LLMs as Bridges: Reformulating Grounded Multimodal Named Entity Recognition

0
👁️
Sign in to get full access
Overview
- This paper introduces a novel approach for Named Entity Recognition (NER) using contrastive learning and multimodal data.
- The proposed model, called 2M-NER, leverages large language models and visual information to improve NER performance, particularly in multilingual and multimodal settings.
- The paper also introduces a new multimodal NER dataset, which combines text and images to enhance entity recognition.
Plain English Explanation
2M-NER is a machine learning model that aims to improve the accuracy of named entity recognition, which is the process of identifying and classifying key information (like people, organizations, or locations) within text. The model uses a technique called "contrastive learning" to learn better representations of entities, and it also takes advantage of visual information (like images) to enhance its performance, especially when dealing with text in multiple languages.
The key innovation in this paper is the idea of combining textual and visual data to improve named entity recognition. By looking at both the words used and the surrounding images, the model can better understand the context and meaning of the entities it's trying to identify. This is particularly helpful in multilingual settings, where the same entity might be expressed differently in different languages.
Technical Explanation
The 2M-NER model uses a contrastive learning approach to learn better representations of named entities. Contrastive learning is a technique that trains the model to distinguish between "positive" examples (i.e., correct entity representations) and "negative" examples (i.e., incorrect or irrelevant representations). By learning these distinctions, the model can develop a more nuanced understanding of what constitutes a valid named entity.
To incorporate visual information, the 2M-NER model uses a multimodal architecture that combines textual and visual inputs. The textual input is processed using a large language model, such as BERT, while the visual input is processed using a convolutional neural network (CNN). The outputs of these two branches are then combined and used for the final named entity recognition task.
The paper also introduces a new multimodal NER dataset that includes both text and images. This dataset is used to train and evaluate the 2M-NER model, and the results show that the multimodal approach outperforms text-only models, particularly in multilingual settings.
Critical Analysis
The 2M-NER model represents an interesting and promising approach to improving named entity recognition, especially in multilingual and multimodal settings. The use of contrastive learning and the incorporation of visual information are well-motivated and seem to provide tangible benefits.
However, the paper does not address several potential limitations and areas for further research. For example, the model's performance may be heavily dependent on the quality and relevance of the visual information provided, and it's not clear how the model would handle cases where the visual and textual information are not well-aligned or even contradictory.
Additionally, the paper does not explore the interpretability of the model's decision-making process. Understanding why the model makes certain entity recognition decisions could be important for real-world applications, where transparency and explainability are often essential.
Further research could also investigate the scalability of the 2M-NER approach, particularly in terms of its ability to handle large-scale, diverse datasets and its computational efficiency in real-time applications.
Conclusion
The 2M-NER model represents an innovative approach to named entity recognition that leverages contrastive learning and multimodal data. By combining textual and visual information, the model can achieve improved performance, especially in multilingual settings.
This research highlights the potential benefits of integrating multiple modalities for natural language processing tasks, and it suggests that further exploration of multimodal approaches could lead to significant advancements in the field. As the use of language models and computer vision continues to evolve, the 2M-NER model and similar multimodal techniques may become increasingly important for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
0
LLMs as Bridges: Reformulating Grounded Multimodal Named Entity Recognition
Jinyuan Li, Han Li, Di Sun, Jiahao Wang, Wenkun Zhang, Zan Wang, Gang Pan
Grounded Multimodal Named Entity Recognition (GMNER) is a nascent multimodal task that aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging properties: 1) The weak correlation between image-text pairs in social media results in a significant portion of named entities being ungroundable. 2) There exists a distinction between coarse-grained referring expressions commonly used in similar tasks (e.g., phrase localization, referring expression comprehension) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as a connecting bridge. This reformulation brings two benefits: 1) It maintains the optimal MNER performance and eliminates the need for employing object detection methods to pre-extract regional features, thereby naturally addressing two major limitations of existing GMNER methods. 2) The introduction of entity expansion expression and Visual Entailment (VE) module unifies Visual Grounding (VG) and Entity Grounding (EG). It enables RiVEG to effortlessly inherit the Visual Entailment and Visual Grounding capabilities of any current or prospective multimodal pretraining models. Extensive experiments demonstrate that RiVEG outperforms state-of-the-art methods on the existing GMNER dataset and achieves absolute leads of 10.65%, 6.21%, and 8.83% in all three subtasks.
