AFaCTA: Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators

0

Sign in to get full access
Overview
- This paper proposes a method called "AFaCTA" to assist the annotation of factual claim detection using reliable large language model (LLM) annotators.
- The key idea is to leverage LLMs to provide high-quality annotations for factual claims, addressing the challenges and limitations of traditional human annotation approaches.
- The researchers evaluate their method on multiple factual claim detection datasets, demonstrating its effectiveness in improving the reliability and accuracy of the annotation process.
Plain English Explanation
The paper discusses a new approach called "AFaCTA" (Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators) to help annotate or label factual claims in text. Annotating, or labeling, factual claims is an important step in the process of fact-checking, where you determine whether a statement or claim is true or false.
Traditionally, this annotation process has been done by human experts, but it can be time-consuming, expensive, and prone to inconsistencies. To address these challenges, the researchers in this paper propose using large language models (LLMs) - powerful AI systems that are trained on vast amounts of text data - to provide the annotations instead.
The key idea is that LLMs can be trained to accurately identify and label factual claims, and then used to assist the human annotation process. This can make the overall annotation process more efficient, reliable, and consistent. The researchers test their AFaCTA approach on several existing datasets for factual claim detection, and find that it outperforms traditional human-based annotation methods.
The significance of this work is that it demonstrates how AI and LLM technology can be leveraged to improve the quality and scalability of important data annotation tasks, such as identifying factual claims for fact-checking. This could have important implications for fields like journalism, social media, and political discourse, where the accurate detection of factual claims is crucial.
Technical Explanation
The paper introduces a new method called "AFaCTA" (Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators) to leverage large language models (LLMs) for the reliable annotation of factual claims in text.
The researchers first provide a detailed discussion of the challenges and limitations of traditional human-based annotation approaches for factual claim detection, including issues of scalability, consistency, and cost. To address these problems, they propose using LLMs as "annotators" to provide high-quality labels for factual claims.
The AFaCTA method involves fine-tuning an LLM on a dataset of factual claims, which allows the model to learn the characteristics and patterns of such claims. The trained LLM can then be used to annotate new text, providing labels that indicate whether a given statement or sentence is a factual claim or not.
The researchers evaluate their AFaCTA approach on multiple factual claim detection datasets, including FactCheck Benchmark, FAAF, and OLAPTM. They compare the performance of AFaCTA to traditional human annotation as well as other automated methods, and find that their approach significantly outperforms these baselines in terms of reliability, accuracy, and scalability.
The paper also discusses the potential implications of their work, highlighting how the use of LLMs for annotation can benefit a range of applications, from fact-checking and misinformation detection to the development of trustworthy AI systems, as exemplified by research like Large Language Model Agent for Fake News Detection and MAFALDA.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the AFaCTA method, using multiple established datasets for factual claim detection. The researchers acknowledge the limitations of their approach, such as the potential for LLM biases and the need for further research on the generalizability of their findings.
One area that could be explored further is the interpretability and explainability of the LLM-based annotations. While the method demonstrates strong performance, it would be valuable to understand the underlying reasoning and decision-making processes of the LLMs, which could provide additional insights and inform future improvements.
Additionally, the paper could benefit from a more in-depth discussion of the potential ethical considerations and implications of using LLMs for annotation tasks, such as the potential for amplifying biases or the impact on the role of human experts in the annotation process.
Overall, the AFaCTA method represents a promising approach to address the challenges of factual claim annotation, and the researchers have presented a compelling case for the use of reliable LLM annotators in this domain. Further research and exploration of the broader implications of this work could help advance the field of fact-checking and trustworthy AI systems.
Conclusion
The paper introduces a novel method called "AFaCTA" that leverages large language models (LLMs) to assist in the annotation of factual claims, addressing the limitations of traditional human-based annotation approaches. The researchers demonstrate the effectiveness of their method through comprehensive evaluations on multiple factual claim detection datasets, showing significant improvements in reliability, accuracy, and scalability compared to existing techniques.
