AI-Assisted Human Evaluation of Machine Translation

0
Sign in to get full access
Overview
• This paper presents a novel approach to human evaluation of machine translation (MT) systems that incorporates AI-assistance to improve the efficiency and consistency of the evaluation process.
• The researchers developed a web-based tool that allows human evaluators to leverage AI models to identify and annotate translation errors, which can then be used to provide more detailed and actionable feedback to MT system developers.
Plain English Explanation
• Evaluating the performance of machine translation (MT) systems is an important but challenging task. Traditional human evaluation methods can be time-consuming, subjective, and lack consistency across evaluators.
• The researchers in this paper created an AI-assisted tool to help human evaluators more efficiently and accurately identify and annotate errors in MT output. The tool uses language models to suggest potential translation errors, which the human evaluators can then review, modify, and submit as their final evaluations.
• By combining the human expertise and judgment with the speed and consistency of AI, this approach aims to improve the quality of human evaluations and provide more valuable feedback to MT system developers.
Technical Explanation
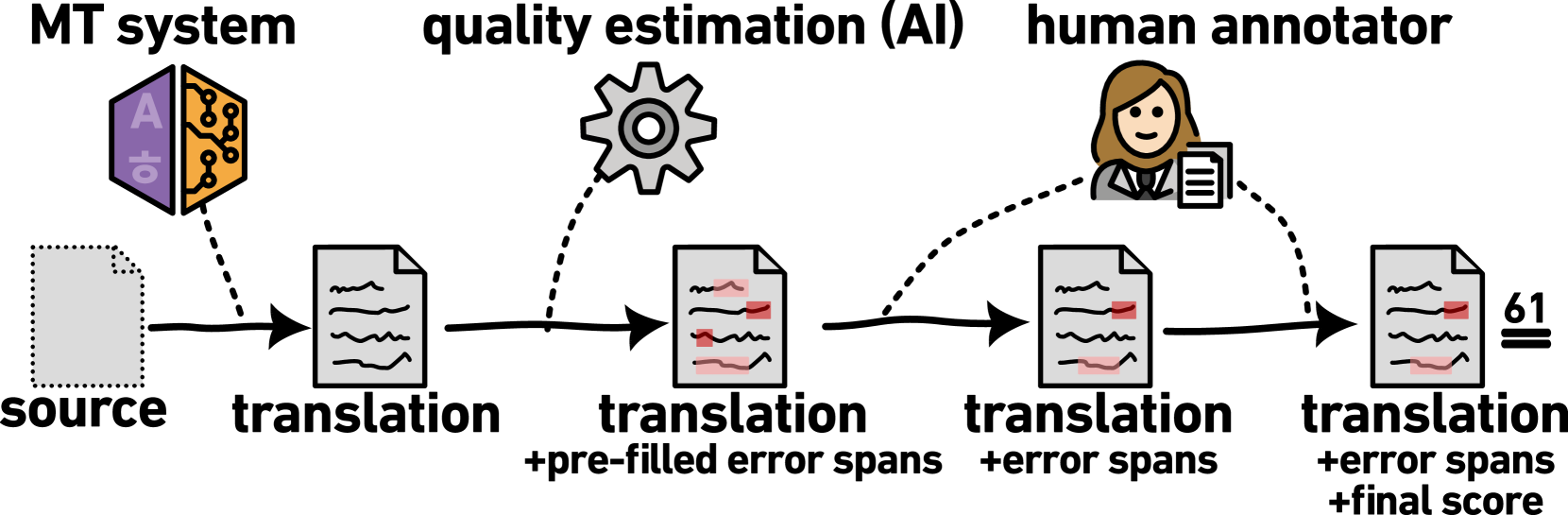
• The researchers developed a web-based tool that presents human evaluators with machine-translated text and allows them to interact with AI language models to identify and annotate translation errors.
• The tool first uses AI models to automatically suggest potential error locations and types, which the human evaluators can then review, modify, or reject as needed. This helps to streamline the evaluation process and ensures more consistent error identification across evaluators.
• The researchers conducted a series of experiments to evaluate the performance of their AI-assisted approach, comparing it to traditional human evaluation methods. Their results demonstrate that the AI-assisted approach can achieve similar levels of accuracy while significantly reducing the time and effort required from human evaluators.
Critical Analysis
• The researchers acknowledge that their approach relies on the availability and performance of the underlying AI models, which can introduce biases or errors into the evaluation process. Further research is needed to understand the impact of these factors and develop strategies to mitigate them.
• Additionally, the paper does not provide detailed information on the specific AI models used or the training data and techniques employed. This limits the ability to fully assess the generalizability and robustness of the approach.
• The researchers also note that their experiments were conducted on a relatively small scale, and additional studies with larger and more diverse datasets would be necessary to validate the findings and understand the broader applicability of the AI-assisted approach.
Conclusion
• This paper presents a promising approach to improving the efficiency and consistency of human evaluation of machine translation systems by leveraging the capabilities of AI models.
• By combining human expertise with AI-powered error identification and annotation, the researchers demonstrate the potential to streamline the evaluation process and provide more valuable feedback to MT system developers.
• While further research is needed to address the limitations and potential biases of the approach, this work represents a significant step towards more effective and scalable human evaluation of machine translation and could have important implications for the development and improvement of MT systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AI-Assisted Human Evaluation of Machine Translation
Vil'em Zouhar, Tom Kocmi, Mrinmaya Sachan
Annually, research teams spend large amounts of money to evaluate the quality of machine translation systems (WMT, inter alia). This is expensive because it requires detailed human labor. The recently proposed annotation protocol, Error Span Annotation (ESA), has annotators marking erroneous parts of the translation. In our work, we help the annotators by pre-filling the span annotations with automatic quality estimation. With AI assistance, we obtain more detailed annotations while cutting down the time per span annotation by half (71s/error span $rightarrow$ 31s/error span). The biggest advantage of ESA$^mathrm{AI}$ protocol is an accurate priming of annotators (pre-filled error spans) before they assign the final score as opposed to starting from scratch. In addition, the annotation budget can be reduced by up to 24% with filtering of examples that the AI deems to be very likely to be correct.
Read more6/19/2024

