Affordances-Oriented Planning using Foundation Models for Continuous Vision-Language Navigation

0

Sign in to get full access
Overview
- This paper presents a new approach to vision-language navigation (VLN) called Affordances-Oriented Planning (AOP) that leverages foundation models to continuously plan and navigate through environments.
- AOP uses a RoboPOINT model to predict the affordances of objects in the environment, which are then used to plan the agent's actions.
- The paper also introduces a new benchmark dataset for continuous VLN tasks and evaluates the proposed AOP approach on this dataset, comparing it to other state-of-the-art VLN methods.
Plain English Explanation
The paper describes a new way for AI systems to navigate through environments by understanding the "affordances" of objects around them. Affordances are the possible actions that an object allows - for example, a chair "affords" sitting, while a door "affords" opening and passing through.
The key idea is that by predicting the affordances of objects in the environment, the AI system can plan its actions more effectively to achieve its goals. For example, if the system knows that a chair affords sitting, it can plan to navigate to the chair and sit down, rather than just trying to move to a specific location.
The authors use a RoboPOINT model to predict these affordances, which helps the system continuously plan its actions as it moves through the environment. They also introduce a new benchmark dataset for testing continuous VLN tasks, and show that their Affordances-Oriented Planning (AOP) approach outperforms other state-of-the-art methods on this dataset.
Overall, the key innovation is using affordance prediction to guide the planning and decision-making of the AI system, rather than just trying to follow a predetermined path. This allows the system to be more flexible and adaptive as it navigates through the real world.
Technical Explanation
The paper proposes a new approach called Affordances-Oriented Planning (AOP) for continuous vision-language navigation (VLN) tasks. AOP uses a RoboPOINT model to predict the affordances of objects in the environment, which are then used to guide the planning and execution of the agent's actions.
Specifically, the RoboPOINT model is used to predict a set of affordances for each object in the agent's field of view, such as whether an object can be sat on, opened, walked through, etc. These affordance predictions are then used by a planning module to determine the optimal sequence of actions the agent should take to achieve its goal, which may involve navigating to and interacting with specific objects.
The authors also introduce a new benchmark dataset for continuous VLN tasks, which involves navigating through environments and completing natural language instructions that may require interacting with objects along the way. They evaluate their proposed AOP approach on this dataset and compare it to other state-of-the-art VLN methods, such as NavID, MC-GPT, and AffordanceLLM.
The results show that the AOP approach, which leverages affordance prediction from foundation models, outperforms these other methods on a range of metrics, including success rate, path length, and task completion time. This highlights the potential of using affordance-based planning for continuous VLN tasks, where the agent needs to dynamically adapt its actions based on the changing environment and task requirements.
Critical Analysis
The paper presents a compelling approach to vision-language navigation that leverages affordance prediction to guide the planning and execution of the agent's actions. By using a foundation model like RoboPOINT to predict the affordances of objects in the environment, the system can make more informed decisions about how to navigate and interact with its surroundings.
One potential limitation of the approach is the reliance on the accuracy and reliability of the affordance predictions made by the RoboPOINT model. If the model makes mistakes in its affordance predictions, this could lead to suboptimal planning and navigation decisions by the agent. The authors acknowledge this limitation and suggest that further research is needed to improve the robustness and generalization of affordance prediction models.
Additionally, the paper focuses on a specific type of continuous VLN task, and it's unclear how well the AOP approach would generalize to other types of navigation and manipulation tasks. The authors could have explored the performance of their method on a wider range of scenarios to better understand its broader applicability.
Overall, the paper makes a strong contribution to the field of vision-language navigation by demonstrating the potential of affordance-based planning. The authors' work highlights the importance of grounding language understanding in the physical world and using this knowledge to guide the decision-making of embodied AI agents. Further research in this direction, with a focus on improving the reliability and generalization of affordance prediction, could lead to significant advancements in the field of continuous vision-language navigation.
Conclusion
This paper presents a novel approach to vision-language navigation called Affordances-Oriented Planning (AOP) that leverages foundation models to continuously plan and navigate through environments. By using a RoboPOINT model to predict the affordances of objects in the environment, the AOP system can make more informed decisions about how to achieve its goals, leading to improved navigation performance compared to other state-of-the-art methods.
The introduction of a new benchmark dataset for continuous VLN tasks and the empirical evaluation of the AOP approach on this dataset are important contributions that advance the field of vision-language navigation. The critical analysis highlights the potential limitations of the approach, such as the reliance on the accuracy of affordance predictions, and suggests areas for further research to improve the robustness and generalization of the system.
