Adversarial Search Engine Optimization for Large Language Models
2406.18382
0
0

Abstract
Large Language Models (LLMs) are increasingly used in applications where the model selects from competing third-party content, such as in LLM-powered search engines or chatbot plugins. In this paper, we introduce Preference Manipulation Attacks, a new class of attacks that manipulate an LLM's selections to favor the attacker. We demonstrate that carefully crafted website content or plugin documentations can trick an LLM to promote the attacker products and discredit competitors, thereby increasing user traffic and monetization. We show this leads to a prisoner's dilemma, where all parties are incentivized to launch attacks, but the collective effect degrades the LLM's outputs for everyone. We demonstrate our attacks on production LLM search engines (Bing and Perplexity) and plugin APIs (for GPT-4 and Claude). As LLMs are increasingly used to rank third-party content, we expect Preference Manipulation Attacks to emerge as a significant threat.
Create account to get full access
Overview
- This paper explores how large language models (LLMs) like GPT-3 can be manipulated using adversarial search engine optimization (SEO) techniques.
- The researchers demonstrate various attack methods that can be used to hijack the rankings of LLMs in conversational search engines, making them more likely to return adversarial content.
- The findings highlight the potential vulnerability of LLMs to targeted attacks and the importance of developing robust defenses to maintain the integrity of these powerful AI systems.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful AI systems that can generate human-like text on a wide range of topics. These models are often used in conversational search engines, where they can provide detailed and nuanced responses to user queries.
However, the researchers of this paper have discovered that LLMs can be manipulated using adversarial SEO techniques. By crafting carefully designed inputs, they were able to influence the rankings of LLMs in conversational search engines, making them more likely to return adversarial content.
For example, an attacker could create content that appears to be authoritative and trustworthy, but actually contains misinformation or propaganda. By optimizing this content for the LLM's ranking algorithms, the attacker could increase the chances of the LLM recommending this content to users.
The researchers demonstrate several different attack methods, each with their own unique approach and level of effectiveness. These attacks highlight the potential vulnerability of LLMs to targeted manipulation, and the importance of developing robust defenses to protect these systems from abuse.
Overall, this research underscores the need for continued vigilance and innovation in the field of AI safety. As LLMs become more prevalent in our daily lives, it is crucial that we understand their limitations and weaknesses, and work to address them before they can be exploited for malicious purposes.
Technical Explanation
The paper introduces the concept of adversarial SEO for large language models, which refers to the use of targeted techniques to manipulate the rankings of LLMs in conversational search engines.
The researchers describe several different attack methods, including:
- Adversarial evasion attacks that can bypass the LLM's defenses and influence its outputs.
- Sandwich attacks that combine multiple languages and adaptive techniques to further enhance the effectiveness of the attacks.
- Vocabulary attacks that target the LLM's internal language model to hijack its rankings.
The researchers conducted extensive experiments to evaluate the performance of these attack methods, using a range of metrics to assess their effectiveness and robustness. Their findings demonstrate that these adversarial SEO techniques can significantly impact the rankings and outputs of LLMs in conversational search engines.
The paper also includes a discussion of the potential implications and limitations of this research, as well as suggestions for future work in this area.
Critical Analysis
The researchers have done an impressive job of demonstrating the vulnerability of LLMs to adversarial SEO techniques. Their work highlights the importance of developing robust defenses to protect these powerful AI systems from manipulation and abuse.
However, the paper also raises some important questions and concerns. For example, the researchers acknowledge that their attack methods may have unintended consequences, such as the potential to spread misinformation or undermine the credibility of LLMs. It will be crucial for the research community to carefully consider these ethical implications and work to mitigate any negative impacts.
Additionally, the paper focuses primarily on the technical aspects of the attacks, without delving too deeply into the broader societal implications. As LLMs become more prevalent in our daily lives, it will be important to consider the wider ramifications of these vulnerabilities, such as their impact on public discourse, decision-making, and trust in AI systems.
