Can AI Beat Undergraduates in Entry-level Java Assignments? Benchmarking Large Language Models on JavaBench

0

Sign in to get full access
Overview
- This paper benchmarks large language models on a new Java programming evaluation called JavaBench, which tests their ability to complete entry-level Java assignments.
- The researchers compare the performance of large language models like GPT-3 and Codex to that of undergraduate students on the JavaBench tasks.
- The goal is to assess whether these models can outperform human students on basic programming challenges, which could have implications for education and automation.
Plain English Explanation
The paper investigates whether artificial intelligence (AI) models, specifically large language models like GPT-3 and Codex, can outperform human undergraduate students on entry-level Java programming assignments. The researchers created a new benchmark called JavaBench that tests the ability of these AI models to complete basic Java coding tasks.
By comparing the performance of the AI models to that of human students, the researchers aim to understand if these language models have reached a level of programming proficiency that exceeds what we expect from novice programmers. This could have significant implications for the future of education and automated coding assistants.
The paper builds on previous work in benchmarking code generation models, such as the CS-Bench comprehensive benchmark, the PythonSaGA benchmark for evaluating code generation, and a critical review of benchmarks and metrics for code generation. It also builds on work that has examined the mismatch between human evaluation and natural coding performance and the development of holistic, contamination-free benchmarks like LiveCodeBench.
Technical Explanation
The researchers constructed the JavaBench benchmark, which consists of a set of entry-level Java programming assignments covering topics like object-oriented programming, control flow, and data structures. These tasks were designed to be similar in difficulty to what a first-year undergraduate computer science student might encounter.
To evaluate the performance of large language models on JavaBench, the researchers tested several models, including GPT-3 and Codex. The models were given the assignment prompts and asked to generate the corresponding Java code. Their outputs were then assessed for correctness, efficiency, and adherence to coding best practices.
The results showed that while the language models performed reasonably well on some of the simpler tasks, they struggled to match the performance of human undergraduate students, especially on more complex assignments involving object-oriented design and data structures. The models exhibited challenges with understanding the underlying programming concepts and effectively applying them to solve the problems.
Critical Analysis
The paper provides a valuable contribution to the ongoing research on the capabilities of large language models in the domain of programming. By creating a targeted benchmark like JavaBench, the researchers were able to gain insights into the specific strengths and limitations of these models when it comes to entry-level Java programming tasks.
However, it is important to note that the benchmark was focused on a relatively narrow set of programming skills, and the models' performance may vary on a broader range of programming challenges. Additionally, the benchmarking process itself could be further improved by incorporating more realistic programming scenarios and real-world coding practices.
As the authors acknowledge, the evaluation could be enhanced by incorporating more holistic and contamination-free approaches like those developed in the LiveCodeBench framework. This could help to better capture the nuances of human-like programming abilities.
Furthermore, it would be valuable to explore the potential of other types of AI models, such as those focused on program synthesis or neural-symbolic integration, to see if they can outperform the language models tested in this study.
Conclusion
This paper presents a novel benchmark, JavaBench, for evaluating the programming capabilities of large language models. The results suggest that while these models can handle some basic Java programming tasks, they still fall short of matching the performance of human undergraduate students, particularly on more complex assignments involving object-oriented design and data structures.
The findings highlight the continued challenges in developing AI systems that can truly emulate and exceed human-level programming abilities. As the field of AI-assisted coding continues to evolve, this research provides valuable insights and a foundation for further exploration into the strengths and limitations of current language models in the context of programming education and automation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can AI Beat Undergraduates in Entry-level Java Assignments? Benchmarking Large Language Models on JavaBench
Jialun Cao, Zhiyong Chen, Jiarong Wu, Shing-chi Cheung, Chang Xu
Code generation benchmarks such as HumanEval are widely adopted to evaluate LLMs' capabilities. However, after consolidating the latest 24 benchmarks, we noticed three significant imbalances. First, imbalanced programming language. 95.8% of benchmarks involve Python, while only 5 benchmarks involve Java. Second, imbalanced code granularity. Function-/statement-level benchmarks account for over 83.3% of benchmarks. Only a mere handful extends to class-/project-levels, and all are limited to Python. Third, lacking advanced features. Existing benchmarks primarily assess basic coding skills, while overlooking advanced Object-Oriented Programming (OOP) features (i.e., encapsulation, inheritance, and polymorphism). To fill these gaps, we propose JavaBench, a project-level Java benchmark that exercises OOP features. It comprises four Java projects with 389 methods in 106 Java classes. The test coverage is up to 92%, and JavaBench is attested by 282 undergraduate students, reaching a 90.93/100 average score (i.e., pass rate against the test suite), ensuring the quality of documentation, code skeleton, and tests. To better evaluate LLM's capability against JavaBench, we introduce a systematic evaluation design covering three context settings and five synthesis strategies at two granularities using three hierarchical metrics. Our extensive experiment yields several interesting findings. First, we noticed that regarding project-level Java programming, LLMs are far behind undergraduate students (no project can be correctly completed by any studied LLMs, and at most 41.17% Pass@5 in a more relaxed evaluation). Second, using method signature as prompt context may strike an ideal balance for project-level code generation. JavaBench is publicly available at https://github.com/java-bench/JavaBench.