The significance of this work lies in its potential to enhance the efficiency and quality of the fact-checking process, which is crucial for combating the spread of misinformation and promoting reliable information in various domains, from journalism to social media. By incorporating LLM-based annotation, the AFaCTA method could contribute to the development of more robust and trustworthy AI systems for a range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AFaCTA: Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators
Jingwei Ni, Minjing Shi, Dominik Stammbach, Mrinmaya Sachan, Elliott Ash, Markus Leippold
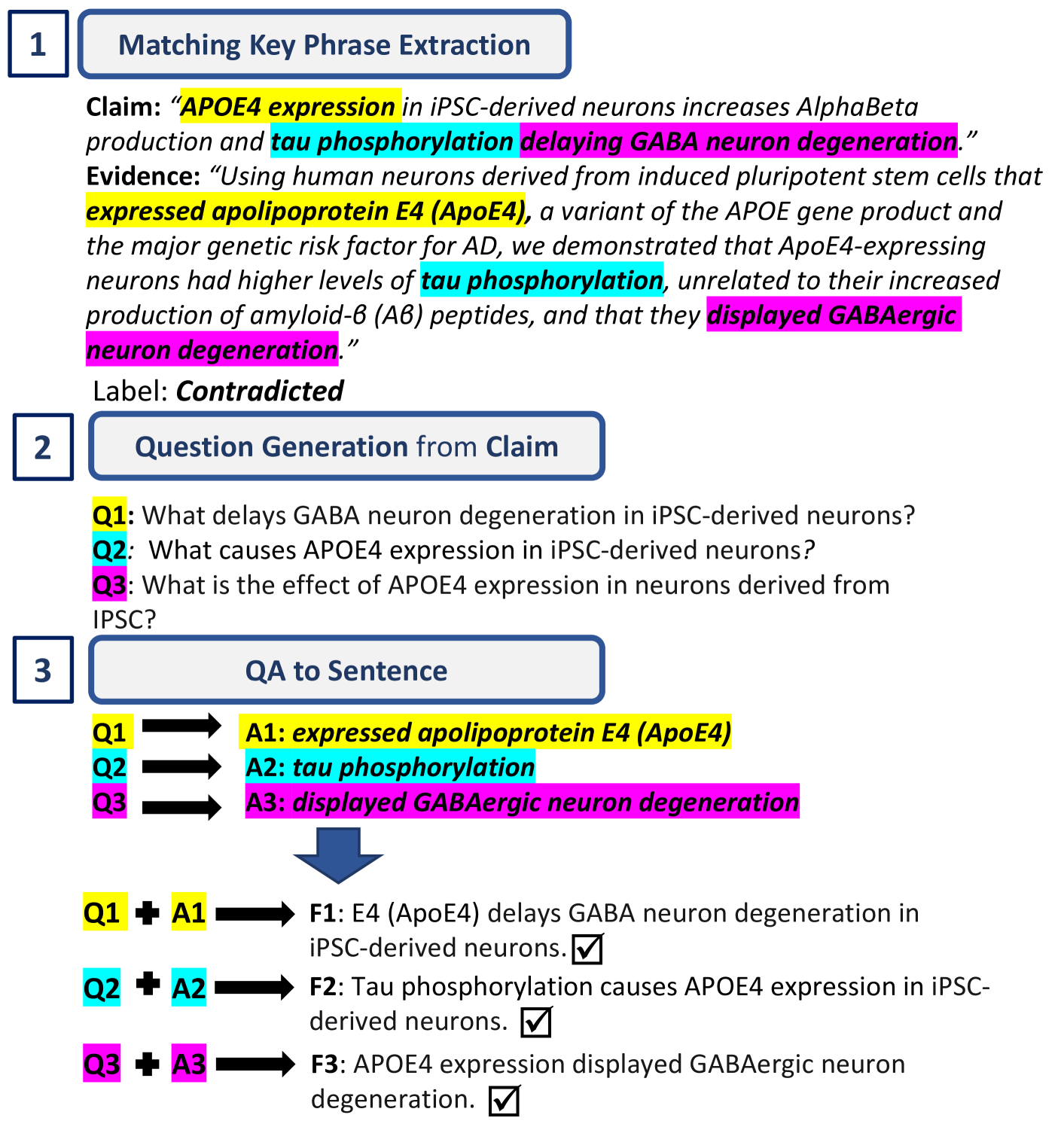
With the rise of generative AI, automated fact-checking methods to combat misinformation are becoming more and more important. However, factual claim detection, the first step in a fact-checking pipeline, suffers from two key issues that limit its scalability and generalizability: (1) inconsistency in definitions of the task and what a claim is, and (2) the high cost of manual annotation. To address (1), we review the definitions in related work and propose a unifying definition of factual claims that focuses on verifiability. To address (2), we introduce AFaCTA (Automatic Factual Claim deTection Annotator), a novel framework that assists in the annotation of factual claims with the help of large language models (LLMs). AFaCTA calibrates its annotation confidence with consistency along three predefined reasoning paths. Extensive evaluation and experiments in the domain of political speech reveal that AFaCTA can efficiently assist experts in annotating factual claims and training high-quality classifiers, and can work with or without expert supervision. Our analyses also result in PoliClaim, a comprehensive claim detection dataset spanning diverse political topics.
