Advancing Speech Translation: A Corpus of Mandarin-English Conversational Telephone Speech

0
🗣️
Sign in to get full access
Overview
- This paper presents a new corpus of Mandarin-English conversational telephone speech, which aims to advance the field of speech translation.
- The corpus includes spontaneous speech data from real-world telephone conversations, as well as high-quality human translations.
- The dataset is designed to support research in speech recognition, machine translation, and speech translation for the Mandarin-English language pair.
Plain English Explanation
This research paper describes the creation of a new dataset that can be used to improve speech translation technology between Mandarin Chinese and English. The dataset contains recordings of real-life telephone conversations between Mandarin and English speakers, as well as high-quality human translations of those conversations.
By having access to this type of realistic, conversational data, researchers can develop better speech recognition and translation models that can handle the nuances and challenges of natural spoken language. This is an important step forward for building more robust and practical speech translation systems that can be used in real-world applications like business calls, customer service, and international communication.
Technical Explanation
The paper introduces a new Mandarin-English conversational telephone speech corpus that was collected and annotated to advance the field of speech translation. The corpus contains spontaneous speech data from real-world telephone conversations between native Mandarin and English speakers, as well as high-quality human translations of those conversations.
The dataset was designed to address the lack of publicly available, high-quality speech translation resources for the Mandarin-English language pair. It includes approximately 200 hours of audio data, with each conversation lasting around 10 minutes. The conversations cover a range of topics typical of real-world telephone calls, such as business, travel, and personal matters.
In addition to the audio recordings, the corpus provides word-level alignments between the Mandarin and English transcripts, enabling research into simultaneous interpretation and other speech translation tasks. The authors also describe the data collection and annotation process, as well as the quality control measures taken to ensure the reliability of the translations.
Critical Analysis
The authors acknowledge that the dataset is limited in size compared to some other speech corpora, which may constrain its usefulness for certain applications or training of large-scale models. Additionally, the conversations are primarily between native speakers, so the dataset may not fully capture the challenges of speech translation for non-native speakers.
That said, the Mandarin-English conversational telephone speech corpus represents a significant advancement in the availability of high-quality, realistic data for speech translation research. The inclusion of spontaneous, conversational speech data is particularly valuable, as it reflects the true complexity of real-world communication scenarios that speech translation systems must be able to handle.
Furthermore, the authors' emphasis on data quality and the availability of human translations sets this dataset apart from many existing resources, which often rely on machine-generated translations or transcripts. This attention to detail and fidelity to the original speech acts is crucial for developing speech translation models that can achieve human-level performance.
Conclusion
The Mandarin-English conversational telephone speech corpus introduced in this paper represents an important step forward in the field of speech translation. By providing a high-quality dataset of spontaneous, conversational speech, the authors have created a valuable resource that can support the development of more robust and practical speech translation systems capable of handling the complexities of real-world communication.
This work also highlights the ongoing need for language-specific resources and the challenges of building multilingual speech processing capabilities that can address the unique characteristics of different language pairs. As the field of speech translation continues to evolve, datasets like this one will be invaluable for advancing the state of the art and bringing more effective communication tools to global users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Advancing Speech Translation: A Corpus of Mandarin-English Conversational Telephone Speech
Shannon Wotherspoon, William Hartmann, Matthew Snover
This paper introduces a set of English translations for a 123-hour subset of the CallHome Mandarin Chinese data and the HKUST Mandarin Telephone Speech data for the task of speech translation. Paired source-language speech and target-language text is essential for training end-to-end speech translation systems and can provide substantial performance improvements for cascaded systems as well, relative to training on more widely available text data sets. We demonstrate that fine-tuning a general-purpose translation model to our Mandarin-English conversational telephone speech training set improves target-domain BLEU by more than 8 points, highlighting the importance of matched training data.
Read more4/19/2024

0
WenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark
Linhan Ma, Dake Guo, Kun Song, Yuepeng Jiang, Shuai Wang, Liumeng Xue, Weiming Xu, Huan Zhao, Binbin Zhang, Lei Xie
With the development of large text-to-speech (TTS) models and scale-up of the training data, state-of-the-art TTS systems have achieved impressive performance. In this paper, we present WenetSpeech4TTS, a multi-domain Mandarin corpus derived from the open-sourced WenetSpeech dataset. Tailored for the text-to-speech tasks, we refined WenetSpeech by adjusting segment boundaries, enhancing the audio quality, and eliminating speaker mixing within each segment. Following a more accurate transcription process and quality-based data filtering process, the obtained WenetSpeech4TTS corpus contains $12,800$ hours of paired audio-text data. Furthermore, we have created subsets of varying sizes, categorized by segment quality scores to allow for TTS model training and fine-tuning. VALL-E and NaturalSpeech 2 systems are trained and fine-tuned on these subsets to validate the usability of WenetSpeech4TTS, establishing baselines on benchmark for fair comparison of TTS systems. The corpus and corresponding benchmarks are publicly available on huggingface.
