for Grounded Multimodal Named Entity Recognition. The key components of the model are:
-
Multi-Grained Feature Extraction: The model extracts visual and textual features at multiple levels of granularity, including the whole image, individual objects, and words in the query. This allows it to capture both coarse-grained and fine-grained information.
-
Query-Guided Attention: The textual query is used to guide the model's attention, helping it focus on the most relevant parts of the image for the given task.
-
Set Prediction: The model predicts a set of named entities in the image, rather than just a single label. This is more flexible and better matches the real-world nature of the problem.
The authors evaluate their model on benchmark datasets for Multimodal Named Entity Recognition, demonstrating state-of-the-art performance. They also conduct ablation studies to analyze the contribution of each component of the architecture.
Critical Analysis
The paper presents a well-designed and thorough approach to Grounded Multimodal Named Entity Recognition. The use of multi-grained features and query-guided attention is a clever way to combine visual and textual information effectively.
However, the authors acknowledge some limitations of their work. First, the model is currently optimized for a single-shot task, where the query and image are provided together. Extending it to a more realistic incremental or interactive setting could be an interesting direction for future research.
Additionally, the model was evaluated on standard benchmark datasets, but its performance on real-world, noisy data with diverse named entities and query types remains to be tested. Exploring the model's robustness and generalization capabilities would be a valuable next step.
Overall, the Multi-Grained Query-Guided Set Prediction Network represents a significant advancement in Grounded Multimodal Named Entity Recognition and could have important implications for a variety of applications that require understanding the relationship between text and visual information.
Conclusion
This paper introduces the Multi-Grained Query-Guided Set Prediction Network, a novel architecture for Grounded Multimodal Named Entity Recognition. By combining multi-modal and multi-granular features with a query-guided attention mechanism, the model achieves state-of-the-art performance on benchmark datasets for Multimodal Named Entity Recognition.
The key innovations of this work are the use of multi-grained features and query-guided attention, which allow the model to effectively integrate visual and textual information to identify named entities in images. This could have significant implications for a range of applications, from Multilingual Multimodal NER to Few-Shot NER.
While the paper demonstrates the effectiveness of the proposed approach, there are still opportunities for further research to address the limitations and explore the model's broader applicability. Overall, this work represents an important step forward in the field of Grounded Multimodal Named Entity Recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Grained Query-Guided Set Prediction Network for Grounded Multimodal Named Entity Recognition
Jielong Tang, Zhenxing Wang, Ziyang Gong, Jianxing Yu, Xiangwei Zhu, Jian Yin
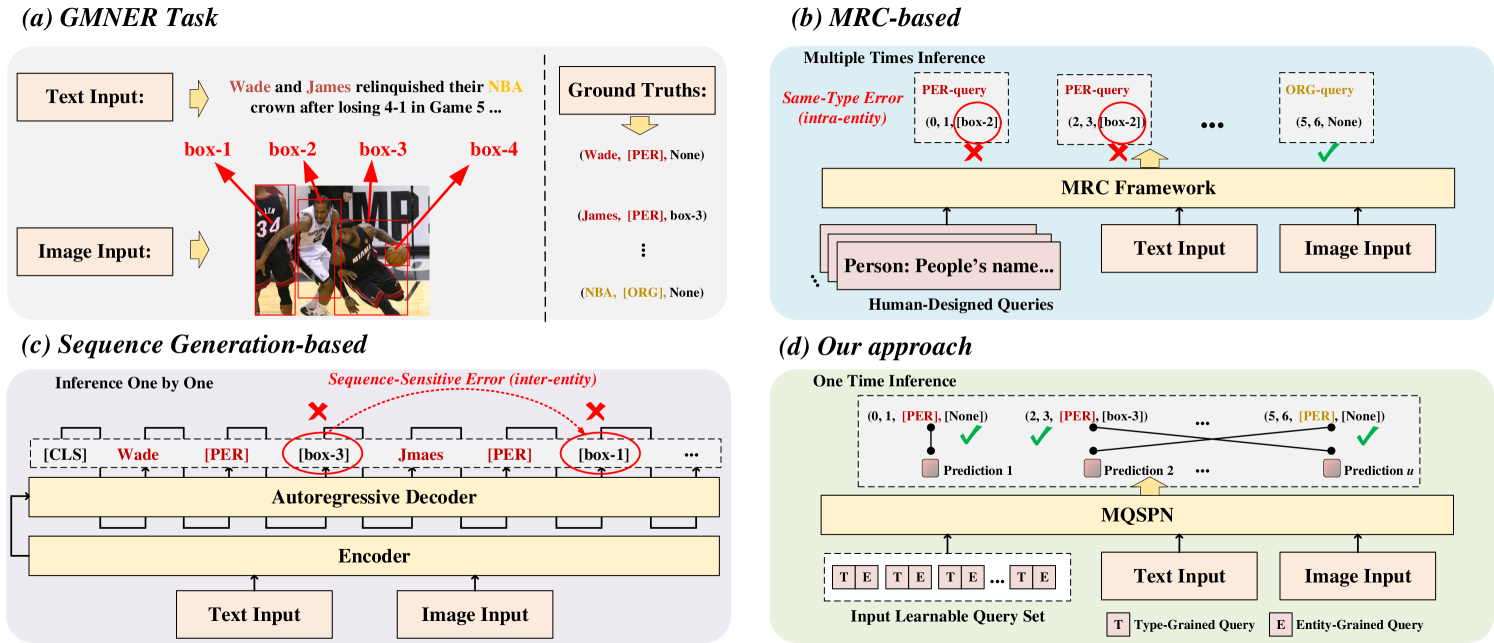
Grounded Multimodal Named Entity Recognition (GMNER) is an emerging information extraction (IE) task, aiming to simultaneously extract entity spans, types, and corresponding visual regions of entities from given sentence-image pairs data. Recent unified methods employing machine reading comprehension or sequence generation-based frameworks show limitations in this difficult task. The former, utilizing human-designed queries, struggles to differentiate ambiguous entities, such as Jordan (Person) and off-White x Jordan (Shoes). The latter, following the one-by-one decoding order, suffers from exposure bias issues. We maintain that these works misunderstand the relationships of multimodal entities. To tackle these, we propose a novel unified framework named Multi-grained Query-guided Set Prediction Network (MQSPN) to learn appropriate relationships at intra-entity and inter-entity levels. Specifically, MQSPN consists of a Multi-grained Query Set (MQS) and a Multimodal Set Prediction Network (MSP). MQS explicitly aligns entity regions with entity spans by employing a set of learnable queries to strengthen intra-entity connections. Based on distinct intra-entity modeling, MSP reformulates GMNER as a set prediction, guiding models to establish appropriate inter-entity relationships from a global matching perspective. Additionally, we incorporate a query-guided Fusion Net (QFNet) to work as a glue network between MQS and MSP. Extensive experiments demonstrate that our approach achieves state-of-the-art performances in widely used benchmarks.