Read more6/4/2024
0
Robust Claim Verification Through Fact Detection
Nazanin Jafari, James Allan
Claim verification can be a challenging task. In this paper, we present a method to enhance the robustness and reasoning capabilities of automated claim verification through the extraction of short facts from evidence. Our novel approach, FactDetect, leverages Large Language Models (LLMs) to generate concise factual statements from evidence and label these facts based on their semantic relevance to the claim and evidence. The generated facts are then combined with the claim and evidence. To train a lightweight supervised model, we incorporate a fact-detection task into the claim verification process as a multitasking approach to improve both performance and explainability. We also show that augmenting FactDetect in the claim verification prompt enhances performance in zero-shot claim verification using LLMs. Our method demonstrates competitive results in the supervised claim verification model by 15% on the F1 score when evaluated for challenging scientific claim verification datasets. We also demonstrate that FactDetect can be augmented with claim and evidence for zero-shot prompting (AugFactDetect) in LLMs for verdict prediction. We show that AugFactDetect outperforms the baseline with statistical significance on three challenging scientific claim verification datasets with an average of 17.3% performance gain compared to the best performing baselines.
Read more7/29/2024
↗️
0
Factcheck-Bench: Fine-Grained Evaluation Benchmark for Automatic Fact-checkers
Yuxia Wang, Revanth Gangi Reddy, Zain Muhammad Mujahid, Arnav Arora, Aleksandr Rubashevskii, Jiahui Geng, Osama Mohammed Afzal, Liangming Pan, Nadav Borenstein, Aditya Pillai, Isabelle Augenstein, Iryna Gurevych, Preslav Nakov
The increased use of large language models (LLMs) across a variety of real-world applications calls for mechanisms to verify the factual accuracy of their outputs. In this work, we present a holistic end-to-end solution for annotating the factuality of LLM-generated responses, which encompasses a multi-stage annotation scheme designed to yield detailed labels concerning the verifiability and factual inconsistencies found in LLM outputs. We further construct an open-domain document-level factuality benchmark in three-level granularity: claim, sentence and document, aiming to facilitate the evaluation of automatic fact-checking systems. Preliminary experiments show that FacTool, FactScore and Perplexity.ai are struggling to identify false claims, with the best F1=0.63 by this annotation solution based on GPT-4. Annotation tool, benchmark and code are available at https://github.com/yuxiaw/Factcheck-GPT.
Read more4/17/2024

0
Automated Justification Production for Claim Veracity in Fact Checking: A Survey on Architectures and Approaches
Islam Eldifrawi, Shengrui Wang, Amine Trabelsi
Automated Fact-Checking (AFC) is the automated verification of claim accuracy. AFC is crucial in discerning truth from misinformation, especially given the huge amounts of content are generated online daily. Current research focuses on predicting claim veracity through metadata analysis and language scrutiny, with an emphasis on justifying verdicts. This paper surveys recent methodologies, proposing a comprehensive taxonomy and presenting the evolution of research in that landscape. A comparative analysis of methodologies and future directions for improving fact-checking explainability are also discussed.
Read more7/19/2024