DuoFormer: Leveraging Hierarchical Visual Representations by Local and Global Attention

0

Sign in to get full access
Overview
- DuoFormer: A new vision transformer architecture that leverages both local and global attention mechanisms to capture hierarchical visual representations.
- Combines the strengths of convolutional neural networks (CNNs) and transformers to achieve state-of-the-art performance on various computer vision tasks.
- Introduces a novel "duo-attention" module that fuses local and global attention to efficiently extract multi-scale features.
Plain English Explanation
The DuoFormer is a new type of artificial intelligence model designed for computer vision tasks. It combines two powerful approaches: convolutional neural networks (CNNs) and transformers.
CNNs are great at capturing local patterns in images, but they struggle to recognize larger, more global structures. Transformers, on the other hand, excel at modeling long-range dependencies, but they can miss important local details.
The key innovation of DuoFormer is its "duo-attention" module, which fuses both local and global attention mechanisms. This allows the model to efficiently extract visual features at multiple scales, capturing both fine-grained details and high-level concepts.
By leveraging the strengths of both CNNs and transformers, DuoFormer achieves state-of-the-art performance on a variety of computer vision benchmarks, such as image classification, object detection, and semantic segmentation.
The researchers behind DuoFormer believe that this approach of combining different types of neural networks can lead to more powerful and versatile AI systems that can better understand the world around us.
Technical Explanation
The DuoFormer architecture is built upon the foundations of vision transformers, which have shown impressive performance on various computer vision tasks. However, traditional vision transformers can struggle to capture local spatial relationships and multi-scale visual features.
To address these limitations, the DuoFormer introduces a novel "duo-attention" module that integrates both local and global attention mechanisms. The local attention component focuses on extracting fine-grained details within local image patches, while the global attention component models long-range dependencies across the entire image.
The duo-attention module is then seamlessly integrated into the standard transformer encoder-decoder architecture, allowing the model to efficiently learn hierarchical visual representations. This combination of local and global attention enables DuoFormer to better understand the structure and semantics of visual data.
In the experimental evaluation, the researchers demonstrate that DuoFormer outperforms state-of-the-art vision transformers and convolutional neural networks on a range of computer vision tasks, including image classification, object detection, and semantic segmentation. The model's ability to capture multi-scale features and leverage both local and global information is a key factor in its strong performance.
Critical Analysis
The DuoFormer paper presents a compelling approach to leveraging the strengths of both CNNs and transformers for computer vision tasks. The authors provide a thorough evaluation of their model on a diverse set of benchmarks, demonstrating its effectiveness.
One potential area for further research is exploring the trade-offs between the complexity of the duo-attention module and the model's overall computational efficiency. While the authors claim that DuoFormer is efficient, the added complexity of the attention mechanism may impact inference speed and memory usage, especially on resource-constrained devices.
Additionally, the paper does not delve deeply into the interpretability and explainability of the DuoFormer's decision-making process. Understanding how the model arrives at its predictions could be valuable for certain applications, such as medical diagnosis or autonomous driving, where transparency is crucial.
Overall, the DuoFormer represents an interesting and promising step forward in the development of more powerful and versatile computer vision models. As the field of AI continues to evolve, research like this can help push the boundaries of what's possible and unlock new applications for these technologies.
Conclusion
The DuoFormer is a cutting-edge vision transformer architecture that combines local and global attention mechanisms to capture hierarchical visual representations. By leveraging the strengths of both CNNs and transformers, the model achieves state-of-the-art performance on a variety of computer vision tasks.
This innovative approach to fusing different neural network architectures demonstrates the potential for hybrid models to unlock new capabilities in artificial intelligence. As AI systems become more complex and versatile, research like this can lead to breakthroughs that could have far-reaching implications for industries, scientific fields, and society as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DuoFormer: Leveraging Hierarchical Visual Representations by Local and Global Attention
Xiaoya Tang, Bodong Zhang, Beatrice S. Knudsen, Tolga Tasdizen
We here propose a novel hierarchical transformer model that adeptly integrates the feature extraction capabilities of Convolutional Neural Networks (CNNs) with the advanced representational potential of Vision Transformers (ViTs). Addressing the lack of inductive biases and dependence on extensive training datasets in ViTs, our model employs a CNN backbone to generate hierarchical visual representations. These representations are then adapted for transformer input through an innovative patch tokenization. We also introduce a 'scale attention' mechanism that captures cross-scale dependencies, complementing patch attention to enhance spatial understanding and preserve global perception. Our approach significantly outperforms baseline models on small and medium-sized medical datasets, demonstrating its efficiency and generalizability. The components are designed as plug-and-play for different CNN architectures and can be adapted for multiple applications. The code is available at https://github.com/xiaoyatang/DuoFormer.git.
