AI-Augmented Predictions: LLM Assistants Improve Human Forecasting Accuracy

0
🎯
Sign in to get full access
Overview
- Large language models (LLMs) can match or exceed human performance in many tasks.
- This study explores using LLM assistants to enhance human forecasting abilities.
- Two LLM assistants were evaluated: one designed for high-quality "superforecasting" advice, and one designed to provide noisy, overconfident advice.
- Participants used these assistants to answer a set of forecasting questions and their accuracy was compared to a control group.
Plain English Explanation
The researchers wanted to see if large language models could help people make better predictions or forecasts. They had two different AI assistants that used advanced language models - one that was designed to give high-quality, expert-level forecasting advice, and another that was designed to give noisy, overconfident advice.
The participants in the study answered a set of forecasting questions, and they could choose to get help from one of the AI assistants as they answered the questions. The researchers compared the accuracy of the participants who used the AI assistants to a control group that used a less advanced model that didn't provide specific forecasting advice.
The results showed that using either of the frontier AI assistants, even the one giving noisy advice, significantly improved the participants' forecasting accuracy compared to the control group. The superforecasting assistant led to a 41% increase in accuracy, while the noisy assistant led to a 29% increase. However, the researchers noted that the effects were sensitive to outliers, so more research is needed to fully understand the robustness of these findings.
Technical Explanation
The researchers conducted an experiment to evaluate the impact of LLM forecasting assistants on human judgment. They had two frontier LLM assistants: one designed for "superforecasting" quality advice, and another designed to provide noisy, overconfident forecasting.
Participants (N = 991) answered a set of six forecasting questions and had the option to consult their assigned LLM assistant. The preregistered analyses showed that interacting with each of the frontier LLM assistants significantly enhanced prediction accuracy by 24-28% compared to a control group that used a less advanced model without numerical predictions or explicit discussion of forecasts.
Exploratory analyses revealed a pronounced outlier effect in one forecasting item. Without this outlier, the superforecasting assistant increased accuracy by 41%, while the noisy assistant increased it by 29%. The researchers also examined whether the LLM assistance disproportionately benefited less skilled forecasters, reduced prediction diversity, or varied in effectiveness with question difficulty, but the data did not consistently support these hypotheses.
Critical Analysis
The researchers acknowledge that the effects of the frontier LLM assistants appear sensitive to outliers, suggesting the need for further research into the robustness of these patterns. Additionally, while the study demonstrates the potential for LLM assistants to enhance human forecasting, the researchers note that the long-term effects on judgment and decision-making processes require deeper investigation.
One potential concern not addressed in the paper is the degree to which the participants may have become overly reliant on the LLM assistants, potentially degrading their own forecasting skills over time. Further research could explore the long-term impacts of such AI-human collaboration on individual and collective forecasting abilities.
Conclusion
This study provides promising evidence that access to frontier LLM assistants can significantly enhance human forecasting abilities, even when the assistants provide noisy advice. However, the sensitivity to outliers and potential long-term effects on judgment and decision-making processes warrant further investigation. As AI systems become more advanced, understanding how to effectively integrate human and machine intelligence will be crucial for optimizing decision-making in complex, real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
0
AI-Augmented Predictions: LLM Assistants Improve Human Forecasting Accuracy
Philipp Schoenegger, Peter S. Park, Ezra Karger, Sean Trott, Philip E. Tetlock
Large language models (LLMs) match and sometimes exceeding human performance in many domains. This study explores the potential of LLMs to augment human judgement in a forecasting task. We evaluate the effect on human forecasters of two LLM assistants: one designed to provide high-quality (superforecasting) advice, and the other designed to be overconfident and base-rate neglecting, thus providing noisy forecasting advice. We compare participants using these assistants to a control group that received a less advanced model that did not provide numerical predictions or engaged in explicit discussion of predictions. Participants (N = 991) answered a set of six forecasting questions and had the option to consult their assigned LLM assistant throughout. Our preregistered analyses show that interacting with each of our frontier LLM assistants significantly enhances prediction accuracy by between 24 percent and 28 percent compared to the control group. Exploratory analyses showed a pronounced outlier effect in one forecasting item, without which we find that the superforecasting assistant increased accuracy by 41 percent, compared with 29 percent for the noisy assistant. We further examine whether LLM forecasting augmentation disproportionately benefits less skilled forecasters, degrades the wisdom-of-the-crowd by reducing prediction diversity, or varies in effectiveness with question difficulty. Our data do not consistently support these hypotheses. Our results suggest that access to a frontier LLM assistant, even a noisy one, can be a helpful decision aid in cognitively demanding tasks compared to a less powerful model that does not provide specific forecasting advice. However, the effects of outliers suggest that further research into the robustness of this pattern is needed.