Overall, this paper demonstrates the value of grounding language understanding in the physical world and using this knowledge to guide the decision-making of embodied AI agents. The affordance-based planning approach represents an important step forward in the development of more flexible and adaptive vision-language navigation systems that can better navigate and interact with complex, real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Affordances-Oriented Planning using Foundation Models for Continuous Vision-Language Navigation
Jiaqi Chen, Bingqian Lin, Xinmin Liu, Lin Ma, Xiaodan Liang, Kwan-Yee K. Wong
LLM-based agents have demonstrated impressive zero-shot performance in vision-language navigation (VLN) task. However, existing LLM-based methods often focus only on solving high-level task planning by selecting nodes in predefined navigation graphs for movements, overlooking low-level control in navigation scenarios. To bridge this gap, we propose AO-Planner, a novel Affordances-Oriented Planner for continuous VLN task. Our AO-Planner integrates various foundation models to achieve affordances-oriented low-level motion planning and high-level decision-making, both performed in a zero-shot setting. Specifically, we employ a Visual Affordances Prompting (VAP) approach, where the visible ground is segmented by SAM to provide navigational affordances, based on which the LLM selects potential candidate waypoints and plans low-level paths towards selected waypoints. We further propose a high-level PathAgent which marks planned paths into the image input and reasons the most probable path by comprehending all environmental information. Finally, we convert the selected path into 3D coordinates using camera intrinsic parameters and depth information, avoiding challenging 3D predictions for LLMs. Experiments on the challenging R2R-CE and RxR-CE datasets show that AO-Planner achieves state-of-the-art zero-shot performance (8.8% improvement on SPL). Our method can also serve as a data annotator to obtain pseudo-labels, distilling its waypoint prediction ability into a learning-based predictor. This new predictor does not require any waypoint data from the simulator and achieves 47% SR competing with supervised methods. We establish an effective connection between LLM and 3D world, presenting novel prospects for employing foundation models in low-level motion control.
Read more8/21/2024
0
Narrowing the Gap between Vision and Action in Navigation
Yue Zhang, Parisa Kordjamshidi
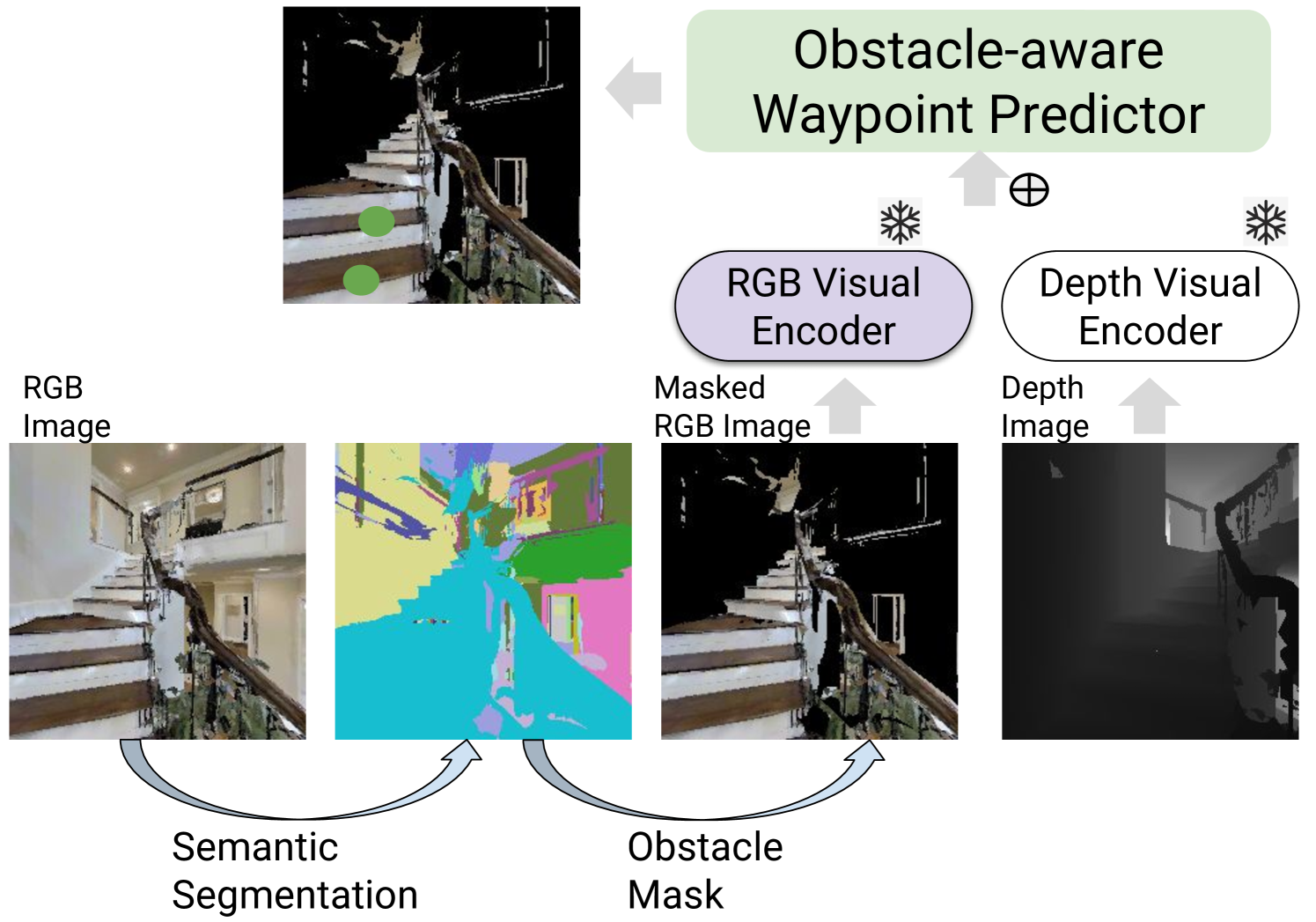
The existing methods for Vision and Language Navigation in the Continuous Environment (VLN-CE) commonly incorporate a waypoint predictor to discretize the environment. This simplifies the navigation actions into a view selection task and improves navigation performance significantly compared to direct training using low-level actions. However, the VLN-CE agents are still far from the real robots since there are gaps between their visual perception and executed actions. First, VLN-CE agents that discretize the visual environment are primarily trained with high-level view selection, which causes them to ignore crucial spatial reasoning within the low-level action movements. Second, in these models, the existing waypoint predictors neglect object semantics and their attributes related to passibility, which can be informative in indicating the feasibility of actions. To address these two issues, we introduce a low-level action decoder jointly trained with high-level action prediction, enabling the current VLN agent to learn and ground the selected visual view to the low-level controls. Moreover, we enhance the current waypoint predictor by utilizing visual representations containing rich semantic information and explicitly masking obstacles based on humans' prior knowledge about the feasibility of actions. Empirically, our agent can improve navigation performance metrics compared to the strong baselines on both high-level and low-level actions.