Read more6/21/2024
🗣️
0
Cross-Lingual Conversational Speech Summarization with Large Language Models
Max Nelson, Shannon Wotherspoon, Francis Keith, William Hartmann, Matthew Snover
Cross-lingual conversational speech summarization is an important problem, but suffers from a dearth of resources. While transcriptions exist for a number of languages, translated conversational speech is rare and datasets containing summaries are non-existent. We build upon the existing Fisher and Callhome Spanish-English Speech Translation corpus by supplementing the translations with summaries. The summaries are generated using GPT-4 from the reference translations and are treated as ground truth. The task is to generate similar summaries in the presence of transcription and translation errors. We build a baseline cascade-based system using open-source speech recognition and machine translation models. We test a range of LLMs for summarization and analyze the impact of transcription and translation errors. Adapting the Mistral-7B model for this task performs significantly better than off-the-shelf models and matches the performance of GPT-4.
Read more8/14/2024
0
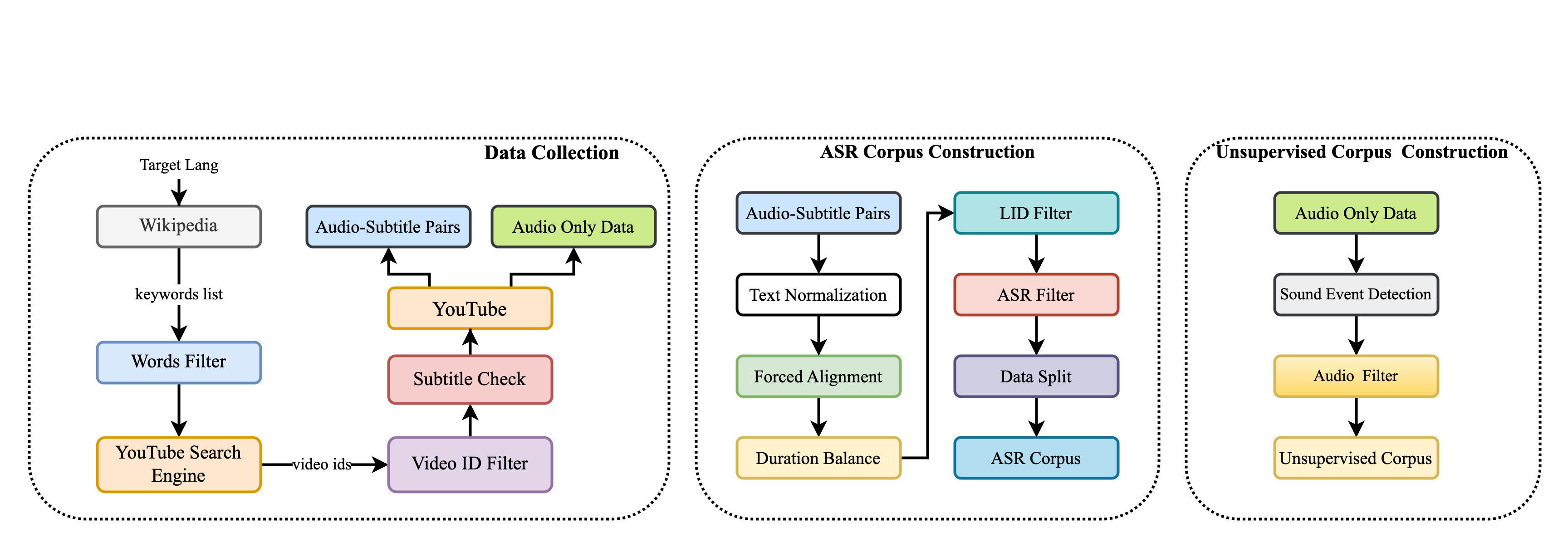
MSR-86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research
Song Li, Yongbin You, Xuezhi Wang, Zhengkun Tian, Ke Ding, Guanglu Wan
Recently, multilingual artificial intelligence assistants, exemplified by ChatGPT, have gained immense popularity. As a crucial gateway to human-computer interaction, multilingual automatic speech recognition (ASR) has also garnered significant attention, as evidenced by systems like Whisper. However, the proprietary nature of the training data has impeded researchers' efforts to study multilingual ASR. This paper introduces MSR-86K, an evolving, large-scale multilingual corpus for speech recognition research. The corpus is derived from publicly accessible videos on YouTube, comprising 15 languages and a total of 86,300 hours of transcribed ASR data. We also introduce how to use the MSR-86K corpus and other open-source corpora to train a robust multilingual ASR model that is competitive with Whisper. MSR-86K will be publicly released on HuggingFace, and we believe that such a large corpus will pave new avenues for research in multilingual ASR.
Read more6/27/2024