Read more7/22/2024

0
HAFormer: Unleashing the Power of Hierarchy-Aware Features for Lightweight Semantic Segmentation
Guoan Xu, Wenjing Jia, Tao Wu, Ligeng Chen, Guangwei Gao
Both Convolutional Neural Networks (CNNs) and Transformers have shown great success in semantic segmentation tasks. Efforts have been made to integrate CNNs with Transformer models to capture both local and global context interactions. However, there is still room for enhancement, particularly when considering constraints on computational resources. In this paper, we introduce HAFormer, a model that combines the hierarchical features extraction ability of CNNs with the global dependency modeling capability of Transformers to tackle lightweight semantic segmentation challenges. Specifically, we design a Hierarchy-Aware Pixel-Excitation (HAPE) module for adaptive multi-scale local feature extraction. During the global perception modeling, we devise an Efficient Transformer (ET) module streamlining the quadratic calculations associated with traditional Transformers. Moreover, a correlation-weighted Fusion (cwF) module selectively merges diverse feature representations, significantly enhancing predictive accuracy. HAFormer achieves high performance with minimal computational overhead and compact model size, achieving 74.2% mIoU on Cityscapes and 71.1% mIoU on CamVid test datasets, with frame rates of 105FPS and 118FPS on a single 2080Ti GPU. The source codes are available at https://github.com/XU-GITHUB-curry/HAFormer.
Read more7/12/2024
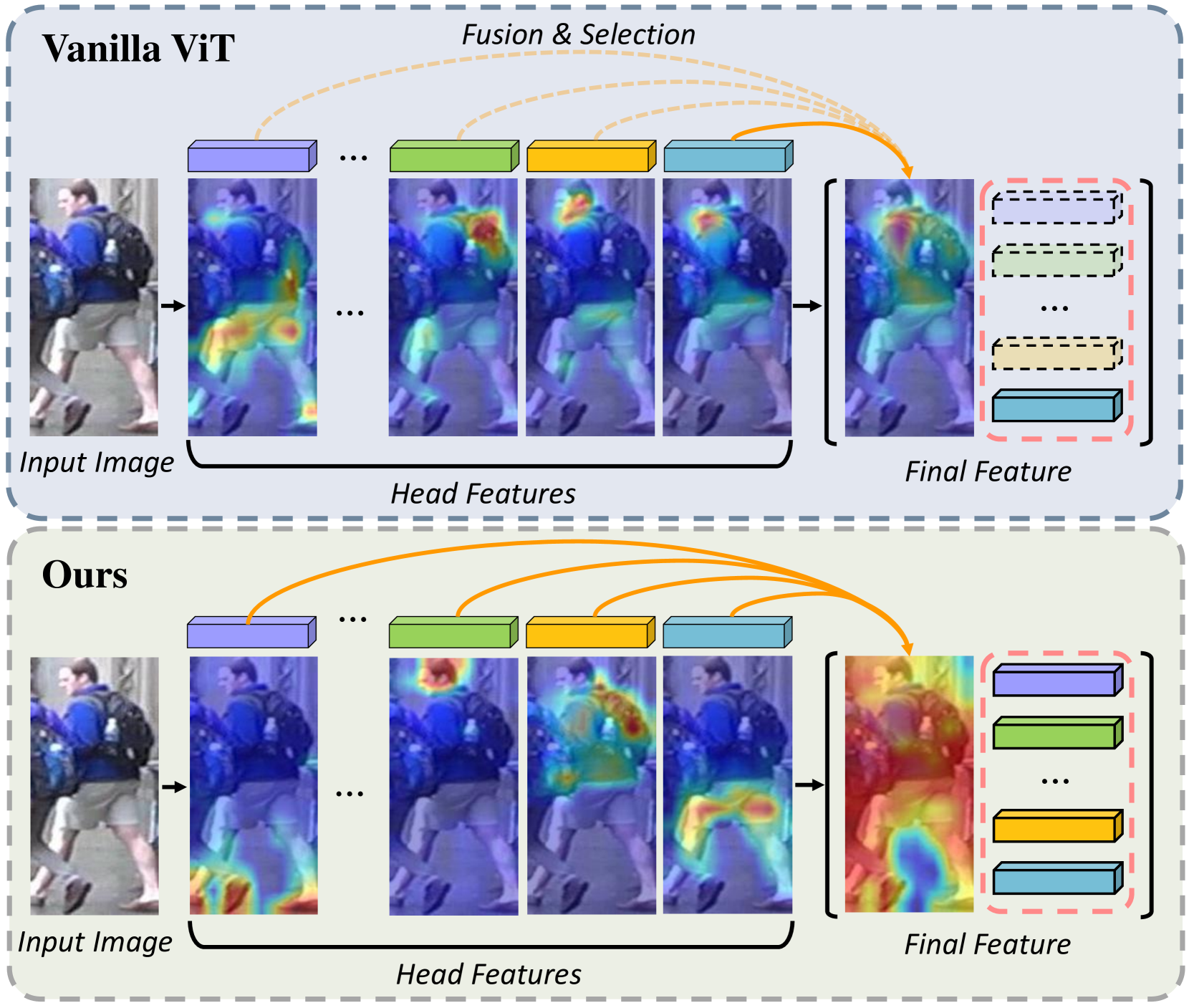
0
PartFormer: Awakening Latent Diverse Representation from Vision Transformer for Object Re-Identification
Lei Tan, Pingyang Dai, Jie Chen, Liujuan Cao, Yongjian Wu, Rongrong Ji
Extracting robust feature representation is critical for object re-identification to accurately identify objects across non-overlapping cameras. Although having a strong representation ability, the Vision Transformer (ViT) tends to overfit on most distinct regions of training data, limiting its generalizability and attention to holistic object features. Meanwhile, due to the structural difference between CNN and ViT, fine-grained strategies that effectively address this issue in CNN do not continue to be successful in ViT. To address this issue, by observing the latent diverse representation hidden behind the multi-head attention, we present PartFormer, an innovative adaptation of ViT designed to overcome the granularity limitations in object Re-ID tasks. The PartFormer integrates a Head Disentangling Block (HDB) that awakens the diverse representation of multi-head self-attention without the typical loss of feature richness induced by concatenation