AgentGen: Enhancing Planning Abilities for Large Language Model based Agent via Environment and Task Generation

0
💬
Sign in to get full access
Overview
- Large language models (LLMs) have gained significant attention and are becoming increasingly popular.
- Planning ability is a crucial component of an LLM-based agent, involving interaction with the environment and executing actions to complete a planning task.
- This paper investigates enhancing the planning abilities of LLMs through instruction tuning, referred to as agent training.
- Recent studies have shown that using expert-level trajectories for instruction-tuning LLMs effectively enhances their planning capabilities.
- Existing work primarily focuses on synthesizing trajectories from manually designed planning tasks and environments, which is labor-intensive.
- This paper explores the automated synthesis of diverse environments and a gradual range of planning tasks, from easy to difficult.
Plain English Explanation
The paper focuses on improving the planning abilities of large language models (LLMs), which are AI systems that can generate human-like text. Planning is an important skill for these LLM-based agents, as it involves understanding the environment, making decisions, and taking actions to achieve a specific goal.
Recent research has shown that training LLMs on expert-level examples of planning tasks can enhance their planning capabilities. However, creating these expert-level examples is a manual and time-consuming process, which limits the diversity of the training data.
To address this limitation, the researchers in this paper introduce a framework called AgentGen. AgentGen uses LLMs to automatically generate diverse environments and a range of planning tasks, from easy to difficult. This allows for the creation of a larger and more varied dataset for training LLM-based agents.
The key ideas behind AgentGen are:
-
Generating diverse environments: The researchers propose using an "inspiration corpus" - a collection of text from various domains - to help the LLM generate a wider range of environments for the planning tasks.
-
Generating a range of task difficulties: The researchers introduce a "bidirectional evolution" method, called Bi-Evol, that can generate planning tasks with a smooth difficulty curve, from easy to hard.
By using AgentGen, the researchers were able to train an LLM-based agent (Llama-3 8B) that outperformed even the powerful GPT-3.5 model in overall planning performance, and in some tasks, even outperformed the latest GPT-4 model.
Technical Explanation
The paper presents a framework called AgentGen that aims to enhance the planning abilities of LLM-based agents through automated environment and task generation.
Environment Generation: AgentGen leverages LLMs to generate diverse environments for the planning tasks. To improve environmental diversity, the researchers propose using an "inspiration corpus" - a collection of text from various domains - as the context for synthesizing environments.
Task Generation: To increase the difficulty diversity of the generated planning tasks, the researchers introduce a "bidirectional evolution" method, Bi-Evol. Bi-Evol evolves planning tasks from both easier and harder directions to synthesize a task set with a smoother difficulty curve.
Evaluation: The researchers evaluate the planning abilities of LLM-based agents trained with AgentGen on the AgentBoard benchmark. The results show that the AgentGen instruction-tuned Llama-3 8B model surpasses the performance of GPT-3.5 in overall planning tasks and even outperforms GPT-4 in certain tasks.
Critical Analysis
The paper presents a novel approach to enhancing the planning capabilities of LLM-based agents through automated environment and task generation. The key strengths of this research are:
-
Scalability: By automating the process of environment and task generation, the researchers can create a larger and more diverse dataset for training LLM-based agents, overcoming the limitations of manual task design.
-
Difficulty Diversity: The Bi-Evol method allows for the generation of planning tasks with a smooth difficulty curve, from easy to hard, which is important for effective training and evaluation.
However, the paper also acknowledges some limitations and areas for further research:
-
Generalization: While the AgentGen-trained agent outperforms other models on the AgentBoard benchmark, it's unclear how well the approach generalizes to other planning domains or real-world scenarios.
-
Alignment: The paper does not address potential issues related to the alignment of the generated environments and tasks with human values and preferences, which is an important consideration for the deployment of such systems.
-
Interpretability: The paper does not provide insights into the internal reasoning and decision-making processes of the trained agents, which could be valuable for understanding and improving their capabilities.
Overall, the paper presents a promising approach to enhancing the planning abilities of LLM-based agents, but further research is needed to address the limitations and explore the broader implications of this technology.
