Adversarial Machine Unlearning

0
Sign in to get full access
Overview
- This paper introduces a new approach called "adversarial machine unlearning" to remove specific data from a machine learning model in a secure and verifiable way.
- The authors propose a framework that can effectively remove the influence of targeted data from a trained model, while preserving the model's performance on the remaining data.
- They demonstrate the efficacy of their approach through experiments on various datasets and machine learning tasks, showing significant advantages over existing unlearning techniques.
Plain English Explanation
The paper explores a technique called "adversarial machine unlearning" that allows researchers to remove specific data from a machine learning model in a reliable and verifiable way. This is important because sometimes organizations or individuals may need to remove certain data from a model, for example, if the data is found to be biased or inaccurate.
The authors' framework works by identifying the parts of the model that are influenced by the targeted data and then actively "unlearning" that information, while preserving the model's overall performance on the remaining data. This is done through a process that is designed to be secure and transparent, so that the changes made to the model can be verified.
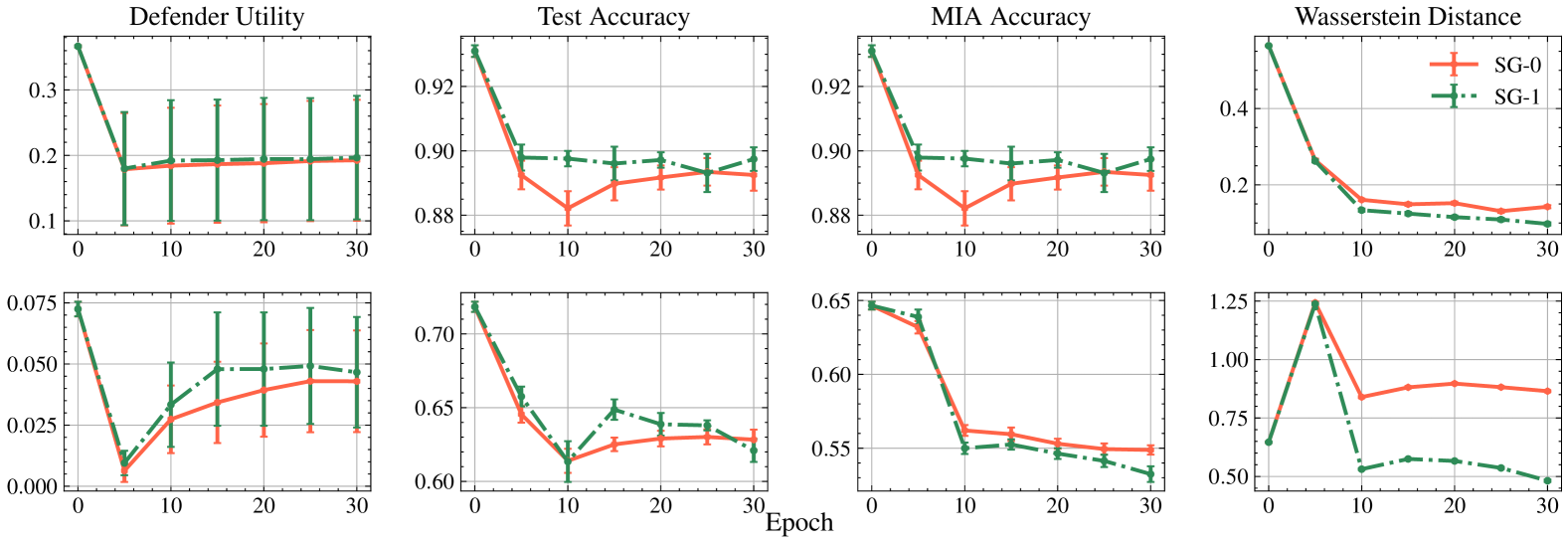
The researchers tested their approach on various datasets and machine learning tasks, and found that it outperformed existing unlearning techniques in terms of effectively removing the targeted data while maintaining the model's accuracy on the other data.
