FaaF: Facts as a Function for the evaluation of generated text

0

Sign in to get full access
Overview
- This paper introduces "Facts as a Function" (FaaF), a new approach for evaluating the factual accuracy of Retrieval-Augmented Generation (RAG) systems.
- RAG systems combine language models with information retrieval to generate responses that are grounded in external knowledge.
- FaaF measures the factual accuracy of RAG system outputs by comparing them to a set of ground truth facts.
- The paper evaluates FaaF on several benchmark datasets and compares it to existing evaluation metrics.
Plain English Explanation
The paper presents a new way to evaluate the accuracy of a type of AI system called a "Retrieval-Augmented Generation" (RAG) system. RAG systems combine large language models with information retrieval to generate responses that draw on external knowledge.
The key idea behind the "Facts as a Function" (FaaF) approach is to compare the information in the RAG system's output to a set of known, ground truth facts. This allows the researchers to quantify how factually accurate the system's responses are.
Imagine you asked an AI assistant a question like "Who is the current president of the United States?". A factually accurate response would be "Joe Biden is the current president of the United States." FaaF evaluates whether the AI's response matches this known fact.
By using FaaF to assess RAG systems, the researchers can better understand how well these systems are able to provide truthful, factually grounded information in their outputs. This is an important capability for AI systems that are designed to assist humans with tasks that require reliable knowledge.
Technical Explanation
The core of the FaaF approach is to define a set of "facts" - pieces of information that are known to be true. These facts are represented as key-value pairs, where the key is a factual statement and the value indicates whether that statement is true or false.
To evaluate a RAG system using FaaF, the researchers first collect a set of queries and the corresponding system outputs. They then check each output against the fact set to determine how many of the factual statements made in the output match the ground truth facts. This produces a "factual accuracy" score for the system.
The paper evaluates FaaF on several benchmark datasets for question answering and open-ended generation. They compare the FaaF scores to other factuality evaluation metrics, such as AMRFACT and LFM, and find that FaaF provides a more nuanced and informative assessment of factual accuracy.
Critical Analysis
The FaaF approach has several advantages over existing factuality evaluation methods. By using a set of structured facts, it can more precisely identify which specific claims made by a system are accurate or inaccurate. This provides deeper insights compared to binary "factual/not factual" judgments.
However, the paper acknowledges that defining a comprehensive set of facts is a significant challenge. The fact set used in the experiments is relatively small, and may not capture the full scope of knowledge required to answer real-world questions. Expanding the fact set, while maintaining high quality, is an important area for future research.
Additionally, the FaaF evaluation assumes that all facts in the set are equally important. In practice, the factual accuracy of different claims may have varying levels of significance. Incorporating a way to weight the importance of facts could further improve the usefulness of the FaaF metric.
Conclusion
Overall, the FaaF approach represents a valuable step forward in evaluating the factual accuracy of RAG systems and other language models that incorporate external knowledge. By quantifying how well system outputs align with ground truth facts, FaaF provides a more nuanced and informative assessment than existing metrics.
As large language models continue to advance and be deployed in high-stakes applications, robust factuality evaluation will be crucial. The FaaF framework lays the groundwork for further research in this important area, with the potential to drive the development of more reliable and trustworthy AI assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FaaF: Facts as a Function for the evaluation of generated text
Vasileios Katranidis, Gabor Barany
The demand for accurate and efficient verification of information in texts generated by large language models (LMs) is at an all-time high, but remains unresolved. Recent efforts have focused on extracting and verifying atomic facts from these texts via prompting LM evaluators. However, we demonstrate that this method of prompting is unreliable when faced with incomplete or inaccurate reference information. We introduce Facts as a Function (FaaF), a new approach to the fact verification task that leverages the function-calling capabilities of LMs. FaaF significantly enhances the ability of LMs to identify unsupported facts in texts, while also improving efficiency and significantly lowering costs compared to prompt-based methods. Additionally, we propose a framework for evaluating factual recall in Retrieval Augmented Generation (RAG) systems, which we employ to compare prompt-based and FaaF methods using various LMs under challenging conditions.
Read more4/9/2024

0
AFaCTA: Assisting the Annotation of Factual Claim Detection with Reliable LLM Annotators
Jingwei Ni, Minjing Shi, Dominik Stammbach, Mrinmaya Sachan, Elliott Ash, Markus Leippold
With the rise of generative AI, automated fact-checking methods to combat misinformation are becoming more and more important. However, factual claim detection, the first step in a fact-checking pipeline, suffers from two key issues that limit its scalability and generalizability: (1) inconsistency in definitions of the task and what a claim is, and (2) the high cost of manual annotation. To address (1), we review the definitions in related work and propose a unifying definition of factual claims that focuses on verifiability. To address (2), we introduce AFaCTA (Automatic Factual Claim deTection Annotator), a novel framework that assists in the annotation of factual claims with the help of large language models (LLMs). AFaCTA calibrates its annotation confidence with consistency along three predefined reasoning paths. Extensive evaluation and experiments in the domain of political speech reveal that AFaCTA can efficiently assist experts in annotating factual claims and training high-quality classifiers, and can work with or without expert supervision. Our analyses also result in PoliClaim, a comprehensive claim detection dataset spanning diverse political topics.
Read more6/4/2024

