AI-driven Java Performance Testing: Balancing Result Quality with Testing Time

0

Sign in to get full access
Overview
- This paper explores the use of AI-driven techniques to balance the quality of performance testing results with the time required to conduct the tests.
- The researchers investigate the application of machine learning models and time series classification to optimize the Java Microbenchmarking Harness (JMH) tool.
- The goal is to reduce the number of iterations needed in performance testing while maintaining reliable and accurate results.
Plain English Explanation
The paper discusses a way to make Java performance testing more efficient. Java performance testing is important for ensuring software runs quickly and smoothly, but it can be time-consuming. The researchers looked at using AI and machine learning techniques to improve the Java Microbenchmarking Harness (JMH), a popular tool for Java performance testing.
The goal was to find a way to reduce the number of times the performance tests need to be run while still getting reliable and accurate results. This would save time and make the testing process more efficient. The researchers explored using machine learning models and time series classification techniques to achieve this balance between testing time and result quality.
Technical Explanation
The researchers investigated using AI-driven techniques to optimize the Java Microbenchmarking Harness (JMH) tool for performance testing. Specifically, they explored the use of machine learning models and time series classification to reduce the number of iterations required in JMH testing while maintaining reliable and accurate results.
The key elements of their approach include:
-
Leveraging machine learning models to predict the convergence of performance test results based on the data collected so far. This allows the testing process to be stopped once reliable results are obtained, rather than running a fixed number of iterations.
-
Applying time series classification techniques to identify patterns in the performance data that indicate when the results have stabilized. This provides an alternative way to determine when to terminate the testing process.
-
Evaluating the tradeoffs between the quality of the testing results and the time required to conduct the tests. The researchers analyzed the accuracy and consistency of the optimized testing approach compared to the traditional JMH methodology.
The insights gained from this research have the potential to significantly improve the efficiency of Java performance testing by reducing the time and resources required without compromising the reliability of the results.
Critical Analysis
The paper presents a promising approach to optimizing Java performance testing, but it also acknowledges several caveats and limitations that warrant further investigation.
One key limitation is that the effectiveness of the proposed techniques may depend on the specific characteristics of the software being tested and the performance metrics of interest. The researchers note that additional research is needed to understand how the models and classification methods perform across a broader range of Java applications and testing scenarios.
Another potential issue is the computational overhead associated with training the machine learning models and running the time series classification algorithms. While the goal is to reduce overall testing time, the added processing requirements could offset some of the efficiency gains, particularly for smaller projects or limited computing resources.
The paper also suggests that further work is needed to better understand the sources of variability in performance test results and how the AI-driven optimization techniques handle different types of noise or outliers in the data. Improving the robustness of the approach to handle these challenges would be an important area for future research.
Conclusion
This paper presents an innovative approach to improving the efficiency of Java performance testing by leveraging AI-driven techniques. The researchers demonstrate how machine learning models and time series classification can be used to reduce the number of iterations required in the Java Microbenchmarking Harness (JMH) tool while maintaining reliable and accurate results.
The insights gained from this work have the potential to significantly streamline the performance testing process for Java-based applications, saving time and resources without compromising the quality of the testing. As the field of AI-assisted software engineering continues to evolve, this research represents an important step towards more intelligent and efficient performance evaluation methodologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AI-driven Java Performance Testing: Balancing Result Quality with Testing Time
Luca Traini, Federico Di Menna, Vittorio Cortellessa
Performance testing aims at uncovering efficiency issues of software systems. In order to be both effective and practical, the design of a performance test must achieve a reasonable trade-off between result quality and testing time. This becomes particularly challenging in Java context, where the software undergoes a warm-up phase of execution, due to just-in-time compilation. During this phase, performance measurements are subject to severe fluctuations, which may adversely affect quality of performance test results. However, these approaches often provide suboptimal estimates of the warm-up phase, resulting in either insufficient or excessive warm-up iterations, which may degrade result quality or increase testing time. There is still a lack of consensus on how to properly address this problem. Here, we propose and study an AI-based framework to dynamically halt warm-up iterations at runtime. Specifically, our framework leverages recent advances in AI for Time Series Classification (TSC) to predict the end of the warm-up phase during test execution. We conduct experiments by training three different TSC models on half a million of measurement segments obtained from JMH microbenchmark executions. We find that our framework significantly improves the accuracy of the warm-up estimates provided by state-of-practice and state-of-the-art methods. This higher estimation accuracy results in a net improvement in either result quality or testing time for up to +35.3% of the microbenchmarks. Our study highlights that integrating AI to dynamically estimate the end of the warm-up phase can enhance the cost-effectiveness of Java performance testing.