Technical Explanation
The paper introduces an "adversarial machine unlearning" framework that can effectively remove the influence of targeted data from a trained machine learning model. The key idea is to leverage adversarial training to identify the parts of the model that are most influenced by the targeted data, and then actively "unlearn" that information while preserving the model's performance on the remaining data.
Specifically, the authors propose an optimization problem that simultaneously minimizes the model's loss on the remaining data and maximizes the model's loss on the targeted data. This encourages the model to adapt in a way that reduces its reliance on the targeted data, without significantly degrading its overall performance.
The authors evaluate their approach on various datasets and tasks, including image classification, text classification, and tabular data prediction. They compare their method to existing unlearning techniques, such as Towards Reliable Empirical Machine Unlearning Evaluation, Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning, and Inexact Unlearning Needs More Careful Evaluations to Avoid Misleading Conclusions. The results show that their adversarial unlearning approach significantly outperforms these baselines in terms of effectively removing the targeted data while preserving the model's overall performance.
Critical Analysis
The paper presents a novel and promising approach to machine unlearning, but there are a few potential limitations and areas for further research:
-
Scalability: The authors demonstrate their method on relatively small-scale datasets and models. It's unclear how well the approach would scale to larger, more complex machine learning models, such as large language models.
-
Theoretical Guarantees: The paper does not provide any theoretical guarantees or bounds on the effectiveness of the adversarial unlearning process. A more rigorous theoretical analysis could help better understand the properties and limitations of the approach.
-
Real-World Applicability: The paper focuses on a controlled, synthetic setting where the targeted data is known in advance. In real-world scenarios, it may be more challenging to identify the specific data that needs to be removed, and the approach may need to be adapted accordingly.
-
Interpretability: While the paper demonstrates the effectiveness of the adversarial unlearning approach, it does not provide much insight into the internal workings of the process and how the model is actually being "unlearned." Improving the interpretability of the method could help users understand and trust the unlearning process.
Despite these potential limitations, the paper presents an important and innovative contribution to the field of machine unlearning, which is a critical area of research for ensuring the ethical and responsible deployment of machine learning systems.
Conclusion
This paper introduces a novel "adversarial machine unlearning" framework that can effectively remove the influence of targeted data from a trained machine learning model, while preserving the model's overall performance. The authors demonstrate the efficacy of their approach through extensive experiments on various datasets and tasks, showing significant advantages over existing unlearning techniques.
The proposed method represents an important step forward in the field of machine unlearning, which is crucial for ensuring the responsible and ethical use of machine learning systems. While the paper has some potential limitations, it opens up new avenues for further research and development in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adversarial Machine Unlearning
Zonglin Di, Sixie Yu, Yevgeniy Vorobeychik, Yang Liu
This paper focuses on the challenge of machine unlearning, aiming to remove the influence of specific training data on machine learning models. Traditionally, the development of unlearning algorithms runs parallel with that of membership inference attacks (MIA), a type of privacy threat to determine whether a data instance was used for training. However, the two strands are intimately connected: one can view machine unlearning through the lens of MIA success with respect to removed data. Recognizing this connection, we propose a game-theoretic framework that integrates MIAs into the design of unlearning algorithms. Specifically, we model the unlearning problem as a Stackelberg game in which an unlearner strives to unlearn specific training data from a model, while an auditor employs MIAs to detect the traces of the ostensibly removed data. Adopting this adversarial perspective allows the utilization of new attack advancements, facilitating the design of unlearning algorithms. Our framework stands out in two ways. First, it takes an adversarial approach and proactively incorporates the attacks into the design of unlearning algorithms. Secondly, it uses implicit differentiation to obtain the gradients that limit the attacker's success, thus benefiting the process of unlearning. We present empirical results to demonstrate the effectiveness of the proposed approach for machine unlearning.
