$textit{LinkPrompt}$: Natural and Universal Adversarial Attacks on Prompt-based Language Models
2403.16432
0
0

Abstract
Prompt-based learning is a new language model training paradigm that adapts the Pre-trained Language Models (PLMs) to downstream tasks, which revitalizes the performance benchmarks across various natural language processing (NLP) tasks. Instead of using a fixed prompt template to fine-tune the model, some research demonstrates the effectiveness of searching for the prompt via optimization. Such prompt optimization process of prompt-based learning on PLMs also gives insight into generating adversarial prompts to mislead the model, raising concerns about the adversarial vulnerability of this paradigm. Recent studies have shown that universal adversarial triggers (UATs) can be generated to alter not only the predictions of the target PLMs but also the prediction of corresponding Prompt-based Fine-tuning Models (PFMs) under the prompt-based learning paradigm. However, UATs found in previous works are often unreadable tokens or characters and can be easily distinguished from natural texts with adaptive defenses. In this work, we consider the naturalness of the UATs and develop $textit{LinkPrompt}$, an adversarial attack algorithm to generate UATs by a gradient-based beam search algorithm that not only effectively attacks the target PLMs and PFMs but also maintains the naturalness among the trigger tokens. Extensive results demonstrate the effectiveness of $textit{LinkPrompt}$, as well as the transferability of UATs generated by $textit{LinkPrompt}$ to open-sourced Large Language Model (LLM) Llama2 and API-accessed LLM GPT-3.5-turbo. The resource is available at $href{https://github.com/SavannahXu79/LinkPrompt}{https://github.com/SavannahXu79/LinkPrompt}$.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces LinkPrompt, a novel technique for creating natural and universal adversarial attacks on prompt-based language models.
- Prompt-based models are a type of large language model that can be fine-tuned for various tasks by providing specific prompts.
- The researchers demonstrate how LinkPrompt can be used to generate adversarial examples that can fool these models across a range of tasks, even without access to the model's internals.
Plain English Explanation
Prompt-based language models are a type of AI system that can be trained to perform different tasks by providing them with specific "prompts" - instructions or context that guide the model's output. For example, you could prompt a model to write a creative story, answer a question, or summarize a passage of text.
The researchers in this paper show how they were able to create "adversarial attacks" that can trick these prompt-based models into producing incorrect or undesirable outputs. They developed a technique called LinkPrompt that can generate prompts designed to mislead the models, even without knowing the internal details of how the models work.
This is an important finding because it highlights a potential vulnerability in these types of language models. While prompt-based models can be very capable, the researchers demonstrate that they may also be susceptible to carefully crafted adversarial attacks that could undermine their reliability and trustworthiness in real-world applications.
Technical Explanation
The core idea behind LinkPrompt is to automatically generate prompts that, when provided to a prompt-based language model, will cause the model to produce an incorrect or undesirable output. To do this, the researchers leverage large language models that have been trained on massive amounts of text data.
They start by identifying a set of "anchor prompts" - prompts that reliably elicit a specific, known output from the target language model. They then use these anchor prompts as a starting point to search for adversarial prompts - slight variations on the original prompts that lead the model astray.
The key innovation in LinkPrompt is the use of a technique called "prompt chaining," where the researchers chain together multiple adversarial prompts to create a more natural-sounding, universal attack. This allows them to fool the model across a wide range of tasks, even without direct access to the model's internal architecture or training data.
The researchers evaluate LinkPrompt on several popular prompt-based language models and demonstrate its effectiveness at generating adversarial examples that can significantly degrade the models' performance on various benchmarks.
Critical Analysis
One limitation of this research is that it focuses primarily on demonstrating the feasibility of LinkPrompt as an attack technique, rather than exploring potential countermeasures or defenses. The paper acknowledges that further work is needed to develop robust strategies for detecting and mitigating these types of adversarial prompts.
Additionally, the researchers note that their approach relies on the availability of suitable anchor prompts, which may not always be easy to identify, especially for more complex or specialized language models. This could limit the broader applicability of the LinkPrompt technique.