Read more8/23/2024
💬
0
Humans vs Large Language Models: Judgmental Forecasting in an Era of Advanced AI
MAhdi Abolghasemi, Odkhishig Ganbold, Kristian Rotaru
This study investigates the forecasting accuracy of human experts versus Large Language Models (LLMs) in the retail sector, particularly during standard and promotional sales periods. Utilizing a controlled experimental setup with 123 human forecasters and five LLMs, including ChatGPT4, ChatGPT3.5, Bard, Bing, and Llama2, we evaluated forecasting precision through Mean Absolute Percentage Error. Our analysis centered on the effect of the following factors on forecasters performance: the supporting statistical model (baseline and advanced), whether the product was on promotion, and the nature of external impact. The findings indicate that LLMs do not consistently outperform humans in forecasting accuracy and that advanced statistical forecasting models do not uniformly enhance the performance of either human forecasters or LLMs. Both human and LLM forecasters exhibited increased forecasting errors, particularly during promotional periods and under the influence of positive external impacts. Our findings call for careful consideration when integrating LLMs into practical forecasting processes.
Read more5/20/2024
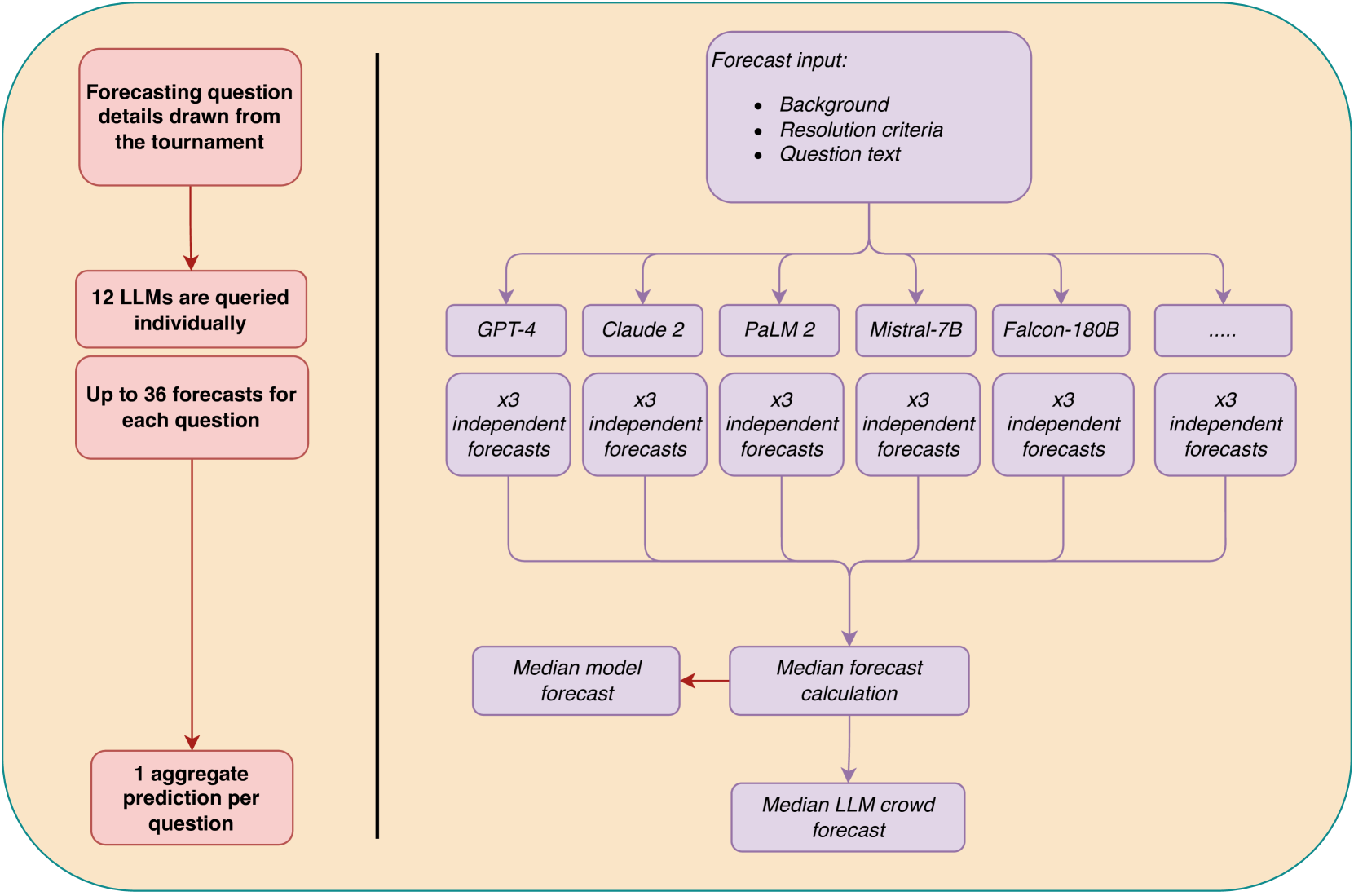
0
Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy
Philipp Schoenegger, Indre Tuminauskaite, Peter S. Park, Rafael Valdece Sousa Bastos, Philip E. Tetlock
Human forecasting accuracy in practice relies on the 'wisdom of the crowd' effect, in which predictions about future events are significantly improved by aggregating across a crowd of individual forecasters. Past work on the forecasting ability of large language models (LLMs) suggests that frontier LLMs, as individual forecasters, underperform compared to the gold standard of a human-crowd forecasting-tournament aggregate. In Study 1, we expand this research by using an LLM ensemble approach consisting of a crowd of 12 LLMs. We compare the aggregated LLM predictions on 31 binary questions to those of a crowd of 925 human forecasters from a three-month forecasting tournament. Our preregistered main