Read more6/13/2024
0
Towards Reliable Empirical Machine Unlearning Evaluation: A Game-Theoretic View
Yiwen Tu, Pingbang Hu, Jiaqi Ma
Machine unlearning is the process of updating machine learning models to remove the information of specific training data samples, in order to comply with data protection regulations that allow individuals to request the removal of their personal data. Despite the recent development of numerous unlearning algorithms, reliable evaluation of these algorithms remains an open research question. In this work, we focus on membership inference attack (MIA) based evaluation, one of the most common approaches for evaluating unlearning algorithms, and address various pitfalls of existing evaluation metrics that lack reliability. Specifically, we propose a game-theoretic framework that formalizes the evaluation process as a game between unlearning algorithms and MIA adversaries, measuring the data removal efficacy of unlearning algorithms by the capability of the MIA adversaries. Through careful design of the game, we demonstrate that the natural evaluation metric induced from the game enjoys provable guarantees that the existing evaluation metrics fail to satisfy. Furthermore, we propose a practical and efficient algorithm to estimate the evaluation metric induced from the game, and demonstrate its effectiveness through both theoretical analysis and empirical experiments. This work presents a novel and reliable approach to empirically evaluating unlearning algorithms, paving the way for the development of more effective unlearning techniques.
Read more6/13/2024

0
Gone but Not Forgotten: Improved Benchmarks for Machine Unlearning
Keltin Grimes, Collin Abidi, Cole Frank, Shannon Gallagher
Machine learning models are vulnerable to adversarial attacks, including attacks that leak information about the model's training data. There has recently been an increase in interest about how to best address privacy concerns, especially in the presence of data-removal requests. Machine unlearning algorithms aim to efficiently update trained models to comply with data deletion requests while maintaining performance and without having to resort to retraining the model from scratch, a costly endeavor. Several algorithms in the machine unlearning literature demonstrate some level of privacy gains, but they are often evaluated only on rudimentary membership inference attacks, which do not represent realistic threats. In this paper we describe and propose alternative evaluation methods for three key shortcomings in the current evaluation of unlearning algorithms. We show the utility of our alternative evaluations via a series of experiments of state-of-the-art unlearning algorithms on different computer vision datasets, presenting a more detailed picture of the state of the field.
Read more5/30/2024

0
Inexact Unlearning Needs More Careful Evaluations to Avoid a False Sense of Privacy
Jamie Hayes, Ilia Shumailov, Eleni Triantafillou, Amr Khalifa, Nicolas Papernot
The high cost of model training makes it increasingly desirable to develop techniques for unlearning. These techniques seek to remove the influence of a training example without having to retrain the model from scratch. Intuitively, once a model has unlearned, an adversary that interacts with the model should no longer be able to tell whether the unlearned example was included in the model's training set or not. In the privacy literature, this is known as membership inference. In this work, we discuss adaptations of Membership Inference Attacks (MIAs) to the setting of unlearning (leading to their U-MIA counterparts). We propose a categorization of existing U-MIAs into population U-MIAs, where the same attacker is instantiated for all examples, and per-example U-MIAs, where a dedicated attacker is instantiated for each example. We show that the latter category, wherein the attacker tailors its membership prediction to each example under attack, is significantly stronger. Indeed, our results show that the commonly used U-MIAs in the unlearning literature overestimate the privacy protection afforded by existing unlearning techniques on both vision and language models. Our investigation reveals a large variance in the vulnerability of different examples to per-example U-MIAs. In fact, several unlearning algorithms lead to a reduced vulnerability for some, but not all, examples that we wish to unlearn, at the expense of increasing it for other examples. Notably, we find that the privacy protection for the remaining training examples may worsen as a consequence of unlearning. We also discuss the fundamental difficulty of equally protecting all examples using existing unlearning schemes, due to the different rates at which examples are unlearned. We demonstrate that naive attempts at tailoring unlearning stopping criteria to different examples fail to alleviate these issues.
Read more5/22/2024