MuDPT: Multi-modal Deep-symphysis Prompt Tuning for Large Pre-trained Vision-Language Models

0

Sign in to get full access
Overview
- This paper introduces MuDPT, a novel approach for multi-modal deep-symphysis prompt tuning of large pre-trained vision-language models.
- MuDPT leverages both visual and textual input modalities to learn effective prompts that can be used to fine-tune these models for various downstream tasks.
- The key innovations include a multi-modal prompt fusion mechanism and a deep-symphysis training strategy that learns prompts at multiple levels of abstraction.
Plain English Explanation
The researchers have developed a new technique called MuDPT (Multi-modal Deep-symphysis Prompt Tuning) to help large AI models that can process both images and text become better at specific tasks. These models, known as vision-language models, are trained on a vast amount of online data to develop a general understanding of the world.
However, to use these models for a particular application, they need to be "fine-tuned" by training them on a smaller dataset relevant to that task. This fine-tuning process can be time-consuming and require a lot of task-specific data.
MuDPT aims to make this fine-tuning process more efficient by learning "prompts" - short pieces of text that can guide the model to produce the desired outputs for a given task. The key innovation in MuDPT is that it learns these prompts using both the visual and textual information available in the training data, rather than just the text alone.
This multi-modal prompt fusion allows the model to better understand the relationships between the visual and textual content, leading to more effective prompts. Additionally, MuDPT learns these prompts at multiple levels of abstraction, a technique the researchers call deep-symphysis prompt tuning.
The researchers demonstrate that MuDPT can outperform other prompt tuning approaches on a variety of benchmark tasks, making it a promising technique for efficiently fine-tuning large vision-language models for real-world applications.
Technical Explanation
The MuDPT approach leverages both visual and textual input modalities to learn effective prompts for fine-tuning large pre-trained vision-language models. The key innovations include:
-
Multi-modal Prompt Fusion: Instead of using text-only prompts, MuDPT learns prompts that fuse information from both the visual and textual inputs. This multi-modal prompt fusion allows the model to better capture the relationships between the visual and textual content, leading to more effective prompts.
-
Deep-symphysis Prompt Tuning: MuDPT learns prompts at multiple levels of abstraction, from low-level visual and textual features to higher-level semantic representations. This deep-symphysis prompt tuning strategy allows the model to capture prompts that are both specific and generalizable.
The MuDPT architecture consists of a backbone vision-language model, a multi-modal prompt encoder, and a task-specific head. The prompt encoder takes in both visual and textual inputs and generates a multi-modal prompt, which is then used to condition the backbone model's outputs for the target task.
The researchers evaluate MuDPT on a variety of benchmark tasks, including image captioning, visual question answering, and multimodal classification. They show that MuDPT outperforms other prompt tuning approaches, such as DeCoopT and DualPT, as well as fine-tuning the entire backbone model.
Critical Analysis
The MuDPT approach presents several promising advancements in prompt tuning for large vision-language models. The multi-modal prompt fusion and deep-symphysis prompt tuning strategies are well-justified and demonstrate the benefits of leveraging both visual and textual information during the prompt learning process.
However, the paper does not delve into the potential limitations or caveats of the MuDPT approach. For example, it would be valuable to understand how MuDPT performs in low-resource settings or on out-of-distribution data, as these are common challenges in real-world applications of these models.
Additionally, the paper could have explored the patch-prompt alignment and Bayesian prompt tuning techniques, which have also shown promise in improving the performance and robustness of prompt-based fine-tuning.
Overall, the MuDPT approach is a compelling contribution to the field of prompt tuning for vision-language models, but further research is needed to fully understand its strengths, limitations, and potential for broader applicability.
Conclusion
The MuDPT paper introduces a novel multi-modal prompt tuning technique that leverages both visual and textual inputs to learn effective prompts for fine-tuning large pre-trained vision-language models. The key innovations, including multi-modal prompt fusion and deep-symphysis prompt tuning, demonstrate the benefits of a more holistic approach to prompt learning.