analysis shows that the LLM crowd outperforms a simple no-information benchmark, and is not statistically different from the human crowd. We also observe a set of human-like biases in machine responses, such as an acquiescence effect and a tendency to favour round numbers. In Study 2, we test whether LLM predictions (of GPT-4 and Claude 2) can be improved by drawing on human cognitive output. We find that both models' forecasting accuracy benefits from exposure to the median human prediction as information, improving accuracy by between 17% and 28%, though this leads to less accurate predictions than simply averaging human and machine forecasts. Our results suggest that LLMs can achieve forecasting accuracy rivaling that of the human crowd: via the simple, practically applicable method of forecast aggregation.
Read more6/18/2024

0
Can Language Models Use Forecasting Strategies?
Sarah Pratt, Seth Blumberg, Pietro Kreitlon Carolino, Meredith Ringel Morris
Advances in deep learning systems have allowed large models to match or surpass human accuracy on a number of skills such as image classification, basic programming, and standardized test taking. As the performance of the most capable models begin to saturate on tasks where humans already achieve high accuracy, it becomes necessary to benchmark models on increasingly complex abilities. One such task is forecasting the future outcome of events. In this work we describe experiments using a novel dataset of real world events and associated human predictions, an evaluation metric to measure forecasting ability, and the accuracy of a number of different LLM based forecasting designs on the provided dataset. Additionally, we analyze the performance of the LLM forecasters against human predictions and find that models still struggle to make accurate predictions about the future. Our follow-up experiments indicate this is likely due to models' tendency to guess that most events are unlikely to occur (which tends to be true for many prediction datasets, but does not reflect actual forecasting abilities). We reflect on next steps for developing a systematic and reliable approach to studying LLM forecasting.
Read more6/10/2024