Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation

0

Sign in to get full access
Overview
- This paper presents a novel approach called "Error Span Annotation" (ESA) for human evaluation of machine translation quality.
- ESA aims to provide a more balanced and comprehensive way to assess translation errors compared to existing methods.
- The authors argue that ESA can capture a wider range of error types and provide richer feedback to improve translation systems.
Plain English Explanation
The paper introduces a new way to evaluate the quality of machine-translated text, called "Error Span Annotation" (ESA). Traditional methods of human evaluation often focus on counting the number of errors in a translation, but this can miss important nuances. With ESA, human evaluators don't just identify errors - they also mark the specific words or phrases that contain the errors. This gives more detailed feedback on the types of errors and their severity.
The authors believe ESA is a more balanced approach that can provide richer information to help improve machine translation systems. By pinpointing where errors occur and what kind of errors they are, ESA can give developers clearer guidance on how to refine their translation models. This is an important step beyond simply counting the number of errors, which doesn't always tell the full story.
The paper also compares ESA to other human evaluation methods, such as Multi-Range Theory for Translation Quality Measurement (MQM) and Guiding Large Language Models to Post-Edit. The authors argue that ESA offers a more comprehensive and balanced perspective that can lead to better translation quality in the long run.
Technical Explanation
The key innovation of this paper is the Error Span Annotation (ESA) method for human evaluation of machine translation. In ESA, annotators not only identify translation errors, but also mark the specific words or phrases containing those errors.
This contrasts with more traditional approaches like IWSLT 2023 speech translation task human annotations, which focus primarily on counting the number of errors. ESA provides richer feedback by capturing the type and severity of each error.
The authors conducted experiments comparing ESA to other methods like MQM and error analysis prompting. They found that ESA achieves a better balance between identifying errors and providing constructive feedback for improving translation systems.
Additionally, the authors addressed the challenge of revisiting meta-evaluation for grammatical error correction by designing ESA to capture a wider range of error types beyond just grammatical issues.
Critical Analysis
The authors make a compelling case for the benefits of ESA over existing human evaluation methods. By providing more granular and balanced feedback, ESA has the potential to drive meaningful improvements in machine translation quality.
However, the paper does not extensively explore the potential limitations or challenges of implementing ESA. For example, the additional cognitive load on human annotators and the potential for inconsistencies in error identification and span annotation are not discussed in depth.
Furthermore, the paper would be strengthened by a more thorough discussion of the practical implications and scalability of ESA. As machine translation systems become increasingly complex, the feasibility of large-scale human evaluation using ESA warrants further investigation.
Conclusion
This paper introduces a novel approach called "Error Span Annotation" (ESA) that aims to provide a more balanced and comprehensive way to assess the quality of machine-translated text through human evaluation. By having annotators identify not just errors, but the specific words or phrases containing those errors, ESA can give developers richer feedback to improve their translation models.
The authors present compelling evidence that ESA outperforms traditional error-counting methods and other approaches like MQM and error analysis prompting. While the paper does not fully explore the potential limitations of ESA, it offers a valuable contribution to the field of machine translation evaluation and suggests a promising direction for future research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation
Tom Kocmi, Vil'em Zouhar, Eleftherios Avramidis, Roman Grundkiewicz, Marzena Karpinska, Maja Popovi'c, Mrinmaya Sachan, Mariya Shmatova
High-quality Machine Translation (MT) evaluation relies heavily on human judgments. Comprehensive error classification methods, such as Multidimensional Quality Metrics (MQM), are expensive as they are time-consuming and can only be done by experts, whose availability may be limited especially for low-resource languages. On the other hand, just assigning overall scores, like Direct Assessment (DA), is simpler and faster and can be done by translators of any level, but are less reliable. In this paper, we introduce Error Span Annotation (ESA), a human evaluation protocol which combines the continuous rating of DA with the high-level error severity span marking of MQM. We validate ESA by comparing it to MQM and DA for 12 MT systems and one human reference translation (English to German) from WMT23. The results show that ESA offers faster and cheaper annotations than MQM at the same quality level, without the requirement of expensive MQM experts.