Read more8/22/2024

0
Advancing Grounded Multimodal Named Entity Recognition via LLM-Based Reformulation and Box-Based Segmentation
Jinyuan Li, Ziyan Li, Han Li, Jianfei Yu, Rui Xia, Di Sun, Gang Pan
Grounded Multimodal Named Entity Recognition (GMNER) task aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging attributes: 1) The tenuous correlation between images and text on social media contributes to a notable proportion of named entities being ungroundable. 2) There exists a distinction between coarse-grained noun phrases used in similar tasks (e.g., phrase localization) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as connecting bridges. This reformulation brings two benefits: 1) It enables us to optimize the MNER module for optimal MNER performance and eliminates the need to pre-extract region features using object detection methods, thus naturally addressing the two major limitations of existing GMNER methods. 2) The introduction of Entity Expansion Expression module and Visual Entailment (VE) module unifies Visual Grounding (VG) and Entity Grounding (EG). This endows the proposed framework with unlimited data and model scalability. Furthermore, to address the potential ambiguity stemming from the coarse-grained bounding box output in GMNER, we further construct the new Segmented Multimodal Named Entity Recognition (SMNER) task and corresponding Twitter-SMNER dataset aimed at generating fine-grained segmentation masks, and experimentally demonstrate the feasibility and effectiveness of using box prompt-based Segment Anything Model (SAM) to empower any GMNER model with the ability to accomplish the SMNER task. Extensive experiments demonstrate that RiVEG significantly outperforms SoTA methods on four datasets across the MNER, GMNER, and SMNER tasks.
Read more6/12/2024
👁️
0
LLMs as Bridges: Reformulating Grounded Multimodal Named Entity Recognition
Jinyuan Li, Han Li, Di Sun, Jiahao Wang, Wenkun Zhang, Zan Wang, Gang Pan
Grounded Multimodal Named Entity Recognition (GMNER) is a nascent multimodal task that aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging properties: 1) The weak correlation between image-text pairs in social media results in a significant portion of named entities being ungroundable. 2) There exists a distinction between coarse-grained referring expressions commonly used in similar tasks (e.g., phrase localization, referring expression comprehension) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as a connecting bridge. This reformulation brings two benefits: 1) It maintains the optimal MNER performance and eliminates the need for employing object detection methods to pre-extract regional features, thereby naturally addressing two major limitations of existing GMNER methods. 2) The introduction of entity expansion expression and Visual Entailment (VE) module unifies Visual Grounding (VG) and Entity Grounding (EG). It enables RiVEG to effortlessly inherit the Visual Entailment and Visual Grounding capabilities of any current or prospective multimodal pretraining models. Extensive experiments demonstrate that RiVEG outperforms state-of-the-art methods on the existing GMNER dataset and achieves absolute leads of 10.65%, 6.21%, and 8.83% in all three subtasks.
Read more5/30/2024
0
SCANNER: Knowledge-Enhanced Approach for Robust Multi-modal Named Entity Recognition of Unseen Entities
Hyunjong Ok, Taeho Kil, Sukmin Seo, Jaeho Lee
Recent advances in named entity recognition (NER) have pushed the boundary of the task to incorporate visual signals, leading to many variants, including multi-modal NER (MNER) or grounded MNER (GMNER). A key challenge to these tasks is that the model should be able to generalize to the entities unseen during the training, and should be able to handle the training samples with noisy annotations. To address this obstacle, we propose SCANNER (Span CANdidate detection and recognition for NER), a model capable of effectively handling all three NER variants. SCANNER is a two-stage structure; we extract entity candidates in the first stage and use it as a query to get knowledge, effectively pulling knowledge from various sources. We can boost our performance by utilizing this entity-centric extracted knowledge to address unseen entities. Furthermore, to tackle the challenges arising from noisy annotations in NER datasets, we introduce a novel self-distillation method, enhancing the robustness and accuracy of our model in processing training data with inherent uncertainties. Our approach demonstrates competitive performance on the NER benchmark and surpasses existing methods on both MNER and GMNER benchmarks. Further analysis shows that the proposed distillation and knowledge utilization methods improve the performance of our model on various benchmarks.
Read more4/3/2024