Conclusion
The paper introduces AgentGen, a framework that leverages large language models to automatically generate diverse environments and a gradual range of planning tasks for training LLM-based agents. By overcoming the limitations of manual task design, AgentGen enables the creation of a larger and more varied dataset, leading to significant improvements in the planning capabilities of the trained agents.
The results show that the AgentGen-trained Llama-3 8B model outperforms the powerful GPT-3.5 model in overall planning performance and even surpasses GPT-4 in certain tasks. This demonstrates the potential of automated environment and task generation to enhance the planning abilities of LLM-based agents.
While the paper highlights the strengths of this approach, it also identifies areas for further research, such as improving generalization, addressing alignment issues, and enhancing the interpretability of the trained agents. Continued advancements in these areas could lead to even more capable and trustworthy LLM-based agents that can tackle complex planning challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
AgentGen: Enhancing Planning Abilities for Large Language Model based Agent via Environment and Task Generation
Mengkang Hu, Pu Zhao, Can Xu, Qingfeng Sun, Jianguang Lou, Qingwei Lin, Ping Luo, Saravan Rajmohan, Dongmei Zhang
Large Language Model (LLM) based agents have garnered significant attention and are becoming increasingly popular. Furthermore, planning ability is a crucial component of an LLM-based agent, involving interaction with the environment and executing actions to complete a planning task, which generally entails achieving a desired goal from an initial state. This paper investigates enhancing the planning abilities of LLMs through instruction tuning, referred to as agent training. Recent studies have demonstrated that utilizing expert-level trajectory for instruction-tuning LLMs effectively enhances their planning capabilities. However, existing work primarily focuses on synthesizing trajectories from manually designed planning tasks and environments. The labor-intensive nature of creating these environments and tasks impedes the generation of sufficiently varied and extensive trajectories. To address this limitation, this paper explores the automated synthesis of diverse environments and a gradual range of planning tasks, from easy to difficult. We introduce a framework, AgentGen, that leverages LLMs first to generate environments and subsequently generate planning tasks conditioned on these environments. Specifically, to improve environmental diversity, we propose using an inspiration corpus composed of various domain-specific text segments as the context for synthesizing environments. Moreover, to increase the difficulty diversity of generated planning tasks, we propose a bidirectional evolution method, Bi-Evol, that evolves planning tasks from easier and harder directions to synthesize a task set with a smoother difficulty curve. The evaluation results derived from AgentBoard show that AgentGen greatly improves LLMs' planning ability, e.g., the AgentGen instruction-tuned Llama-3 8B surpasses GPT-3.5 in overall performance. Moreover, in certain tasks, it even outperforms GPT-4.
Read more8/2/2024
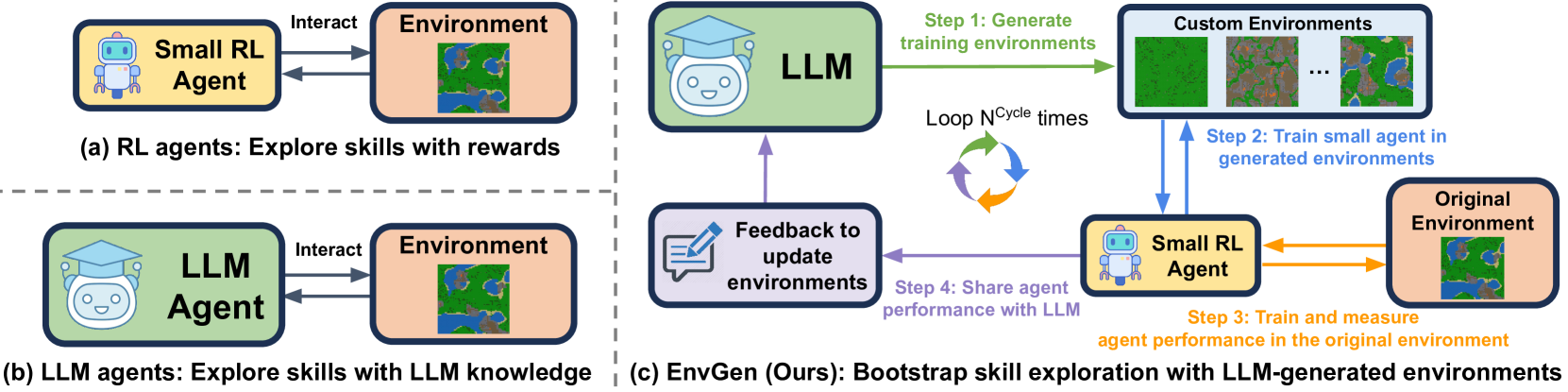
0
EnvGen: Generating and Adapting Environments via LLMs for Training Embodied Agents
Abhay Zala, Jaemin Cho, Han Lin, Jaehong Yoon, Mohit Bansal