Read more6/21/2024
0
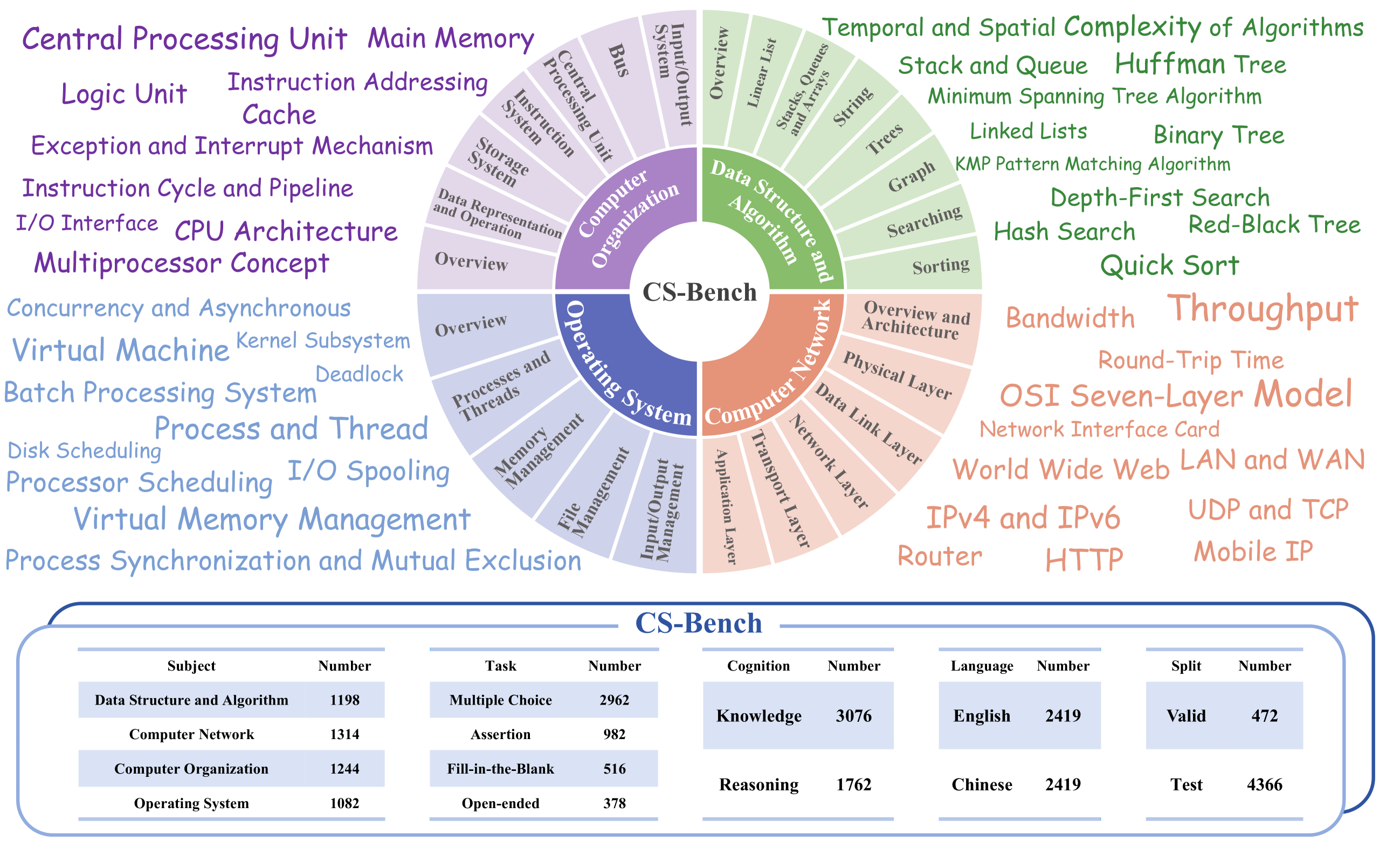
CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery
Xiaoshuai Song, Muxi Diao, Guanting Dong, Zhengyang Wang, Yujia Fu, Runqi Qiao, Zhexu Wang, Dayuan Fu, Huangxuan Wu, Bin Liang, Weihao Zeng, Yejie Wang, Zhuoma GongQue, Jianing Yu, Qiuna Tan, Weiran Xu
Computer Science (CS) stands as a testament to the intricacies of human intelligence, profoundly advancing the development of artificial intelligence and modern society. However, the current community of large language models (LLMs) overly focuses on benchmarks for analyzing specific foundational skills (e.g. mathematics and code generation), neglecting an all-round evaluation of the computer science field. To bridge this gap, we introduce CS-Bench, the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science. CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning. Utilizing CS-Bench, we conduct a comprehensive evaluation of over 30 mainstream LLMs, revealing the relationship between CS performance and model scales. We also quantitatively analyze the reasons for failures in existing LLMs and highlight directions for improvements, including knowledge supplementation and CS-specific reasoning. Further cross-capability experiments show a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Moreover, expert LLMs specialized in mathematics and coding also demonstrate strong performances in several CS subfields. Looking ahead, we envision CS-Bench serving as a cornerstone for LLM applications in the CS field and paving new avenues in assessing LLMs' diverse reasoning capabilities. The CS-Bench data and evaluation code are available at https://github.com/csbench/csbench.
Read more6/14/2024
🏅
0
PythonSaga: Redefining the Benchmark to Evaluate Code Generating LLM
Ankit Yadav, Himanshu Beniwal, Mayank Singh
