Evaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation

0
Sign in to get full access
Overview
- This paper evaluates the speech translation tasks in the IWSLT 2023 evaluation campaign, examining human annotations, automatic metrics, and segmentation approaches.
- The authors analyze the convergences and divergences between human and automatic evaluations, explore the use of meta-evaluation techniques, and investigate the ability of automatic metrics to assess high-quality translations.
- The paper also explores reference-less evaluation approaches and the use of large language models for evaluating conversational assistants.
Plain English Explanation
The researchers in this study looked at how well different methods can evaluate the quality of machine translations for spoken language. They compared assessments made by human experts to the scores given by automated evaluation tools. The goal was to understand where these approaches agree and disagree, and how well the automatic metrics can capture the nuances of high-quality translations.
The researchers also explored some more advanced evaluation techniques, like using meta-evaluation to assess the evaluation methods themselves and moving towards reference-less evaluation where the translations are judged without relying on a reference human translation. Additionally, they investigated using large language models to automatically evaluate conversational assistants.
Overall, the study provides insights into the strengths and limitations of different translation evaluation approaches, and points towards future directions for improving how we assess the performance of machine translation systems, especially for spoken language tasks.
Technical Explanation
The paper evaluates the speech translation tasks in the IWSLT 2023 evaluation campaign, examining human annotations, automatic metrics, and segmentation approaches. The authors analyze the convergences and divergences between human and automatic evaluations, exploring the use of meta-evaluation techniques to assess the evaluation methods themselves.
The researchers also investigate the ability of automatic metrics to assess high-quality translations, and explore reference-less evaluation approaches that do not rely on human-translated references. Additionally, they look at using large language models to automatically evaluate conversational assistants.
The paper provides a comprehensive analysis of the current state of speech translation evaluation, highlighting areas where human and automatic assessments converge and diverge, and exploring innovative techniques for more robust and comprehensive evaluation of machine translation systems.
Critical Analysis
The paper presents a thorough and thoughtful analysis of speech translation evaluation, acknowledging the limitations of existing approaches and exploring promising new directions. However, the authors note that further research is needed to fully understand the relationship between human and automatic evaluations, and to develop reliable reference-less evaluation methods.
One potential issue is the reliance on a single language pair (English-German) in the experiments. Expanding the analysis to include a wider range of language pairs could provide additional insights and help validate the findings.
Additionally, the authors do not delve into the potential biases or blindspots of the large language models used in the reference-less and conversational assistant evaluation approaches. Further investigation into the reliability and fairness of these models would be valuable.
Overall, the paper makes a significant contribution to the field of machine translation evaluation, but there remain open questions and areas for future research to build upon this work.
Conclusion
This study provides a comprehensive evaluation of the speech translation tasks in the IWSLT 2023 campaign, examining the convergences and divergences between human and automatic assessment, exploring meta-evaluation techniques, and investigating the strengths and limitations of various evaluation approaches.
The findings suggest that while automatic metrics can capture some aspects of translation quality, they may struggle to fully reflect the nuances of high-quality translations. The researchers also make progress towards reference-less evaluation and the use of large language models for assessing conversational assistants, opening up new avenues for more robust and comprehensive evaluation of machine translation systems.