0
Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation
Tom Kocmi, Vil'em Zouhar, Eleftherios Avramidis, Roman Grundkiewicz, Marzena Karpinska, Maja Popovi'c, Mrinmaya Sachan, Mariya Shmatova
High-quality Machine Translation (MT) evaluation relies heavily on human judgments. Comprehensive error classification methods, such as Multidimensional Quality Metrics (MQM), are expensive as they are time-consuming and can only be done by experts, whose availability may be limited especially for low-resource languages. On the other hand, just assigning overall scores, like Direct Assessment (DA), is simpler and faster and can be done by translators of any level, but are less reliable. In this paper, we introduce Error Span Annotation (ESA), a human evaluation protocol which combines the continuous rating of DA with the high-level error severity span marking of MQM. We validate ESA by comparing it to MQM and DA for 12 MT systems and one human reference translation (English to German) from WMT23. The results show that ESA offers faster and cheaper annotations than MQM at the same quality level, without the requirement of expensive MQM experts.
Read more6/18/2024
0
Evaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation
Matthias Sperber, Ondv{r}ej Bojar, Barry Haddow, D'avid Javorsk'y, Xutai Ma, Matteo Negri, Jan Niehues, Peter Pol'ak, Elizabeth Salesky, Katsuhito Sudoh, Marco Turchi
Human evaluation is a critical component in machine translation system development and has received much attention in text translation research. However, little prior work exists on the topic of human evaluation for speech translation, which adds additional challenges such as noisy data and segmentation mismatches. We take first steps to fill this gap by conducting a comprehensive human evaluation of the results of several shared tasks from the last International Workshop on Spoken Language Translation (IWSLT 2023). We propose an effective evaluation strategy based on automatic resegmentation and direct assessment with segment context. Our analysis revealed that: 1) the proposed evaluation strategy is robust and scores well-correlated with other types of human judgements; 2) automatic metrics are usually, but not always, well-correlated with direct assessment scores; and 3) COMET as a slightly stronger automatic metric than chrF, despite the segmentation noise introduced by the resegmentation step systems. We release the collected human-annotated data in order to encourage further investigation.
Read more6/7/2024

0
Exploring the Correlation between Human and Machine Evaluation of Simultaneous Speech Translation
Xiaoman Wang, Claudio Fantinuoli
Assessing the performance of interpreting services is a complex task, given the nuanced nature of spoken language translation, the strategies that interpreters apply, and the diverse expectations of users. The complexity of this task become even more pronounced when automated evaluation methods are applied. This is particularly true because interpreted texts exhibit less linearity between the source and target languages due to the strategies employed by the interpreter. This study aims to assess the reliability of automatic metrics in evaluating simultaneous interpretations by analyzing their correlation with human evaluations. We focus on a particular feature of interpretation quality, namely translation accuracy or faithfulness. As a benchmark we use human assessments performed by language experts, and evaluate how well sentence embeddings and Large Language Models correlate with them. We quantify semantic similarity between the source and translated texts without relying on a reference translation. The results suggest GPT models, particularly GPT-3.5 with direct prompting, demonstrate the strongest correlation with human judgment in terms of semantic similarity between source and target texts, even when evaluating short textual segments. Additionally, the study reveals that the size of the context window has a notable impact on this correlation.
Read more6/17/2024