Read more6/18/2024
0
AI-Assisted Human Evaluation of Machine Translation
Vil'em Zouhar, Tom Kocmi, Mrinmaya Sachan
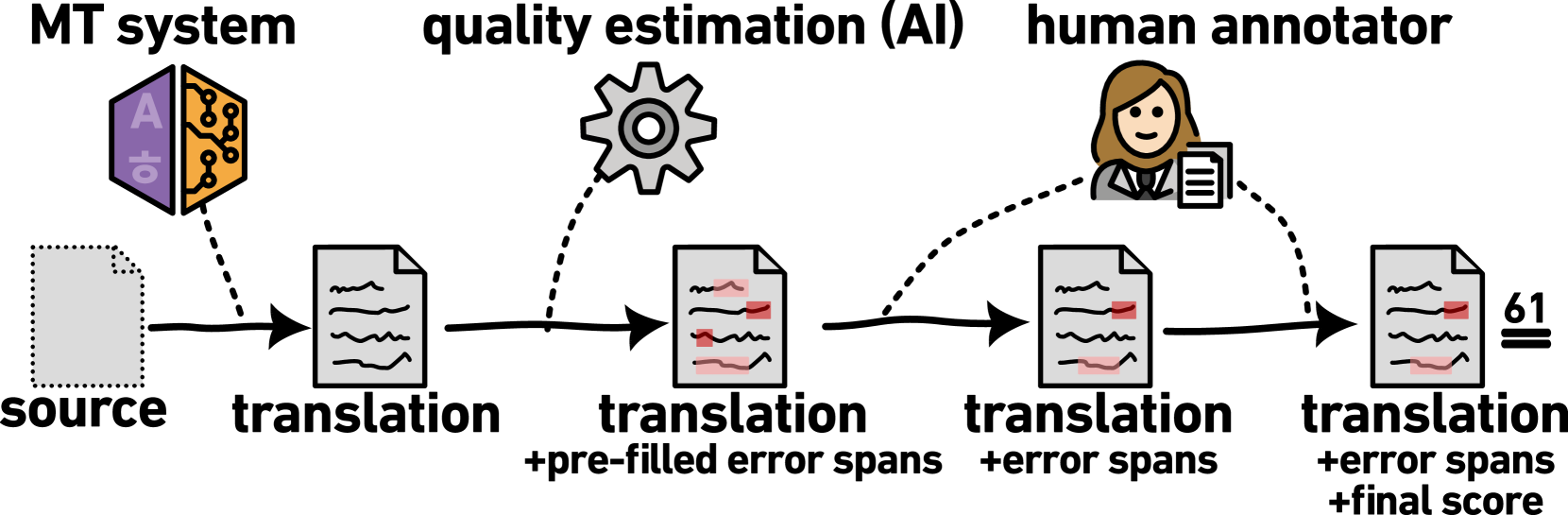
Annually, research teams spend large amounts of money to evaluate the quality of machine translation systems (WMT, inter alia). This is expensive because it requires a lot of expert human labor. The recently adopted annotation protocol, Error Span Annotation (ESA), has annotators marking erroneous parts of the translation and then assigning a final score. A lot of the annotator time is spent on scanning the translation for possible errors. In our work, we help the annotators by pre-filling the error annotations with recall-oriented automatic quality estimation. With this AI assistance, we obtain annotations at the same quality level while cutting down the time per span annotation by half (71s/error span $rightarrow$ 31s/error span). The biggest advantage of ESA$^mathrm{AI}$ protocol is an accurate priming of annotators (pre-filled error spans) before they assign the final score. This also alleviates a potential automation bias, which we confirm to be low. In addition, the annotation budget can be reduced by almost 25% with filtering of examples that the AI deems to be very likely to be correct.
Read more9/18/2024

0
The Multi-Range Theory of Translation Quality Measurement: MQM scoring models and Statistical Quality Control
Arle Lommel, Serge Gladkoff, Alan Melby, Sue Ellen Wright, Ingemar Strandvik, Katerina Gasova, Angelika Vaasa, Andy Benzo, Romina Marazzato Sparano, Monica Foresi, Johani Innis, Lifeng Han, Goran Nenadic
The year 2024 marks the 10th anniversary of the Multidimensional Quality Metrics (MQM) framework for analytic translation quality evaluation. The MQM error typology has been widely used by practitioners in the translation and localization industry and has served as the basis for many derivative projects. The annual Conference on Machine Translation (WMT) shared tasks on both human and automatic translation quality evaluations used the MQM error typology. The metric stands on two pillars: error typology and the scoring model. The scoring model calculates the quality score from annotation data, detailing how to convert error type and severity counts into numeric scores to determine if the content meets specifications. Previously, only the raw scoring model had been published. This April, the MQM Council published the Linear Calibrated Scoring Model, officially presented herein, along with the Non-Linear Scoring Model, which had not been published before. This paper details the latest MQM developments and presents a universal approach to translation quality measurement across three sample size ranges. It also explains why Statistical Quality Control should be used for very small sample sizes, starting from a single sentence.