It's also worth considering the ethical implications of this research. While the goal is to uncover vulnerabilities in prompt-based models, the techniques developed could potentially be misused by bad actors to deliberately mislead or deceive users of these AI systems. Responsible disclosure and further research into defensive strategies will be crucial as this area of study continues to evolve.
Conclusion
This paper introduces a novel technique called LinkPrompt that can generate natural and universal adversarial attacks on prompt-based language models. The researchers demonstrate the effectiveness of their approach across a range of tasks and models, highlighting a potential vulnerability in these types of AI systems.
While the findings are concerning, they also underscore the importance of continued research into the safety and robustness of large language models, especially as they become more widely deployed in real-world applications. As the use of prompt-based models continues to grow, it will be crucial to develop effective methods for prompt selection and evaluation to ensure the reliability and trustworthiness of these systems, even in the face of sophisticated adversarial attacks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
AdvPrompter: Fast Adaptive Adversarial Prompting for LLMs
Anselm Paulus, Arman Zharmagambetov, Chuan Guo, Brandon Amos, Yuandong Tian
0
0
While recently Large Language Models (LLMs) have achieved remarkable successes, they are vulnerable to certain jailbreaking attacks that lead to generation of inappropriate or harmful content. Manual red-teaming requires finding adversarial prompts that cause such jailbreaking, e.g. by appending a suffix to a given instruction, which is inefficient and time-consuming. On the other hand, automatic adversarial prompt generation often leads to semantically meaningless attacks that can easily be detected by perplexity-based filters, may require gradient information from the TargetLLM, or do not scale well due to time-consuming discrete optimization processes over the token space. In this paper, we present a novel method that uses another LLM, called the AdvPrompter, to generate human-readable adversarial prompts in seconds, $sim800times$ faster than existing optimization-based approaches. We train the AdvPrompter using a novel algorithm that does not require access to the gradients of the TargetLLM. This process alternates between two steps: (1) generating high-quality target adversarial suffixes by optimizing the AdvPrompter predictions, and (2) low-rank fine-tuning of the AdvPrompter with the generated adversarial suffixes. The trained AdvPrompter generates suffixes that veil the input instruction without changing its meaning, such that the TargetLLM is lured to give a harmful response. Experimental results on popular open source TargetLLMs show state-of-the-art results on the AdvBench dataset, that also transfer to closed-source black-box LLM APIs. Further, we demonstrate that by fine-tuning on a synthetic dataset generated by AdvPrompter, LLMs can be made more robust against jailbreaking attacks while maintaining performance, i.e. high MMLU scores.
4/29/2024
Plug and Play with Prompts: A Prompt Tuning Approach for Controlling Text Generation
Rohan Deepak Ajwani, Zining Zhu, Jonathan Rose, Frank Rudzicz
0
0
Transformer-based Large Language Models (LLMs) have shown exceptional language generation capabilities in response to text-based prompts. However, controlling the direction of generation via textual prompts has been challenging, especially with smaller models. In this work, we explore the use of Prompt Tuning to achieve controlled language generation. Generated text is steered using prompt embeddings, which are trained using a small language model, used as a discriminator. Moreover, we demonstrate that these prompt embeddings can be trained with a very small dataset, with as low as a few hundred training examples. Our method thus offers a data and parameter efficient solution towards controlling language model outputs. We carry out extensive evaluation on four datasets: SST-5 and Yelp (sentiment analysis), GYAFC (formality) and JIGSAW (toxic language). Finally, we demonstrate the efficacy of our method towards mitigating harmful, toxic, and biased text generated by language models.