Read more8/12/2024
🛸
0
The Future of Software Testing: AI-Powered Test Case Generation and Validation
Mohammad Baqar, Rajat Khanda
Software testing is a crucial phase in the software development lifecycle (SDLC), ensuring that products meet necessary functional, performance, and quality benchmarks before release. Despite advancements in automation, traditional methods of generating and validating test cases still face significant challenges, including prolonged timelines, human error, incomplete test coverage, and high costs of manual intervention. These limitations often lead to delayed product launches and undetected defects that compromise software quality and user satisfaction. The integration of artificial intelligence (AI) into software testing presents a promising solution to these persistent challenges. AI-driven testing methods automate the creation of comprehensive test cases, dynamically adapt to changes, and leverage machine learning to identify high-risk areas in the codebase. This approach enhances regression testing efficiency while expanding overall test coverage. Furthermore, AI-powered tools enable continuous testing and self-healing test cases, significantly reducing manual oversight and accelerating feedback loops, ultimately leading to faster and more reliable software releases. This paper explores the transformative potential of AI in improving test case generation and validation, focusing on its ability to enhance efficiency, accuracy, and scalability in testing processes. It also addresses key challenges associated with adapting AI for testing, including the need for high quality training data, ensuring model transparency, and maintaining a balance between automation and human oversight. Through case studies and examples of real-world applications, this paper illustrates how AI can significantly enhance testing efficiency across both legacy and modern software systems.
Read more9/10/2024
0
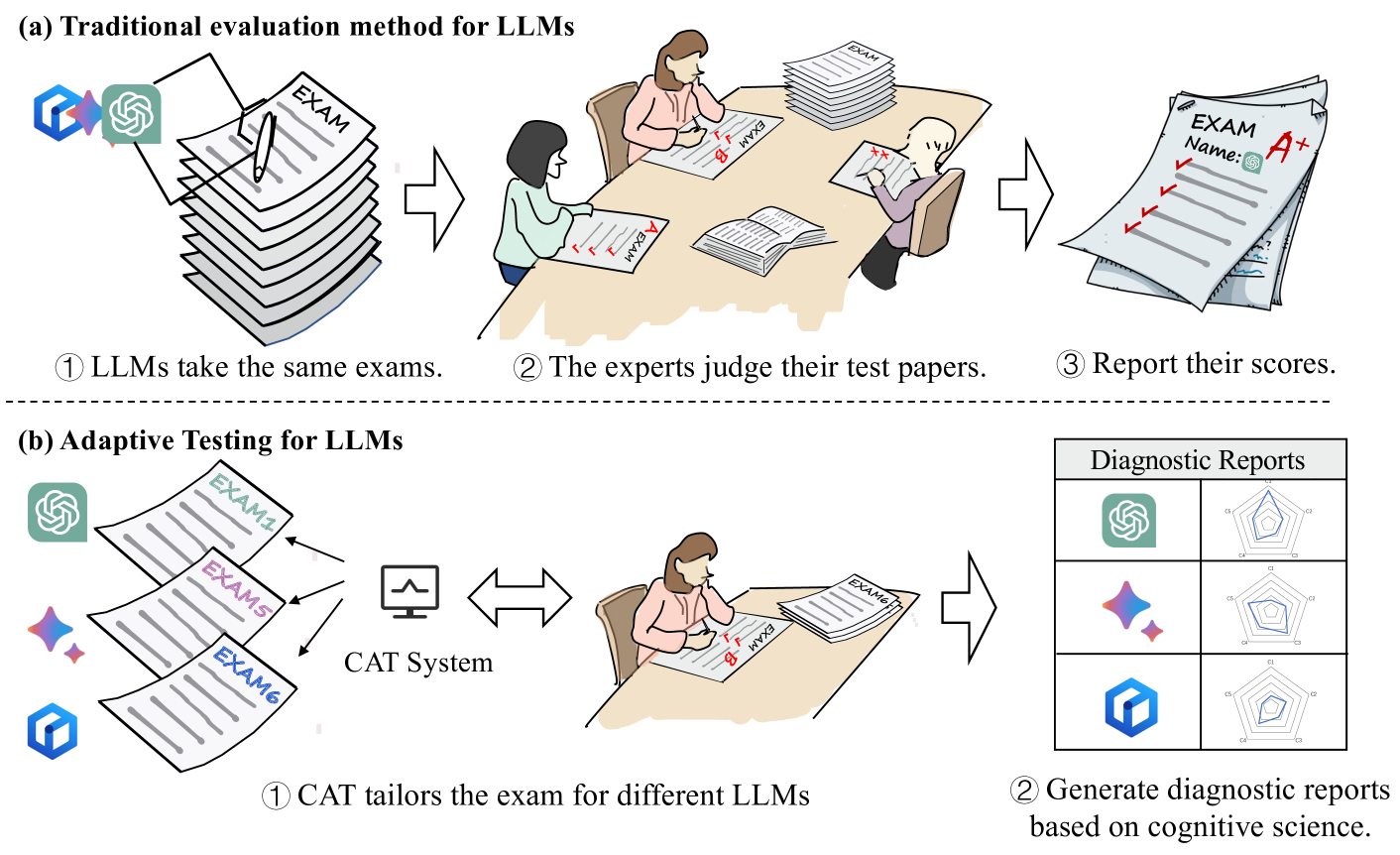
From Static Benchmarks to Adaptive Testing: Psychometrics in AI Evaluation
Yan Zhuang, Qi Liu, Yuting Ning, Weizhe Huang, Zachary A. Pardos, Patrick C. Kyllonen, Jiyun Zu, Qingyang Mao, Rui Lv, Zhenya Huang, Guanhao Zhao, Zheng Zhang, Shijin Wang, Enhong Chen
As AI systems continue to grow, particularly generative models like Large Language Models (LLMs), their rigorous evaluation is crucial for development and deployment. To determine their adequacy, researchers have developed various large-scale benchmarks against a so-called gold-standard test set and report metrics averaged across all items. However, this static evaluation paradigm increasingly shows its limitations, including high computational costs, data contamination, and the impact of low-quality or erroneous items on evaluation reliability and efficiency. In