The empirical results show that MuDPT can outperform other prompt tuning methods and even full model fine-tuning on a variety of benchmark tasks, suggesting that it is a promising technique for efficiently adapting these powerful models to specific applications. While the paper does not explore the potential limitations of the approach, the overall contribution represents an important step forward in the field of prompt-based fine-tuning for vision-language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MuDPT: Multi-modal Deep-symphysis Prompt Tuning for Large Pre-trained Vision-Language Models
Yongzhu Miao, Shasha Li, Jintao Tang, Ting Wang
Prompt tuning, like CoOp, has recently shown promising vision recognizing and transfer learning ability on various downstream tasks with the emergence of large pre-trained vision-language models like CLIP. However, we identify that existing uni-modal prompt tuning approaches may result in sub-optimal performance since this uni-modal design breaks the original alignment of textual and visual representations in the pre-trained model. Inspired by the nature of pre-trained vision-language models, we aim to achieve completeness in prompt tuning and propose a novel approach called Multi-modal Deep-symphysis Prompt Tuning, dubbed as MuDPT, which extends independent multi-modal prompt tuning by additionally learning a model-agnostic transformative network to allow deep hierarchical bi-directional prompt fusion. We evaluate the effectiveness of MuDPT on few-shot vision recognition and out-of-domain generalization tasks. Compared with the state-of-the-art methods, MuDPT achieves better recognition and generalization ability with an apparent margin thanks to synergistic alignment of textual and visual representations. Our code is available at: https://github.com/Mechrev0/MuDPT.
Read more7/16/2024

0
SDPT: Synchronous Dual Prompt Tuning for Fusion-based Visual-Language Pre-trained Models
Yang Zhou, Yongjian Wu, Jiya Saiyin, Bingzheng Wei, Maode Lai, Eric Chang, Yan Xu
Prompt tuning methods have achieved remarkable success in parameter-efficient fine-tuning on large pre-trained models. However, their application to dual-modal fusion-based visual-language pre-trained models (VLPMs), such as GLIP, has encountered issues. Existing prompt tuning methods have not effectively addressed the modal mapping and aligning problem for tokens in different modalities, leading to poor transfer generalization. To address this issue, we propose Synchronous Dual Prompt Tuning (SDPT). SDPT initializes a single set of learnable unified prototype tokens in the established modal aligning space to represent the aligned semantics of text and image modalities for downstream tasks. Furthermore, SDPT establishes inverse linear projections that require no training to embed the information of unified prototype tokens into the input space of different modalities. The inverse linear projections allow the unified prototype token to synchronously represent the two modalities and enable SDPT to share the unified semantics of text and image for downstream tasks across different modal prompts. Experimental results demonstrate that SDPT assists fusion-based VLPMs to achieve superior outcomes with only 0.04% of model parameters for training across various scenarios, outperforming other single- or dual-modal methods. The code will be released at https://github.com/wuyongjianCODE/SDPT.
Read more7/17/2024
🌿
0
Adversarial Prompt Tuning for Vision-Language Models
Jiaming Zhang, Xingjun Ma, Xin Wang, Lingyu Qiu, Jiaqi Wang, Yu-Gang Jiang, Jitao Sang
With the rapid advancement of multimodal learning, pre-trained Vision-Language Models (VLMs) such as CLIP have demonstrated remarkable capacities in bridging the gap between visual and language modalities. However, these models remain vulnerable to adversarial attacks, particularly in the image modality, presenting considerable security risks. This paper introduces Adversarial Prompt Tuning (AdvPT), a novel technique to enhance the adversarial robustness of image encoders in VLMs. AdvPT innovatively leverages learnable text prompts and aligns them with adversarial image embeddings, to address the vulnerabilities inherent in VLMs without the need for extensive parameter training or modification of the model architecture. We demonstrate that AdvPT improves resistance against white-box and black-box adversarial attacks and exhibits a synergistic effect when combined with existing image-processing-based defense techniques, further boosting defensive capabilities. Comprehensive experimental analyses provide insights into adversarial prompt tuning, a novel paradigm devoted to improving resistance to adversarial images through textual input modifications, paving the way for future robust multimodal learning research. These findings open up new possibilities for enhancing the security of VLMs. Our code is available at https://github.com/jiamingzhang94/Adversarial-Prompt-Tuning.