Overall, this research represents an important contribution to the field of AI safety and security. By shedding light on the potential weaknesses of LLMs, the authors have laid the groundwork for the development of more robust and resilient AI systems that can withstand adversarial attacks. However, there is still much work to be done to ensure the long-term integrity and trustworthiness of these technologies.
Conclusion
The researchers have demonstrated that large language models (LLMs) like GPT-3 can be vulnerable to adversarial search engine optimization (SEO) techniques, which can be used to manipulate the rankings and outputs of these powerful AI systems in conversational search engines.
The findings of this paper highlight the importance of developing robust defenses to protect LLMs from targeted attacks and maintain the integrity of these technologies. As LLMs become more prevalent in our daily lives, it will be crucial to address these vulnerabilities and ensure that these AI systems are not exploited for malicious purposes.
While the technical details of the researchers' work are complex, the implications of their findings are far-reaching and have the potential to shape the future of AI development and deployment. By continuing to explore these issues and work towards solutions, the research community can help ensure that the transformative power of LLMs is harnessed in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Ranking Manipulation for Conversational Search Engines
Samuel Pfrommer, Yatong Bai, Tanmay Gautam, Somayeh Sojoudi
0
0
Major search engine providers are rapidly incorporating Large Language Model (LLM)-generated content in response to user queries. These conversational search engines operate by loading retrieved website text into the LLM context for summarization and interpretation. Recent research demonstrates that LLMs are highly vulnerable to jailbreaking and prompt injection attacks, which disrupt the safety and quality goals of LLMs using adversarial strings. This work investigates the impact of prompt injections on the ranking order of sources referenced by conversational search engines. To this end, we introduce a focused dataset of real-world consumer product websites and formalize conversational search ranking as an adversarial problem. Experimentally, we analyze conversational search rankings in the absence of adversarial injections and show that different LLMs vary significantly in prioritizing product name, document content, and context position. We then present a tree-of-attacks-based jailbreaking technique which reliably promotes low-ranked products. Importantly, these attacks transfer effectively to state-of-the-art conversational search engines such as perplexity.ai. Given the strong financial incentive for website owners to boost their search ranking, we argue that our problem formulation is of critical importance for future robustness work.
6/14/2024
💬
Adversarial Evasion Attack Efficiency against Large Language Models
Jo~ao Vitorino, Eva Maia, Isabel Prac{c}a
0
0
Large Language Models (LLMs) are valuable for text classification, but their vulnerabilities must not be disregarded. They lack robustness against adversarial examples, so it is pertinent to understand the impacts of different types of perturbations, and assess if those attacks could be replicated by common users with a small amount of perturbations and a small number of queries to a deployed LLM. This work presents an analysis of the effectiveness, efficiency, and practicality of three different types of adversarial attacks against five different LLMs in a sentiment classification task. The obtained results demonstrated the very distinct impacts of the word-level and character-level attacks. The word attacks were more effective, but the character and more constrained attacks were more practical and required a reduced number of perturbations and queries. These differences need to be considered during the development of adversarial defense strategies to train more robust LLMs for intelligent text classification applications.
