AgileFormer: Spatially Agile Transformer UNet for Medical Image Segmentation

0
Sign in to get full access
Overview
- The paper proposes a new transformer-based model called AgileFormer for medical image segmentation tasks.
- AgileFormer combines a spatially agile transformer module with a U-Net-like architecture to capture both global and local features effectively.
- The model achieves state-of-the-art performance on several medical image segmentation benchmarks.
Plain English Explanation
The paper introduces a new deep learning model called AgileFormer for the task of medical image segmentation. Medical image segmentation is the process of automatically identifying and outlining different anatomical structures or regions of interest in medical scans like MRI or CT images.
The key innovation in AgileFormer is the use of a spatially agile transformer module. Transformers are a type of neural network that are particularly good at capturing long-range dependencies in data. By making the transformer module "spatially agile," the model can adaptively focus on relevant regions of the image when extracting features, rather than treating all parts of the image equally.
AgileFormer combines this spatially agile transformer with a U-Net -like architecture, which is a popular design for medical image segmentation. The U-Net architecture allows the model to effectively capture both global context and local details in the images.
The authors show that AgileFormer outperforms other state-of-the-art medical image segmentation models on several challenging benchmarks. This suggests that the combination of a spatially agile transformer and a U-Net architecture is a powerful approach for this task.
Technical Explanation
The authors propose a new transformer-based model called AgileFormer for medical image segmentation. AgileFormer combines a spatially agile transformer module with a U-Net-like architecture.
The spatially agile transformer module is the key innovation in AgileFormer. It allows the model to adaptively focus on relevant regions of the input image when extracting features, rather than treating all parts of the image equally. This is achieved by introducing spatial attention mechanisms into the transformer module.
The U-Net-like architecture of AgileFormer enables the model to effectively capture both global context and local details in the medical images. The encoder-decoder structure of U-Net allows the model to aggregate information across different scales, while the skip connections help preserve fine-grained spatial information.
The authors evaluate AgileFormer on several medical image segmentation benchmarks, including brain MRI, cardiac MRI, and retinal OCT data. They show that AgileFormer outperforms other state-of-the-art models, such as nnU-Net and TransUNet, in terms of segmentation accuracy.
Critical Analysis
The authors provide a thorough evaluation of AgileFormer on multiple medical image segmentation datasets, which is a strength of the paper. However, they do not discuss any potential limitations or drawbacks of the model.
One potential concern is the computational complexity of the spatially agile transformer module, which may limit the practical deployment of AgileFormer in real-world clinical settings, especially for resource-constrained devices. The authors could have provided more details on the inference time and memory footprint of their model compared to other approaches.
Additionally, the paper does not explore the interpretability of AgileFormer's predictions or investigate which specific architectural components contribute the most to the model's performance. Such analysis could provide valuable insights for further improving the model or understanding its inner workings.
Overall, the paper presents a promising approach for medical image segmentation, but additional research is needed to fully understand the model's capabilities, limitations, and potential areas for improvement.
Conclusion
The paper introduces a new transformer-based model called AgileFormer for medical image segmentation. The key innovation is a spatially agile transformer module that allows the model to adaptively focus on relevant regions of the input image.
AgileFormer combines this spatially agile transformer with a U-Net-like architecture, enabling it to effectively capture both global context and local details in the medical images. The authors show that AgileFormer outperforms other state-of-the-art models on several medical image segmentation benchmarks.
While the paper provides a strong technical contribution, further research is needed to fully understand the model's limitations and potential areas for improvement. Overall, AgileFormer represents an exciting development in the field of medical image analysis and could have significant implications for various clinical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!AgileFormer: Spatially Agile Transformer UNet for Medical Image Segmentation
Peijie Qiu, Jin Yang, Sayantan Kumar, Soumyendu Sekhar Ghosh, Aristeidis Sotiras
In the past decades, deep neural networks, particularly convolutional neural networks, have achieved state-of-the-art performance in a variety of medical image segmentation tasks. Recently, the introduction of the vision transformer (ViT) has significantly altered the landscape of deep segmentation models. There has been a growing focus on ViTs, driven by their excellent performance and scalability. However, we argue that the current design of the vision transformer-based UNet (ViT-UNet) segmentation models may not effectively handle the heterogeneous appearance (e.g., varying shapes and sizes) of objects of interest in medical image segmentation tasks. To tackle this challenge, we present a structured approach to introduce spatially dynamic components to the ViT-UNet. This adaptation enables the model to effectively capture features of target objects with diverse appearances. This is achieved by three main components: textbf{(i)} deformable patch embedding; textbf{(ii)} spatially dynamic multi-head attention; textbf{(iii)} deformable positional encoding. These components were integrated into a novel architecture, termed AgileFormer. AgileFormer is a spatially agile ViT-UNet designed for medical image segmentation. Experiments in three segmentation tasks using publicly available datasets demonstrated the effectiveness of the proposed method. The code is available at href{https://github.com/sotiraslab/AgileFormer}{https://github.com/sotiraslab/AgileFormer}.