4/9/2024
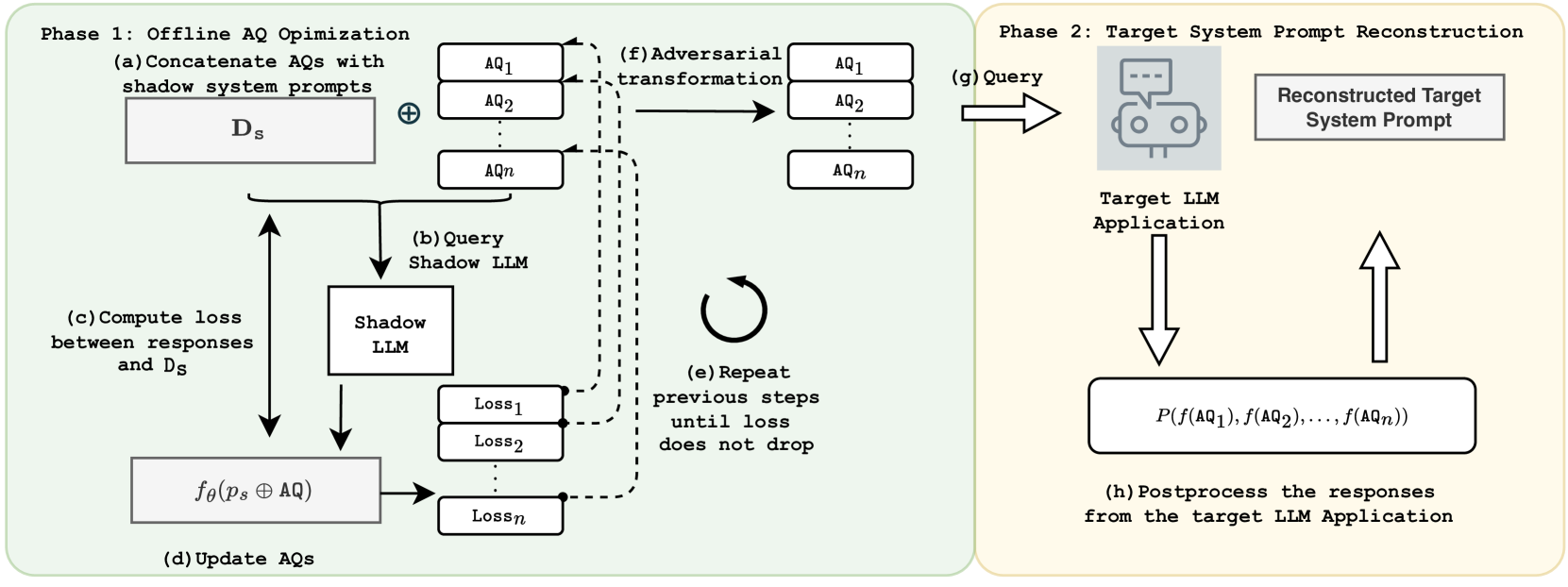
PLeak: Prompt Leaking Attacks against Large Language Model Applications
Bo Hui, Haolin Yuan, Neil Gong, Philippe Burlina, Yinzhi Cao
0
0
Large Language Models (LLMs) enable a new ecosystem with many downstream applications, called LLM applications, with different natural language processing tasks. The functionality and performance of an LLM application highly depend on its system prompt, which instructs the backend LLM on what task to perform. Therefore, an LLM application developer often keeps a system prompt confidential to protect its intellectual property. As a result, a natural attack, called prompt leaking, is to steal the system prompt from an LLM application, which compromises the developer's intellectual property. Existing prompt leaking attacks primarily rely on manually crafted queries, and thus achieve limited effectiveness. In this paper, we design a novel, closed-box prompt leaking attack framework, called PLeak, to optimize an adversarial query such that when the attacker sends it to a target LLM application, its response reveals its own system prompt. We formulate finding such an adversarial query as an optimization problem and solve it with a gradient-based method approximately. Our key idea is to break down the optimization goal by optimizing adversary queries for system prompts incrementally, i.e., starting from the first few tokens of each system prompt step by step until the entire length of the system prompt. We evaluate PLeak in both offline settings and for real-world LLM applications, e.g., those on Poe, a popular platform hosting such applications. Our results show that PLeak can effectively leak system prompts and significantly outperforms not only baselines that manually curate queries but also baselines with optimized queries that are modified and adapted from existing jailbreaking attacks. We responsibly reported the issues to Poe and are still waiting for their response. Our implementation is available at this repository: https://github.com/BHui97/PLeak.