6/13/2024
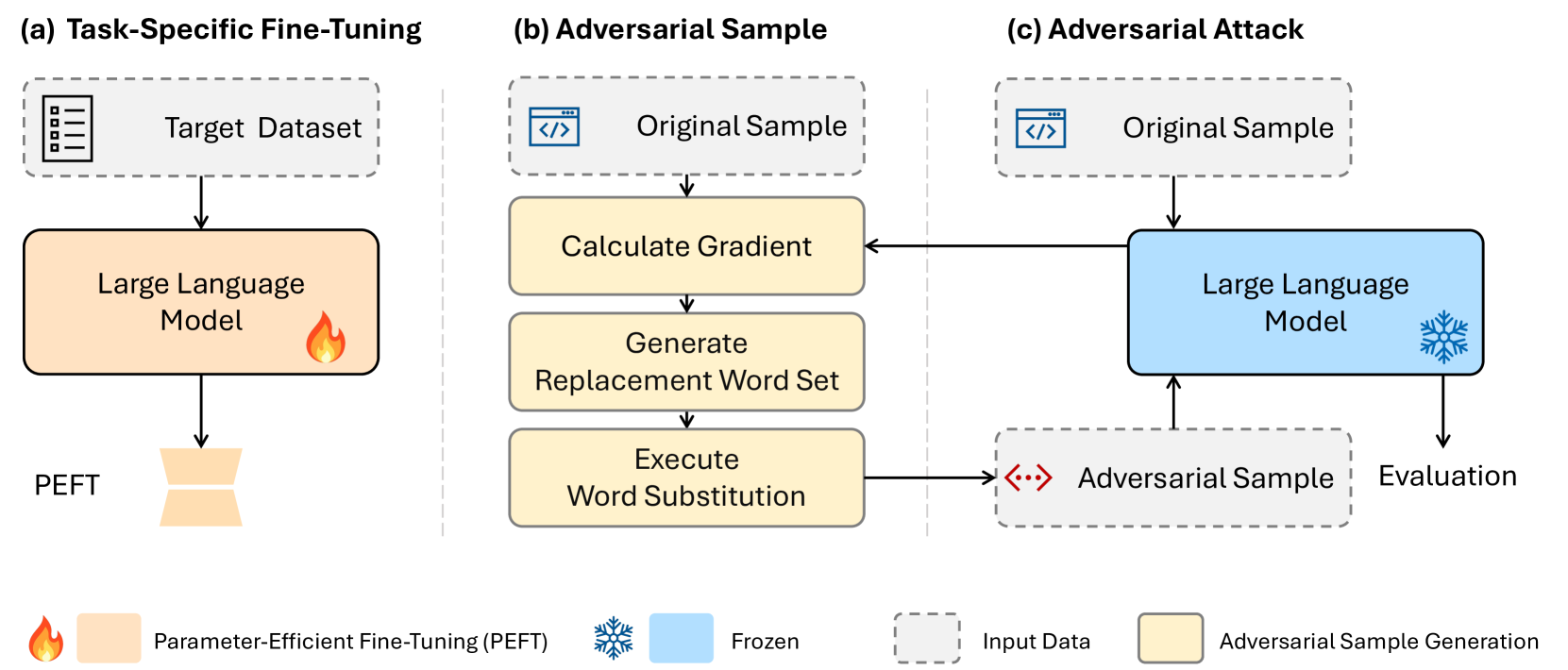
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
Zeyu Yang, Zhao Meng, Xiaochen Zheng, Roger Wattenhofer
0
0
Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
5/7/2024

Sandwich attack: Multi-language Mixture Adaptive Attack on LLMs
Bibek Upadhayay, Vahid Behzadan
0
0
Large Language Models (LLMs) are increasingly being developed and applied, but their widespread use faces challenges. These include aligning LLMs' responses with human values to prevent harmful outputs, which is addressed through safety training methods. Even so, bad actors and malicious users have succeeded in attempts to manipulate the LLMs to generate misaligned responses for harmful questions such as methods to create a bomb in school labs, recipes for harmful drugs, and ways to evade privacy rights. Another challenge is the multilingual capabilities of LLMs, which enable the model to understand and respond in multiple languages. Consequently, attackers exploit the unbalanced pre-training datasets of LLMs in different languages and the comparatively lower model performance in low-resource languages than high-resource ones. As a result, attackers use a low-resource languages to intentionally manipulate the model to create harmful responses. Many of the similar attack vectors have been patched by model providers, making the LLMs more robust against language-based manipulation. In this paper, we introduce a new black-box attack vector called the emph{Sandwich attack}: a multi-language mixture attack, which manipulates state-of-the-art LLMs into generating harmful and misaligned responses. Our experiments with five different models, namely Google's Bard, Gemini Pro, LLaMA-2-70-B-Chat, GPT-3.5-Turbo, GPT-4, and Claude-3-OPUS, show that this attack vector can be used by adversaries to generate harmful responses and elicit misaligned responses from these models. By detailing both the mechanism and impact of the Sandwich attack, this paper aims to guide future research and development towards more secure and resilient LLMs, ensuring they serve the public good while minimizing potential for misuse.
4/12/2024