Read more5/30/2024

0
Advancing Grounded Multimodal Named Entity Recognition via LLM-Based Reformulation and Box-Based Segmentation
Jinyuan Li, Ziyan Li, Han Li, Jianfei Yu, Rui Xia, Di Sun, Gang Pan
Grounded Multimodal Named Entity Recognition (GMNER) task aims to identify named entities, entity types and their corresponding visual regions. GMNER task exhibits two challenging attributes: 1) The tenuous correlation between images and text on social media contributes to a notable proportion of named entities being ungroundable. 2) There exists a distinction between coarse-grained noun phrases used in similar tasks (e.g., phrase localization) and fine-grained named entities. In this paper, we propose RiVEG, a unified framework that reformulates GMNER into a joint MNER-VE-VG task by leveraging large language models (LLMs) as connecting bridges. This reformulation brings two benefits: 1) It enables us to optimize the MNER module for optimal MNER performance and eliminates the need to pre-extract region features using object detection methods, thus naturally addressing the two major limitations of existing GMNER methods. 2) The introduction of Entity Expansion Expression module and Visual Entailment (VE) module unifies Visual Grounding (VG) and Entity Grounding (EG). This endows the proposed framework with unlimited data and model scalability. Furthermore, to address the potential ambiguity stemming from the coarse-grained bounding box output in GMNER, we further construct the new Segmented Multimodal Named Entity Recognition (SMNER) task and corresponding Twitter-SMNER dataset aimed at generating fine-grained segmentation masks, and experimentally demonstrate the feasibility and effectiveness of using box prompt-based Segment Anything Model (SAM) to empower any GMNER model with the ability to accomplish the SMNER task. Extensive experiments demonstrate that RiVEG significantly outperforms SoTA methods on four datasets across the MNER, GMNER, and SMNER tasks.
Read more6/12/2024

0
GEIC: Universal and Multilingual Named Entity Recognition with Large Language Models
Hanjun Luo, Yingbin Jin, Xuecheng Liu, Tong Shang, Ruizhe Chen, Zuozhu Liu
Large Language Models (LLMs) have supplanted traditional methods in numerous natural language processing tasks. Nonetheless, in Named Entity Recognition (NER), existing LLM-based methods underperform compared to baselines and require significantly more computational resources, limiting their application. In this paper, we introduce the task of generation-based extraction and in-context classification (GEIC), designed to leverage LLMs' prior knowledge and self-attention mechanisms for NER tasks. We then propose CascadeNER, a universal and multilingual GEIC framework for few-shot and zero-shot NER. CascadeNER employs model cascading to utilize two small-parameter LLMs to extract and classify independently, reducing resource consumption while enhancing accuracy. We also introduce AnythingNER, the first NER dataset specifically designed for LLMs, including 8 languages, 155 entity types and a novel dynamic categorization system. Experiments show that CascadeNER achieves state-of-the-art performance on low-resource and fine-grained scenarios, including CrossNER and FewNERD. Our work is openly accessible.
