WenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark

0

Sign in to get full access
Overview
- The paper introduces the WenetSpeech4TTS dataset, a 12,800-hour Mandarin speech corpus for training large text-to-speech (TTS) models.
- The dataset is gathered from a variety of online sources and processed through a pipeline to ensure high-quality audio and transcripts.
- The goal of the dataset is to serve as a benchmark for evaluating the performance of large-scale Mandarin TTS models.
Plain English Explanation
The researchers have created a very large dataset of Mandarin speech, totaling 12,800 hours, to help develop and test advanced text-to-speech (TTS) systems. TTS is the technology that allows computers to convert written text into spoken audio.
The researchers gathered this massive dataset from various online sources, such as audiobooks, podcasts, and other audio recordings. They then processed the audio and transcripts to ensure high quality and consistency. This involved tasks like cleaning up the audio, aligning the text with the speech, and removing any errors or inconsistencies.
The goal is for this dataset to serve as a benchmark - a common dataset that can be used to evaluate and compare the performance of different Mandarin TTS models. By having a large, high-quality dataset to test on, researchers and companies can more accurately measure the capabilities of their TTS systems and identify areas for improvement.
This is important because as TTS technology becomes more sophisticated, having a robust evaluation dataset is crucial. The larger Mandarin speech datasets and advances in meta-learning for TTS make it possible to create TTS systems that can generate more natural, expressive speech. But to truly assess these capabilities, you need a dataset large and diverse enough to put the models through their paces.
Technical Explanation
The researchers collected the WenetSpeech4TTS dataset from a variety of online sources, including audiobooks, podcasts, and other audio recordings. The total dataset size is 12,800 hours of Mandarin speech data.
To process the raw audio and text data into a usable format, the researchers followed a multi-step pipeline:
- Audio preprocessing: The audio was cleaned and normalized to ensure consistent quality.
- Voice activity detection: Segments of speech were identified and extracted from the audio.
- Text-audio alignment: The text transcripts were aligned with the corresponding audio segments using forced alignment techniques.
- Quality control: The dataset was filtered to remove low-quality or erroneous samples, based on acoustic and linguistic metrics.
The resulting WenetSpeech4TTS dataset contains high-quality Mandarin speech data with aligned text transcripts. The researchers envision this dataset serving as a benchmark for evaluating the performance of large-scale Mandarin TTS models, similar to how the SEED-TTS dataset has been used for Cantonese and Taiwanese Mandarin TTS.
Critical Analysis
The WenetSpeech4TTS dataset is an impressive achievement, providing a massive amount of high-quality Mandarin speech data for TTS research. The large scale and diversity of the dataset are key strengths, as they allow for the development of TTS models that can handle a wide range of speakers, styles, and domains.
However, the paper does not address some potential limitations of the dataset. For example, it's unclear how the dataset's demographic and linguistic coverage compares to the actual Mandarin-speaking population. The dataset may be biased towards certain accents, registers, or genres, which could impact the generalizability of TTS models trained on it.
Additionally, the paper does not provide much detail on the quality control measures used to filter out low-quality samples. It would be helpful to have more information on the specific criteria and thresholds employed, as well as the overall quality and consistency of the dataset.
Further research could also explore the potential of combining this dataset with other Mandarin speech resources, such as the Advancing Speech Translation Corpus for Mandarin-English Conversational Speech or the StoryTTS dataset, to create even more diverse and representative benchmarks for Mandarin TTS.
Conclusion
The WenetSpeech4TTS dataset represents a significant contribution to the field of Mandarin text-to-speech research. By providing a large, high-quality dataset for model training and evaluation, the researchers have laid the groundwork for the development of more sophisticated and versatile Mandarin TTS systems.
As advances in meta-learning for TTS and frameworks for text-dependent speaker verification continue to push the boundaries of speech synthesis, datasets like WenetSpeech4TTS will be essential for benchmarking and driving progress in this important area of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
WenetSpeech4TTS: A 12,800-hour Mandarin TTS Corpus for Large Speech Generation Model Benchmark
Linhan Ma, Dake Guo, Kun Song, Yuepeng Jiang, Shuai Wang, Liumeng Xue, Weiming Xu, Huan Zhao, Binbin Zhang, Lei Xie
With the development of large text-to-speech (TTS) models and scale-up of the training data, state-of-the-art TTS systems have achieved impressive performance. In this paper, we present WenetSpeech4TTS, a multi-domain Mandarin corpus derived from the open-sourced WenetSpeech dataset. Tailored for the text-to-speech tasks, we refined WenetSpeech by adjusting segment boundaries, enhancing the audio quality, and eliminating speaker mixing within each segment. Following a more accurate transcription process and quality-based data filtering process, the obtained WenetSpeech4TTS corpus contains $12,800$ hours of paired audio-text data. Furthermore, we have created subsets of varying sizes, categorized by segment quality scores to allow for TTS model training and fine-tuning. VALL-E and NaturalSpeech 2 systems are trained and fine-tuned on these subsets to validate the usability of WenetSpeech4TTS, establishing baselines on benchmark for fair comparison of TTS systems. The corpus and corresponding benchmarks are publicly available on huggingface.
Read more6/21/2024
🗣️
0
Advancing Speech Translation: A Corpus of Mandarin-English Conversational Telephone Speech
Shannon Wotherspoon, William Hartmann, Matthew Snover
This paper introduces a set of English translations for a 123-hour subset of the CallHome Mandarin Chinese data and the HKUST Mandarin Telephone Speech data for the task of speech translation. Paired source-language speech and target-language text is essential for training end-to-end speech translation systems and can provide substantial performance improvements for cascaded systems as well, relative to training on more widely available text data sets. We demonstrate that fine-tuning a general-purpose translation model to our Mandarin-English conversational telephone speech training set improves target-domain BLEU by more than 8 points, highlighting the importance of matched training data.
Read more4/19/2024