this Perspective, drawing from human psychometrics, we discuss a paradigm shift from static evaluation methods to adaptive testing. This involves estimating the characteristics and value of each test item in the benchmark and dynamically adjusting items in real-time, tailoring the evaluation based on the model's ongoing performance instead of relying on a fixed test set. This paradigm not only provides a more robust ability estimation but also significantly reduces the number of test items required. We analyze the current approaches, advantages, and underlying reasons for adopting psychometrics in AI evaluation. We propose that adaptive testing will become the new norm in AI model evaluation, enhancing both the efficiency and effectiveness of assessing advanced intelligence systems.
Read more8/7/2024

0
Can AI Beat Undergraduates in Entry-level Java Assignments? Benchmarking Large Language Models on JavaBench
Jialun Cao, Zhiyong Chen, Jiarong Wu, Shing-chi Cheung, Chang Xu
Code generation benchmarks such as HumanEval are widely adopted to evaluate LLMs' capabilities. However, after consolidating the latest 24 benchmarks, we noticed three significant imbalances. First, imbalanced programming language. 95.8% of benchmarks involve Python, while only 5 benchmarks involve Java. Second, imbalanced code granularity. Function-/statement-level benchmarks account for over 83.3% of benchmarks. Only a mere handful extends to class-/project-levels, and all are limited to Python. Third, lacking advanced features. Existing benchmarks primarily assess basic coding skills, while overlooking advanced Object-Oriented Programming (OOP) features (i.e., encapsulation, inheritance, and polymorphism). To fill these gaps, we propose JavaBench, a project-level Java benchmark that exercises OOP features. It comprises four Java projects with 389 methods in 106 Java classes. The test coverage is up to 92%, and JavaBench is attested by 282 undergraduate students, reaching a 90.93/100 average score (i.e., pass rate against the test suite), ensuring the quality of documentation, code skeleton, and tests. To better evaluate LLM's capability against JavaBench, we introduce a systematic evaluation design covering three context settings and five synthesis strategies at two granularities using three hierarchical metrics. Our extensive experiment yields several interesting findings. First, we noticed that regarding project-level Java programming, LLMs are far behind undergraduate students (no project can be correctly completed by any studied LLMs, and at most 41.17% Pass@5 in a more relaxed evaluation). Second, using method signature as prompt context may strike an ideal balance for project-level code generation. JavaBench is publicly available at https://github.com/java-bench/JavaBench.
Read more6/21/2024