Read more9/26/2024
0
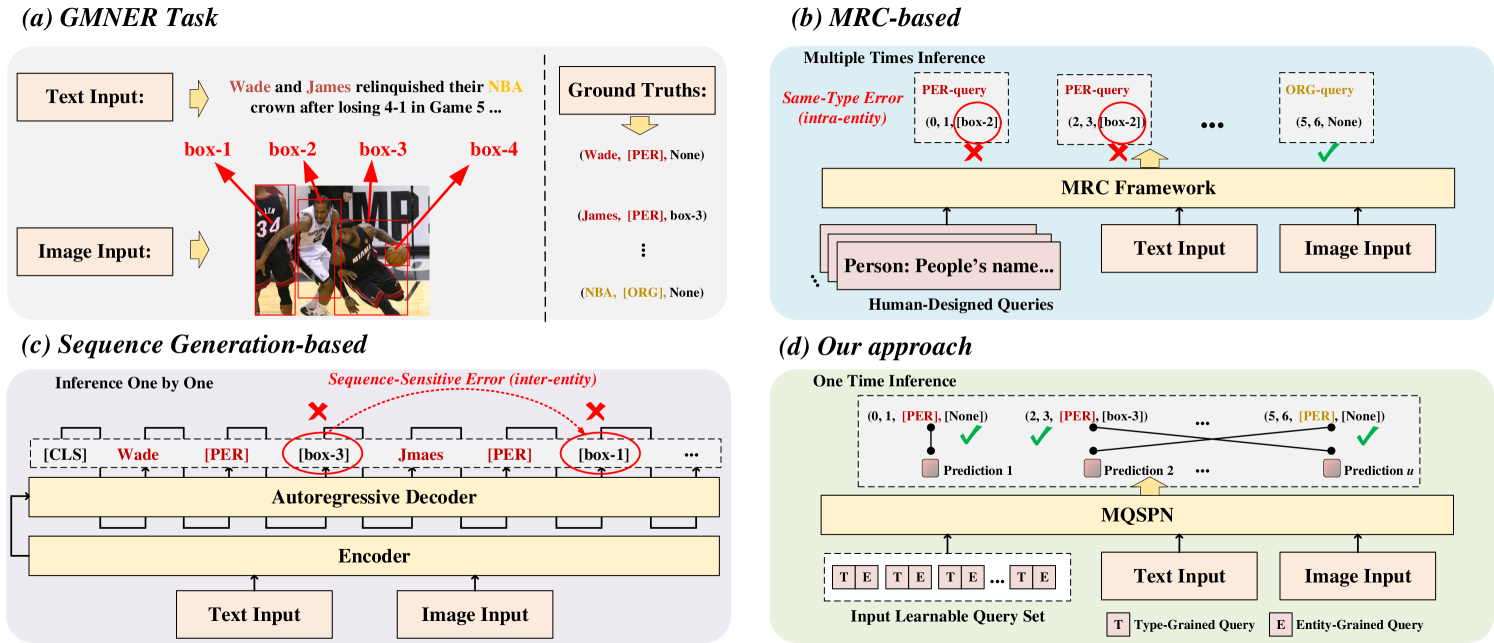
Multi-Grained Query-Guided Set Prediction Network for Grounded Multimodal Named Entity Recognition
Jielong Tang, Zhenxing Wang, Ziyang Gong, Jianxing Yu, Xiangwei Zhu, Jian Yin
Grounded Multimodal Named Entity Recognition (GMNER) is an emerging information extraction (IE) task, aiming to simultaneously extract entity spans, types, and corresponding visual regions of entities from given sentence-image pairs data. Recent unified methods employing machine reading comprehension or sequence generation-based frameworks show limitations in this difficult task. The former, utilizing human-designed queries, struggles to differentiate ambiguous entities, such as Jordan (Person) and off-White x Jordan (Shoes). The latter, following the one-by-one decoding order, suffers from exposure bias issues. We maintain that these works misunderstand the relationships of multimodal entities. To tackle these, we propose a novel unified framework named Multi-grained Query-guided Set Prediction Network (MQSPN) to learn appropriate relationships at intra-entity and inter-entity levels. Specifically, MQSPN consists of a Multi-grained Query Set (MQS) and a Multimodal Set Prediction Network (MSP). MQS explicitly aligns entity regions with entity spans by employing a set of learnable queries to strengthen intra-entity connections. Based on distinct intra-entity modeling, MSP reformulates GMNER as a set prediction, guiding models to establish appropriate inter-entity relationships from a global matching perspective. Additionally, we incorporate a query-guided Fusion Net (QFNet) to work as a glue network between MQS and MSP. Extensive experiments demonstrate that our approach achieves state-of-the-art performances in widely used benchmarks.
Read more8/22/2024