Confidence-weighted integration of human and machine judgments for superior decision-making

0

Sign in to get full access
Overview
- Integrates human and machine judgments to improve decision-making
- Weighs the confidence of each input to determine the optimal combination
- Aims to leverage the strengths of both human and AI systems
Plain English Explanation
The paper describes a method for combining human and machine judgments in a way that takes into account the confidence of each input. The key idea is that by weighing the inputs based on their confidence, the system can make more accurate decisions than relying on either humans or machines alone.
This approach acknowledges that both human and AI judgments can be biased or mistaken, so by considering the confidence level of each, the system can determine the optimal combination. The goal is to leverage the unique strengths of both to arrive at superior decisions.
Technical Explanation
The paper proposes a framework for confidence-weighted integration of human and machine judgments. The key steps are:
- Elicit judgments from both human experts and AI models on a given task or decision.
- Estimate the confidence level associated with each judgment, based on factors like past performance, domain expertise, and model uncertainty.
- Combine the judgments using a weighted average, where the weights are proportional to the confidence levels.
The authors demonstrate the effectiveness of this approach through experiments on several real-world decision-making tasks. They show that the confidence-weighted integration outperforms relying on either human or machine judgments alone.
Critical Analysis
The paper acknowledges some limitations of the proposed approach, such as the challenge of accurately estimating confidence levels, especially for complex AI models. There is also the potential for biases or errors in the human judgments to be amplified if not properly accounted for.
Additionally, the paper does not extensively explore the long-term implications of this approach, such as how it might affect the roles and interactions between humans and machines in decision-making processes.
Conclusion
This research presents a promising approach for integrating human and machine judgments to improve decision-making. By considering the confidence levels of each input, the system can leverage the strengths of both and arrive at superior decisions. While the method has some limitations, it represents an important step towards effective human-AI collaboration in high-stakes decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Confidence-weighted integration of human and machine judgments for superior decision-making
Felipe Y'a~nez, Xiaoliang Luo, Omar Valerio Minero, Bradley C. Love
Large language models (LLMs) have emerged as powerful tools in various domains. Recent studies have shown that LLMs can surpass humans in certain tasks, such as predicting the outcomes of neuroscience studies. What role does this leave for humans in the overall decision process? One possibility is that humans, despite performing worse than LLMs, can still add value when teamed with them. A human and machine team can surpass each individual teammate when team members' confidence is well-calibrated and team members diverge in which tasks they find difficult (i.e., calibration and diversity are needed). We simplified and extended a Bayesian approach to combining judgments using a logistic regression framework that integrates confidence-weighted judgments for any number of team members. Using this straightforward method, we demonstrated in a neuroscience forecasting task that, even when humans were inferior to LLMs, their combination with one or more LLMs consistently improved team performance. Our hope is that this simple and effective strategy for integrating the judgments of humans and machines will lead to productive collaborations.
Read more8/16/2024
0
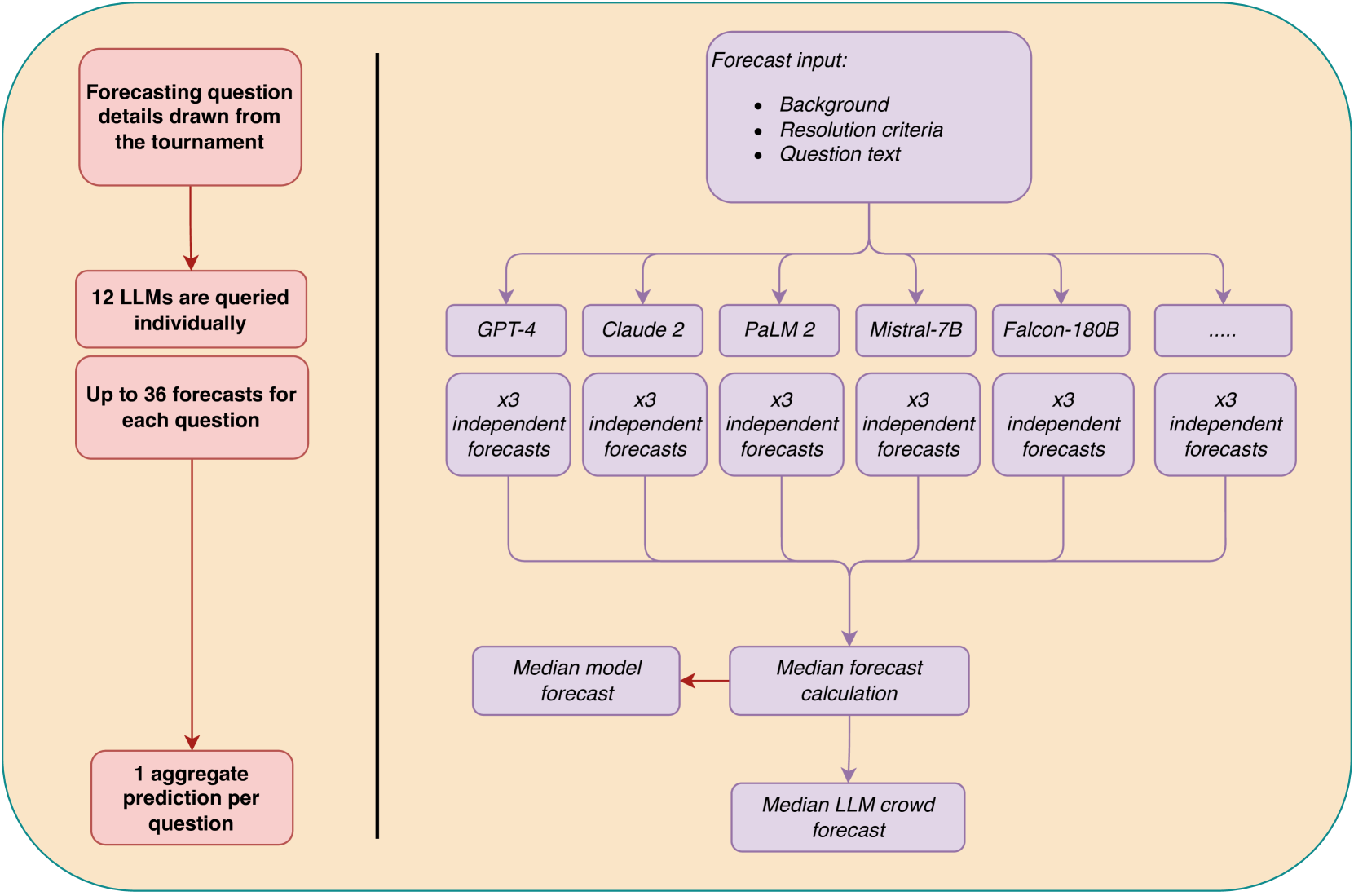
Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy
Philipp Schoenegger, Indre Tuminauskaite, Peter S. Park, Rafael Valdece Sousa Bastos, Philip E. Tetlock