0
ManaTTS Persian: a recipe for creating TTS datasets for lower resource languages
Mahta Fetrat Qharabagh, Zahra Dehghanian, Hamid R. Rabiee
In this study, we introduce ManaTTS, the most extensive publicly accessible single-speaker Persian corpus, and a comprehensive framework for collecting transcribed speech datasets for the Persian language. ManaTTS, released under the open CC-0 license, comprises approximately 86 hours of audio with a sampling rate of 44.1 kHz. Alongside ManaTTS, we also generated the VirgoolInformal dataset to evaluate Persian speech recognition models used for forced alignment, extending over 5 hours of audio. The datasets are supported by a fully transparent, MIT-licensed pipeline, a testament to innovation in the field. It includes unique tools for sentence tokenization, bounded audio segmentation, and a novel forced alignment method. This alignment technique is specifically designed for low-resource languages, addressing a crucial need in the field. With this dataset, we trained a Tacotron2-based TTS model, achieving a Mean Opinion Score (MOS) of 3.76, which is remarkably close to the MOS of 3.86 for the utterances generated by the same vocoder and natural spectrogram, and the MOS of 4.01 for the natural waveform, demonstrating the exceptional quality and effectiveness of the corpus.
Read more9/12/2024
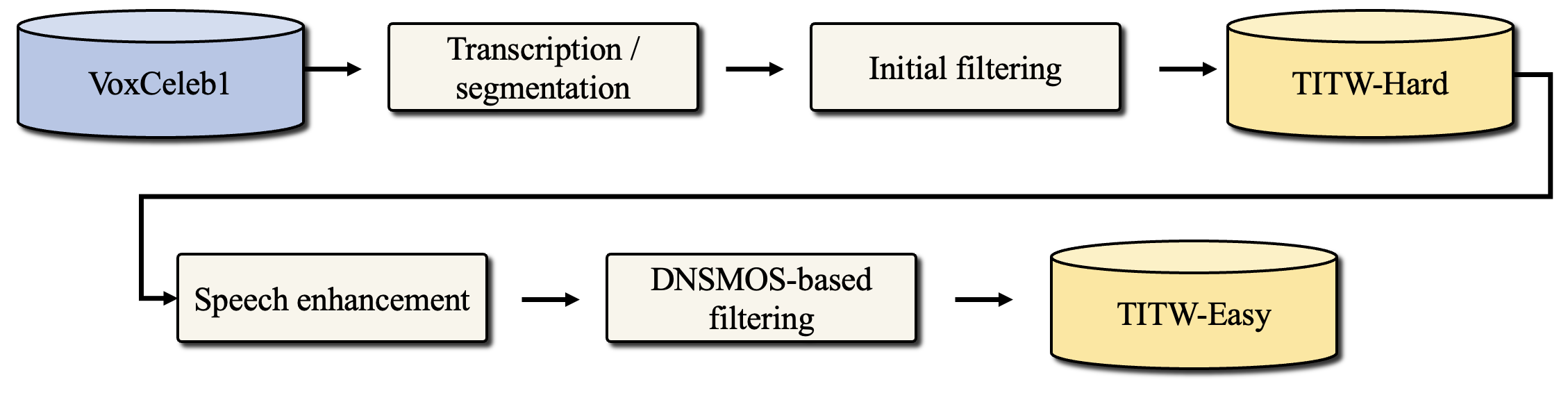
0
Text-To-Speech Synthesis In The Wild
Jee-weon Jung, Wangyou Zhang, Soumi Maiti, Yihan Wu, Xin Wang, Ji-Hoon Kim, Yuta Matsunaga, Seyun Um, Jinchuan Tian, Hye-jin Shim, Nicholas Evans, Joon Son Chung, Shinnosuke Takamichi, Shinji Watanabe
Text-to-speech (TTS) systems are traditionally trained using modest databases of studio-quality, prompted or read speech collected in benign acoustic environments such as anechoic rooms. The recent literature nonetheless shows efforts to train TTS systems using data collected in the wild. While this approach allows for the use of massive quantities of natural speech, until now, there are no common datasets. We introduce the TTS In the Wild (TITW) dataset, the result of a fully automated pipeline, in this case, applied to the VoxCeleb1 dataset commonly used for speaker recognition. We further propose two training sets. TITW-Hard is derived from the transcription, segmentation, and selection of VoxCeleb1 source data. TITW-Easy is derived from the additional application of enhancement and additional data selection based on DNSMOS. We show that a number of recent TTS models can be trained successfully using TITW-Easy, but that it remains extremely challenging to produce similar results using TITW-Hard. Both the dataset and protocols are publicly available and support the benchmarking of TTS systems trained using TITW data.
Read more9/16/2024