Driven by the surge in code generation using large language models (LLMs), numerous benchmarks have emerged to evaluate these LLMs capabilities. We conducted a large-scale human evaluation of HumanEval and MBPP, two popular benchmarks for Python code generation, analyzing their diversity and difficulty. Our findings unveil a critical bias towards a limited set of programming concepts, neglecting most of the other concepts entirely. Furthermore, we uncover a worrying prevalence of easy tasks, potentially inflating model performance estimations. To address these limitations, we propose a novel benchmark, PythonSaga, featuring 185 hand-crafted prompts on a balanced representation of 38 programming concepts across diverse difficulty levels. The robustness of our benchmark is demonstrated by the poor performance of existing Code-LLMs.
Read more7/8/2024
💬
1
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models
Xiaoxuan Wang, Ziniu Hu, Pan Lu, Yanqiao Zhu, Jieyu Zhang, Satyen Subramaniam, Arjun R. Loomba, Shichang Zhang, Yizhou Sun, Wei Wang
Most of the existing Large Language Model (LLM) benchmarks on scientific problem reasoning focus on problems grounded in high-school subjects and are confined to elementary algebraic operations. To systematically examine the reasoning capabilities required for solving complex scientific problems, we introduce an expansive benchmark suite SciBench for LLMs. SciBench contains a carefully curated dataset featuring a range of collegiate-level scientific problems from mathematics, chemistry, and physics domains. Based on the dataset, we conduct an in-depth benchmarking study of representative open-source and proprietary LLMs with various prompting strategies. The results reveal that the current LLMs fall short of delivering satisfactory performance, with the best overall score of merely 43.22%. Furthermore, through a detailed user study, we categorize the errors made by LLMs into ten problem-solving abilities. Our analysis indicates that no single prompting strategy significantly outperforms the others and some strategies that demonstrate improvements in certain problem-solving skills could result in declines in other skills. We envision that SciBench will catalyze further developments in the reasoning abilities of LLMs, thereby ultimately contributing to scientific research and discovery.
Read more7/1/2024