Human forecasting accuracy in practice relies on the 'wisdom of the crowd' effect, in which predictions about future events are significantly improved by aggregating across a crowd of individual forecasters. Past work on the forecasting ability of large language models (LLMs) suggests that frontier LLMs, as individual forecasters, underperform compared to the gold standard of a human-crowd forecasting-tournament aggregate. In Study 1, we expand this research by using an LLM ensemble approach consisting of a crowd of 12 LLMs. We compare the aggregated LLM predictions on 31 binary questions to those of a crowd of 925 human forecasters from a three-month forecasting tournament. Our preregistered main analysis shows that the LLM crowd outperforms a simple no-information benchmark, and is not statistically different from the human crowd. We also observe a set of human-like biases in machine responses, such as an acquiescence effect and a tendency to favour round numbers. In Study 2, we test whether LLM predictions (of GPT-4 and Claude 2) can be improved by drawing on human cognitive output. We find that both models' forecasting accuracy benefits from exposure to the median human prediction as information, improving accuracy by between 17% and 28%, though this leads to less accurate predictions than simply averaging human and machine forecasts. Our results suggest that LLMs can achieve forecasting accuracy rivaling that of the human crowd: via the simple, practically applicable method of forecast aggregation.
Read more6/18/2024
🤿
0
Bayesian Statistical Modeling with Predictors from LLMs
Michael Franke, Polina Tsvilodub, Fausto Carcassi
State of the art large language models (LLMs) have shown impressive performance on a variety of benchmark tasks and are increasingly used as components in larger applications, where LLM-based predictions serve as proxies for human judgements or decision. This raises questions about the human-likeness of LLM-derived information, alignment with human intuition, and whether LLMs could possibly be considered (parts of) explanatory models of (aspects of) human cognition or language use. To shed more light on these issues, we here investigate the human-likeness of LLMs' predictions for multiple-choice decision tasks from the perspective of Bayesian statistical modeling. Using human data from a forced-choice experiment on pragmatic language use, we find that LLMs do not capture the variance in the human data at the item-level. We suggest different ways of deriving full distributional predictions from LLMs for aggregate, condition-level data, and find that some, but not all ways of obtaining condition-level predictions yield adequate fits to human data. These results suggests that assessment of LLM performance depends strongly on seemingly subtle choices in methodology, and that LLMs are at best predictors of human behavior at the aggregate, condition-level, for which they are, however, not designed to, or usually used to, make predictions in the first place.
Read more6/14/2024

0
Cognitive Bias in High-Stakes Decision-Making with LLMs
Jessica Echterhoff, Yao Liu, Abeer Alessa, Julian McAuley, Zexue He
Large language models (LLMs) offer significant potential as tools to support an expanding range of decision-making tasks. Given their training on human (created) data, LLMs have been shown to inherit societal biases against protected groups, as well as be subject to bias functionally resembling cognitive bias. Human-like bias can impede fair and explainable decisions made with LLM assistance. Our work introduces BiasBuster, a framework designed to uncover, evaluate, and mitigate cognitive bias in LLMs, particularly in high-stakes decision-making tasks. Inspired by prior research in psychology and cognitive science, we develop a dataset containing 16,800 prompts to evaluate different cognitive biases (e.g., prompt-induced, sequential, inherent). We test various bias mitigation strategies, amidst proposing a novel method utilising LLMs to debias their own prompts. Our analysis provides a comprehensive picture of the presence and effects of cognitive bias across commercial and open-source models. We demonstrate that our self-help debiasing effectively mitigates model answers that display patterns akin to human cognitive bias without having to manually craft examples for each bias.
Read more7/22/2024