Read more6/11/2024
0
Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
Dayeon Ki, Marine Carpuat
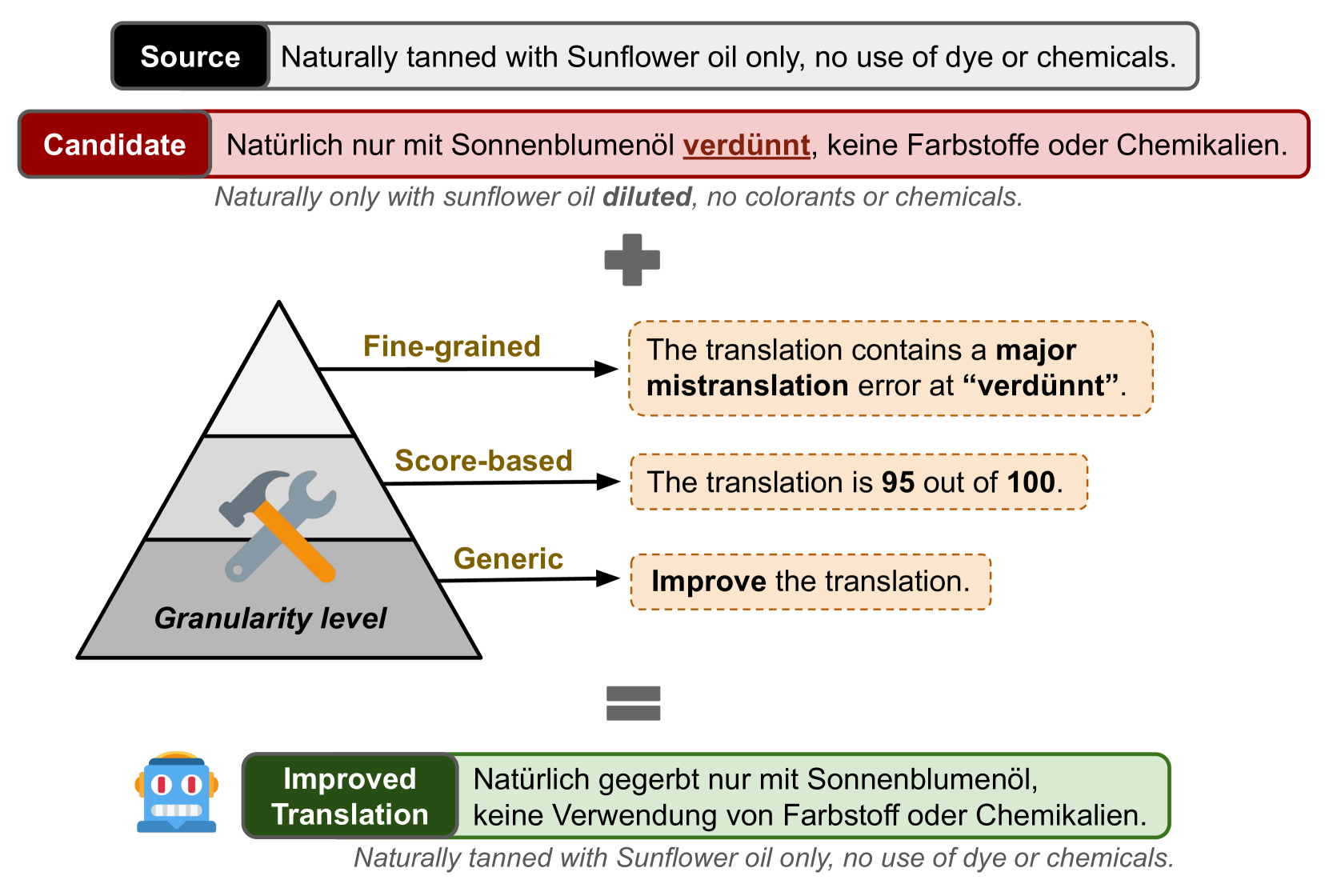
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
Read more4/12/2024