and FFN layers post-attention. To avoid the homogenization of attention heads and promote robust part-based feature learning, two head diversity constraints are imposed: attention diversity constraint and correlation diversity constraint. These constraints enable the model to exploit diverse and discriminative feature representations from different attention heads. Comprehensive experiments on various object Re-ID benchmarks demonstrate the superiority of the PartFormer. Specifically, our framework significantly outperforms state-of-the-art by 2.4% mAP scores on the most challenging MSMT17 dataset.
Read more8/30/2024
👀
0
Vision Transformers: From Semantic Segmentation to Dense Prediction
Li Zhang, Jiachen Lu, Sixiao Zheng, Xinxuan Zhao, Xiatian Zhu, Yanwei Fu, Tao Xiang, Jianfeng Feng, Philip H. S. Torr
The emergence of vision transformers (ViTs) in image classification has shifted the methodologies for visual representation learning. In particular, ViTs learn visual representation at full receptive field per layer across all the image patches, in comparison to the increasing receptive fields of CNNs across layers and other alternatives (e.g., large kernels and atrous convolution). In this work, for the first time we explore the global context learning potentials of ViTs for dense visual prediction (e.g., semantic segmentation). Our motivation is that through learning global context at full receptive field layer by layer, ViTs may capture stronger long-range dependency information, critical for dense prediction tasks. We first demonstrate that encoding an image as a sequence of patches, a vanilla ViT without local convolution and resolution reduction can yield stronger visual representation for semantic segmentation. For example, our model, termed as SEgmentation TRansformer (SETR), excels on ADE20K (50.28% mIoU, the first position in the test leaderboard on the day of submission) and performs competitively on Cityscapes. However, the basic ViT architecture falls short in broader dense prediction applications, such as object detection and instance segmentation, due to its lack of a pyramidal structure, high computational demand, and insufficient local context. For tackling general dense visual prediction tasks in a cost-effective manner, we further formulate a family of Hierarchical Local-Global (HLG) Transformers, characterized by local attention within windows and global-attention across windows in a pyramidal architecture. Extensive experiments show that our methods achieve appealing performance on a variety of dense prediction tasks (e.g., object detection and instance segmentation and semantic segmentation) as well as image classification.
Read more8/6/2024