Overall, this study contributes valuable insights to the ongoing effort to develop effective and reliable methods for evaluating the performance of machine translation, especially in the context of spoken language tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Evaluating the IWSLT2023 Speech Translation Tasks: Human Annotations, Automatic Metrics, and Segmentation
Matthias Sperber, Ondv{r}ej Bojar, Barry Haddow, D'avid Javorsk'y, Xutai Ma, Matteo Negri, Jan Niehues, Peter Pol'ak, Elizabeth Salesky, Katsuhito Sudoh, Marco Turchi
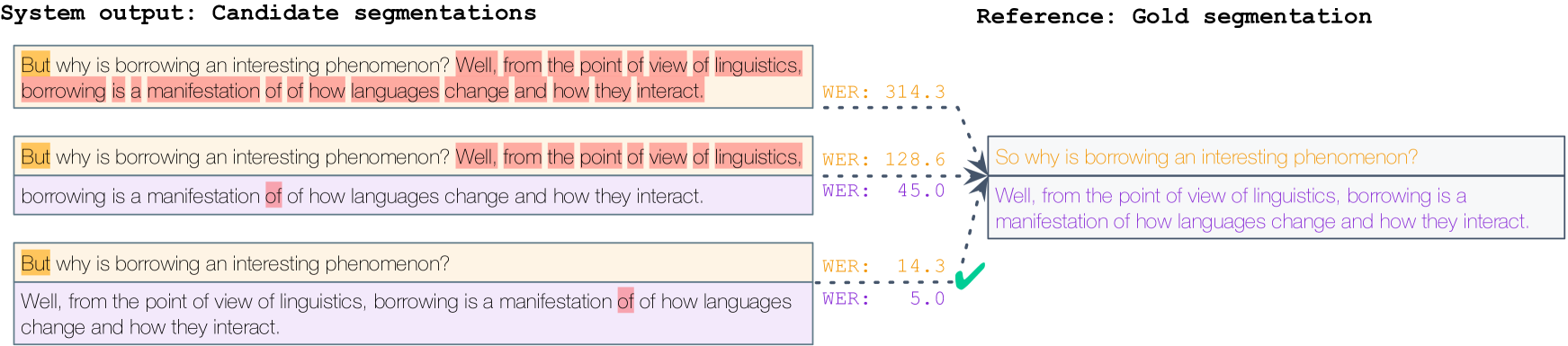
Human evaluation is a critical component in machine translation system development and has received much attention in text translation research. However, little prior work exists on the topic of human evaluation for speech translation, which adds additional challenges such as noisy data and segmentation mismatches. We take first steps to fill this gap by conducting a comprehensive human evaluation of the results of several shared tasks from the last International Workshop on Spoken Language Translation (IWSLT 2023). We propose an effective evaluation strategy based on automatic resegmentation and direct assessment with segment context. Our analysis revealed that: 1) the proposed evaluation strategy is robust and scores well-correlated with other types of human judgements; 2) automatic metrics are usually, but not always, well-correlated with direct assessment scores; and 3) COMET as a slightly stronger automatic metric than chrF, despite the segmentation noise introduced by the resegmentation step systems. We release the collected human-annotated data in order to encourage further investigation.
Read more6/7/2024

0
Exploring the Correlation between Human and Machine Evaluation of Simultaneous Speech Translation
Xiaoman Wang, Claudio Fantinuoli
Assessing the performance of interpreting services is a complex task, given the nuanced nature of spoken language translation, the strategies that interpreters apply, and the diverse expectations of users. The complexity of this task become even more pronounced when automated evaluation methods are applied. This is particularly true because interpreted texts exhibit less linearity between the source and target languages due to the strategies employed by the interpreter. This study aims to assess the reliability of automatic metrics in evaluating simultaneous interpretations by analyzing their correlation with human evaluations. We focus on a particular feature of interpretation quality, namely translation accuracy or faithfulness. As a benchmark we use human assessments performed by language experts, and evaluate how well sentence embeddings and Large Language Models correlate with them. We quantify semantic similarity between the source and translated texts without relying on a reference translation. The results suggest GPT models, particularly GPT-3.5 with direct prompting, demonstrate the strongest correlation with human judgment in terms of semantic similarity between source and target texts, even when evaluating short textual segments. Additionally, the study reveals that the size of the context window has a notable impact on this correlation.
Read more6/17/2024

0
Convergences and Divergences between Automatic Assessment and Human Evaluation: Insights from Comparing ChatGPT-Generated Translation and Neural Machine Translation
Zhaokun Jiang, Ziyin Zhang
Large language models have demonstrated parallel and even superior translation performance compared to neural machine translation (NMT) systems. However, existing comparative studies between them mainly rely on automated metrics, raising questions into the feasibility of these metrics and their alignment with human judgment. The present study investigates the convergences and divergences between automated metrics and human evaluation in assessing the quality of machine translation from ChatGPT and three NMT systems. To perform automatic assessment, four automated metrics are employed, while human evaluation incorporates the DQF-MQM error typology and six rubrics. Notably, automatic assessment and human evaluation converge in measuring formal fidelity (e.g., error rates), but diverge when evaluating semantic and pragmatic fidelity, with automated metrics failing to capture the improvement of ChatGPT's translation brought by prompt engineering. These results underscore the indispensable role of human judgment in evaluating the performance of advanced translation tools at the current stage.