5/15/2024
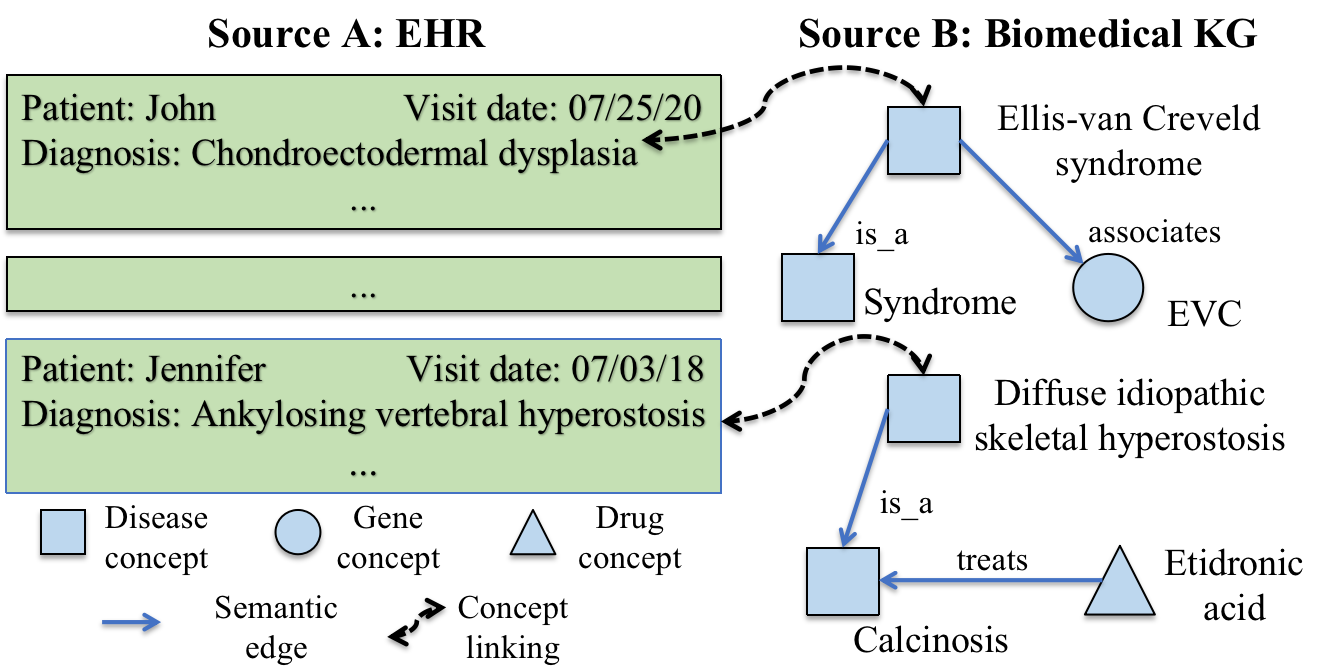
PromptLink: Leveraging Large Language Models for Cross-Source Biomedical Concept Linking
Yuzhang Xie, Jiaying Lu, Joyce Ho, Fadi Nahab, Xiao Hu, Carl Yang
0
0
Linking (aligning) biomedical concepts across diverse data sources enables various integrative analyses, but it is challenging due to the discrepancies in concept naming conventions. Various strategies have been developed to overcome this challenge, such as those based on string-matching rules, manually crafted thesauri, and machine learning models. However, these methods are constrained by limited prior biomedical knowledge and can hardly generalize beyond the limited amounts of rules, thesauri, or training samples. Recently, large language models (LLMs) have exhibited impressive results in diverse biomedical NLP tasks due to their unprecedentedly rich prior knowledge and strong zero-shot prediction abilities. However, LLMs suffer from issues including high costs, limited context length, and unreliable predictions. In this research, we propose PromptLink, a novel biomedical concept linking framework that leverages LLMs. It first employs a biomedical-specialized pre-trained language model to generate candidate concepts that can fit in the LLM context windows. Then it utilizes an LLM to link concepts through two-stage prompts, where the first-stage prompt aims to elicit the biomedical prior knowledge from the LLM for the concept linking task and the second-stage prompt enforces the LLM to reflect on its own predictions to further enhance their reliability. Empirical results on the concept linking task between two EHR datasets and an external biomedical KG demonstrate the effectiveness of PromptLink. Furthermore, PromptLink is a generic framework without reliance on additional prior knowledge, context, or training data, making it well-suited for concept linking across various types of data sources. The source code is available at https://github.com/constantjxyz/PromptLink.
5/14/2024