0
Measuring text summarization factuality using atomic facts entailment metrics in the context of retrieval augmented generation
N. E. Kriman
The use of large language models (LLMs) has significantly increased since the introduction of ChatGPT in 2022, demonstrating their value across various applications. However, a major challenge for enterprise and commercial adoption of LLMs is their tendency to generate inaccurate information, a phenomenon known as hallucination. This project proposes a method for estimating the factuality of a summary generated by LLMs when compared to a source text. Our approach utilizes Naive Bayes classification to assess the accuracy of the content produced.
Read more8/28/2024
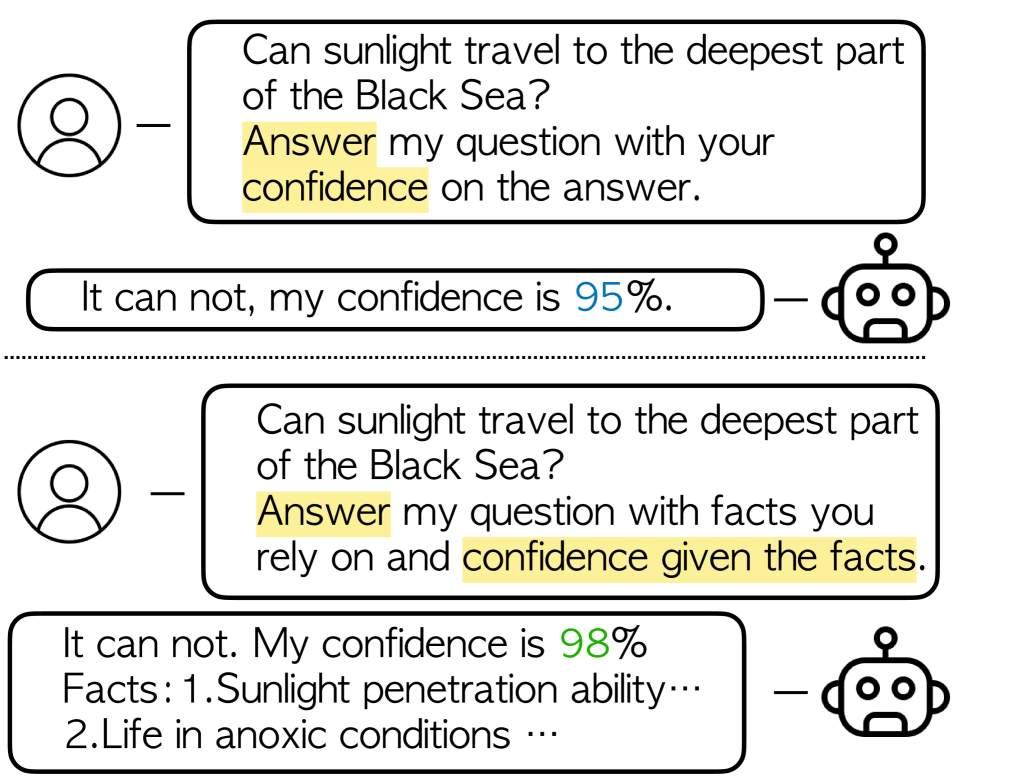
0
Fact-and-Reflection (FaR) Improves Confidence Calibration of Large Language Models
Xinran Zhao, Hongming Zhang, Xiaoman Pan, Wenlin Yao, Dong Yu, Tongshuang Wu, Jianshu Chen
For a LLM to be trustworthy, its confidence level should be well-calibrated with its actual performance. While it is now common sense that LLM performances are greatly impacted by prompts, the confidence calibration in prompting LLMs has yet to be thoroughly explored. In this paper, we explore how different prompting strategies influence LLM confidence calibration and how it could be improved. We conduct extensive experiments on six prompting methods in the question-answering context and we observe that, while these methods help improve the expected LLM calibration, they also trigger LLMs to be over-confident when responding to some instances. Inspired by human cognition, we propose Fact-and-Reflection (FaR) prompting, which improves the LLM calibration in two steps. First, FaR elicits the known facts that are relevant to the input prompt from the LLM. And then it asks the model to reflect over them to generate the final answer. Experiments show that FaR prompting achieves significantly better calibration; it lowers the Expected Calibration Error by 23.5% on our multi-purpose QA tasks. Notably, FaR prompting even elicits the capability of verbally expressing concerns in less confident scenarios, which helps trigger retrieval augmentation for solving these harder instances.
Read more9/10/2024