Read more4/24/2024
0
AI-Assisted Human Evaluation of Machine Translation
Vil'em Zouhar, Tom Kocmi, Mrinmaya Sachan
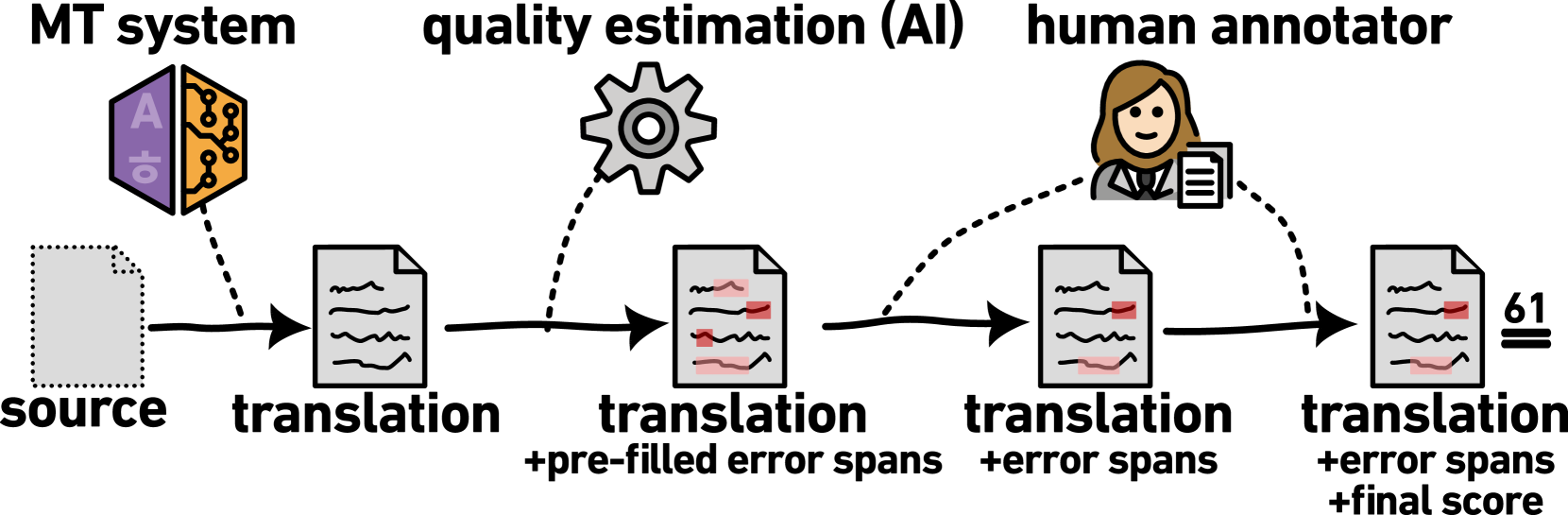
Annually, research teams spend large amounts of money to evaluate the quality of machine translation systems (WMT, inter alia). This is expensive because it requires detailed human labor. The recently proposed annotation protocol, Error Span Annotation (ESA), has annotators marking erroneous parts of the translation. In our work, we help the annotators by pre-filling the span annotations with automatic quality estimation. With AI assistance, we obtain more detailed annotations while cutting down the time per span annotation by half (71s/error span $rightarrow$ 31s/error span). The biggest advantage of ESA$^mathrm{AI}$ protocol is an accurate priming of annotators (pre-filled error spans) before they assign the final score as opposed to starting from scratch. In addition, the annotation budget can be reduced by up to 24% with filtering of examples that the AI deems to be very likely to be correct.
Read more6/19/2024