Recent SOTA approaches for embodied learning via interaction directly employ large language models (LLMs) as agents to determine the next steps in an environment. Due to their world knowledge and reasoning capabilities, LLM agents achieve stronger performance than previous smaller agents based on reinforcement learning (RL); however, frequently calling LLMs is slow and expensive. Instead of directly employing LLMs as agents, can we use LLMs' reasoning capabilities to adaptively create training environments to help smaller RL agents learn useful skills that they are weak at? We propose EnvGen, a novel framework to address this question. We first prompt an LLM to generate training environments by giving it the task description and simulator objectives that the agents should learn and then asking it to generate a set of environment configurations (e.g., different terrains, items initially given to agents, etc.). Next, we train a small RL agent in a mixture of the original and LLM-generated environments. Then, we enable the LLM to continuously adapt the generated environments to progressively improve the skills that the agent is weak at, by providing feedback to the LLM in the form of the agent's performance. We demonstrate the usefulness of EnvGen with comprehensive experiments in Crafter and Heist environments. We find that a small RL agent trained with EnvGen can outperform SOTA methods, including a GPT-4 agent, and learns long-horizon tasks significantly faster. We also show that using an LLM to adapt environments dynamically outperforms curriculum learning approaches and how the environments are adapted to help improve RL agents' weaker skills over time. Additionally, EnvGen is substantially more efficient as it only uses a small number of LLM calls (e.g., 4 in total), whereas LLM agents require thousands of calls. Lastly, we present detailed ablation studies for EnvGen design choices.
Read more7/15/2024
0
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Qinhao Zhou, Zihan Zhang, Xiang Xiang, Ke Wang, Yuchuan Wu, Yongbin Li
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
Read more4/1/2024

0
AgentGym: Evolving Large Language Model-based Agents across Diverse Environments
Zhiheng Xi, Yiwen Ding, Wenxiang Chen, Boyang Hong, Honglin Guo, Junzhe Wang, Dingwen Yang, Chenyang Liao, Xin Guo, Wei He, Songyang Gao, Lu Chen, Rui Zheng, Yicheng Zou, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, Yu-Gang Jiang
Building generalist agents that can handle diverse tasks and evolve themselves across different environments is a long-term goal in the AI community. Large language models (LLMs) are considered a promising foundation to build such agents due to their generalized capabilities. Current approaches either have LLM-based agents imitate expert-provided trajectories step-by-step, requiring human supervision, which is hard to scale and limits environmental exploration; or they let agents explore and learn in isolated environments, resulting in specialist agents with limited generalization. In this paper, we take the first step towards building generally-capable LLM-based agents with self-evolution ability. We identify a trinity of ingredients: 1) diverse environments for agent exploration and learning, 2) a trajectory set to equip agents with basic capabilities and prior knowledge, and 3) an effective and scalable evolution method. We propose AgentGym, a new framework featuring a variety of environments and tasks for broad, real-time, uni-format, and concurrent agent exploration. AgentGym also includes a database with expanded instructions, a benchmark suite, and high-quality trajectories across environments. Next, we propose a novel method, AgentEvol, to investigate the potential of agent self-evolution beyond previously seen data across tasks and environments. Experimental results show that the evolved agents can achieve results comparable to SOTA models. We release the AgentGym suite, including the platform, dataset, benchmark, checkpoints, and algorithm implementations. The AgentGym suite is available on https://github.com/WooooDyy/AgentGym.
Read more6/7/2024