Read more8/21/2024

0
RoboPoint: A Vision-Language Model for Spatial Affordance Prediction for Robotics
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, Dieter Fox
From rearranging objects on a table to putting groceries into shelves, robots must plan precise action points to perform tasks accurately and reliably. In spite of the recent adoption of vision language models (VLMs) to control robot behavior, VLMs struggle to precisely articulate robot actions using language. We introduce an automatic synthetic data generation pipeline that instruction-tunes VLMs to robotic domains and needs. Using the pipeline, we train RoboPoint, a VLM that predicts image keypoint affordances given language instructions. Compared to alternative approaches, our method requires no real-world data collection or human demonstration, making it much more scalable to diverse environments and viewpoints. In addition, RoboPoint is a general model that enables several downstream applications such as robot navigation, manipulation, and augmented reality (AR) assistance. Our experiments demonstrate that RoboPoint outperforms state-of-the-art VLMs (GPT-4o) and visual prompting techniques (PIVOT) by 21.8% in the accuracy of predicting spatial affordance and by 30.5% in the success rate of downstream tasks. Project website: https://robo-point.github.io.
Read more6/18/2024
0
Vision-and-Language Navigation Today and Tomorrow: A Survey in the Era of Foundation Models
Yue Zhang, Ziqiao Ma, Jialu Li, Yanyuan Qiao, Zun Wang, Joyce Chai, Qi Wu, Mohit Bansal, Parisa Kordjamshidi
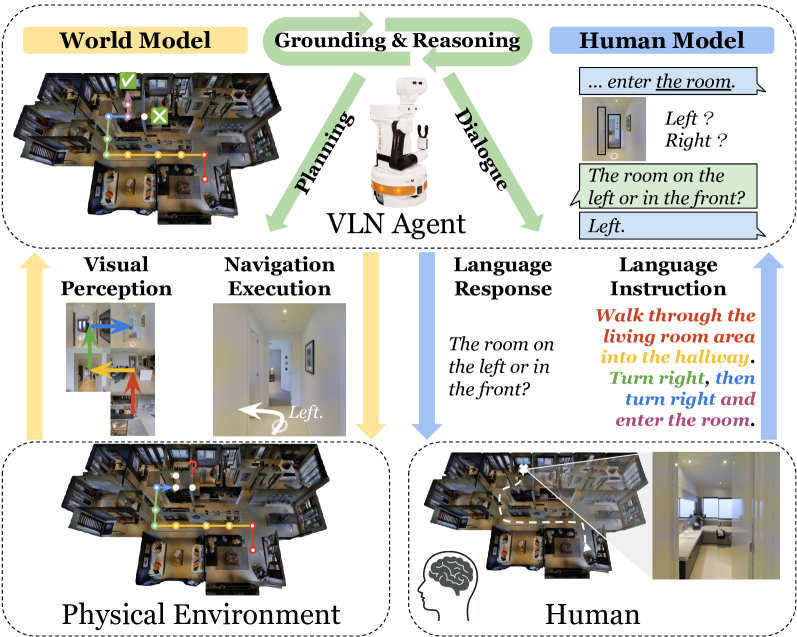
Vision-and-Language Navigation (VLN) has gained increasing attention over recent years and many approaches have emerged to advance their development. The remarkable achievements of foundation models have shaped the challenges and proposed methods for VLN research. In this survey, we provide a top-down review that adopts a principled framework for embodied planning and reasoning, and emphasizes the current methods and future opportunities leveraging foundation models to address VLN challenges. We hope our in-depth discussions could provide valuable resources and insights: on one hand, to milestone the progress and explore opportunities and potential roles for foundation models in this field, and on the other, to organize different challenges and solutions in VLN to foundation model researchers.
Read more7/10/2024