Read more8/20/2024
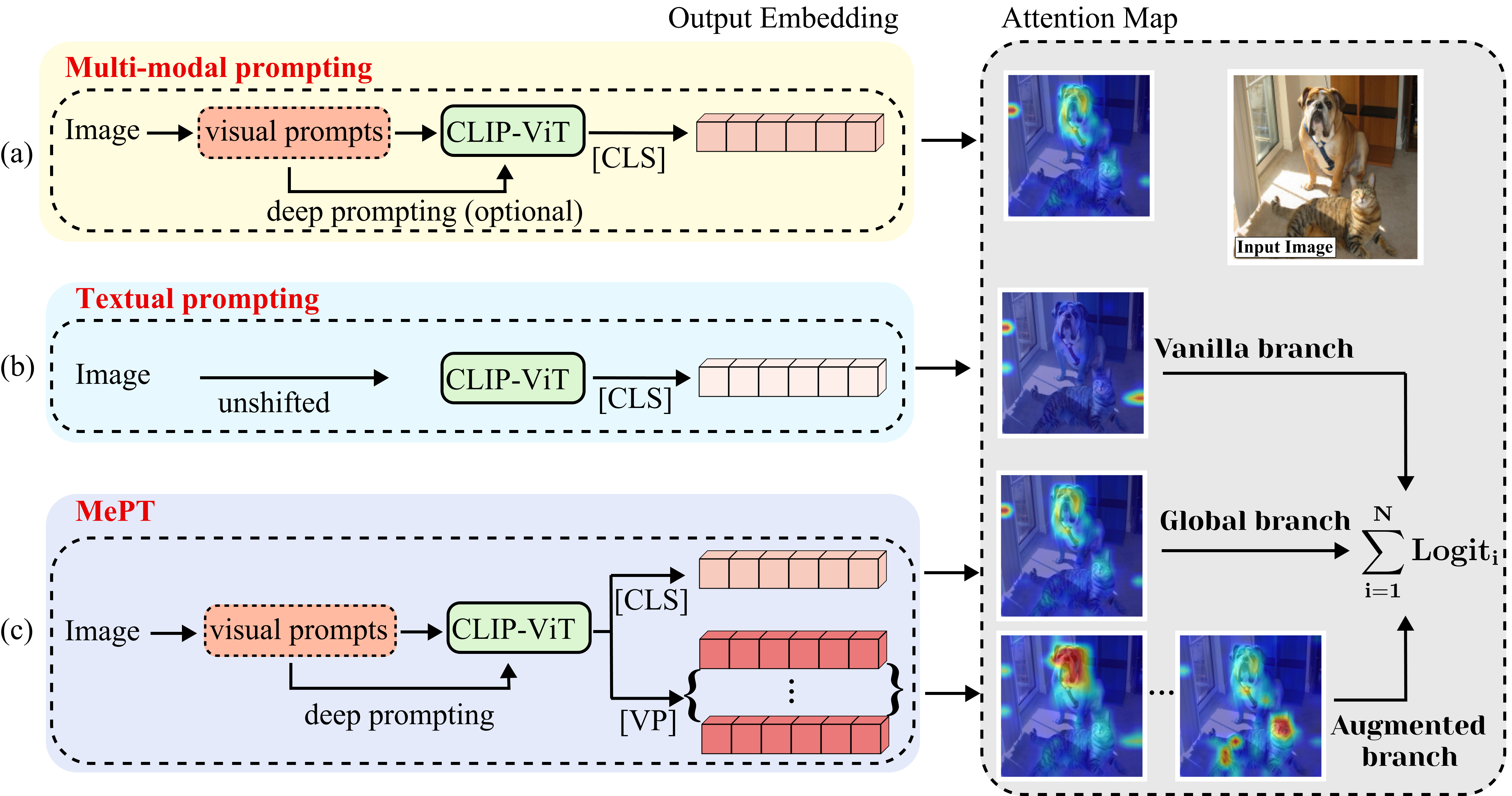
0
MePT: Multi-Representation Guided Prompt Tuning for Vision-Language Model
Xinyang Wang, Yi Yang, Minfeng Zhu, Kecheng Zheng, Shi Liu, Wei Chen
Recent advancements in pre-trained Vision-Language Models (VLMs) have highlighted the significant potential of prompt tuning for adapting these models to a wide range of downstream tasks. However, existing prompt tuning methods typically map an image to a single representation, limiting the model's ability to capture the diverse ways an image can be described. To address this limitation, we investigate the impact of visual prompts on the model's generalization capability and introduce a novel method termed Multi-Representation Guided Prompt Tuning (MePT). Specifically, MePT employs a three-branch framework that focuses on diverse salient regions, uncovering the inherent knowledge within images which is crucial for robust generalization. Further, we employ efficient self-ensemble techniques to integrate these versatile image representations, allowing MePT to learn all conditional, marginal, and fine-grained distributions effectively. We validate the effectiveness of MePT through extensive experiments, demonstrating significant improvements on both base-to-novel class prediction and domain generalization tasks.
Read more8/20/2024