Read more9/18/2024
0
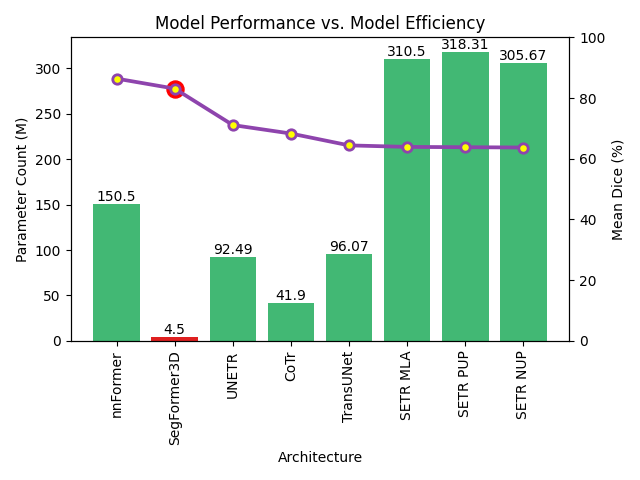
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
Shehan Perera, Pouyan Navard, Alper Yilmaz
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
Read more4/17/2024

0
DuoFormer: Leveraging Hierarchical Visual Representations by Local and Global Attention
Xiaoya Tang, Bodong Zhang, Beatrice S. Knudsen, Tolga Tasdizen
We here propose a novel hierarchical transformer model that adeptly integrates the feature extraction capabilities of Convolutional Neural Networks (CNNs) with the advanced representational potential of Vision Transformers (ViTs). Addressing the lack of inductive biases and dependence on extensive training datasets in ViTs, our model employs a CNN backbone to generate hierarchical visual representations. These representations are then adapted for transformer input through an innovative patch tokenization. We also introduce a 'scale attention' mechanism that captures cross-scale dependencies, complementing patch attention to enhance spatial understanding and preserve global perception. Our approach significantly outperforms baseline models on small and medium-sized medical datasets, demonstrating its efficiency and generalizability. The components are designed as plug-and-play for different CNN architectures and can be adapted for multiple applications. The code is available at https://github.com/xiaoyatang/DuoFormer.git.
Read more7/22/2024
🖼️
0
MaxViT-UNet: Multi-Axis Attention for Medical Image Segmentation
Abdul Rehman Khan, Asifullah Khan
Since their emergence, Convolutional Neural Networks (CNNs) have made significant strides in medical image analysis. However, the local nature of the convolution operator may pose a limitation for capturing global and long-range interactions in CNNs. Recently, Transformers have gained popularity in the computer vision community and also in medical image segmentation due to their ability to process global features effectively. The scalability issues of the self-attention mechanism and lack of the CNN-like inductive bias may have limited their adoption. Therefore, hybrid Vision transformers (CNN-Transformer), exploiting the advantages of both Convolution and Self-attention Mechanisms, have gained importance. In this work, we present MaxViT-UNet, a new Encoder-Decoder based UNet type hybrid vision transformer (CNN-Transformer) for medical image segmentation. The proposed Hybrid Decoder is designed to harness the power of both the convolution and self-attention mechanisms at each decoding stage with a nominal memory and computational burden. The inclusion of multi-axis self-attention, within each decoder stage, significantly enhances the discriminating capacity between the object and background regions, thereby helping in improving the segmentation efficiency. In the Hybrid Decoder, a new block is also proposed. The fusion process commences by integrating the upsampled lower-level decoder features, obtained through transpose convolution, with the skip-connection features derived from the hybrid encoder. Subsequently, the fused features undergo refinement through the utilization of a multi-axis attention mechanism. The proposed decoder block is repeated multiple times to segment the nuclei regions progressively. Experimental results on MoNuSeg18 and MoNuSAC20 datasets demonstrate the effectiveness of the proposed technique.
Read more4/1/2024