Deepfake Text Detection in the Wild
2305.13242
0
0
🔎
Abstract
Large language models (LLMs) have achieved human-level text generation, emphasizing the need for effective AI-generated text detection to mitigate risks like the spread of fake news and plagiarism. Existing research has been constrained by evaluating detection methods on specific domains or particular language models. In practical scenarios, however, the detector faces texts from various domains or LLMs without knowing their sources. To this end, we build a comprehensive testbed by gathering texts from diverse human writings and texts generated by different LLMs. Empirical results show challenges in distinguishing machine-generated texts from human-authored ones across various scenarios, especially out-of-distribution. These challenges are due to the decreasing linguistic distinctions between the two sources. Despite challenges, the top-performing detector can identify 86.54% out-of-domain texts generated by a new LLM, indicating the feasibility for application scenarios. We release our resources at https://github.com/yafuly/MAGE.
Create account to get full access
Overview
- Large language models (LLMs) have achieved human-level text generation, highlighting the need for effective AI-generated text detection to mitigate risks like the spread of fake news and plagiarism.
- Existing research has been constrained by evaluating detection methods on specific domains or particular language models.
- This paper builds a comprehensive testbed to evaluate text detection methods across diverse human writings and texts generated by different LLMs.
Plain English Explanation
Large language models are artificial intelligence (AI) systems that can generate human-like text. While this is an impressive technological achievement, it also poses risks, such as the spread of fake news and plagiarism.
Previous research on detecting AI-generated text has been limited in scope, focusing on specific types of text or particular language models. In the real world, however, a text detection system might encounter content from a wide range of sources, including both human-written and AI-generated text.
To address this challenge, the researchers in this paper created a comprehensive test dataset, gathering text from diverse human writings as well as texts generated by different language models. By evaluating text detection methods across this diverse set of sources, the researchers were able to better understand the challenges in distinguishing machine-generated text from human-authored content, especially when the text comes from sources that were not part of the original training data.
Technical Explanation
The researchers built a comprehensive testbed by gathering texts from diverse human writings and texts generated by different large language models. This allowed them to evaluate the performance of text detection methods across a wide range of scenarios, including when the detector faces texts from sources it was not trained on.
The empirical results revealed significant challenges in distinguishing machine-generated texts from human-authored ones, especially in out-of-distribution scenarios. This is due to the decreasing linguistic distinctions between the two sources as language models become more advanced.
Despite these challenges, the researchers found that the top-performing text detection method could still identify 86.54% of out-of-domain texts generated by a new language model. This indicates the feasibility of using text detection methods in practical application scenarios, though further research is needed to address the challenges identified in the study.
Critical Analysis
The researchers acknowledge the limitations of their study, noting that the testbed they created, while comprehensive, may not capture all possible real-world scenarios. Additionally, the performance of text detection methods may continue to evolve as language models become more advanced.
One potential area for further research is exploring generalized detection strategies that can adapt to a wider range of text sources, rather than relying on detection methods trained on specific datasets or language models.
It is also important to consider the societal implications of AI-generated text detection, particularly regarding privacy, transparency, and the potential for abuse. Adapting fake news detection methods to the era of large language models may require additional ethical considerations and safeguards.
Conclusion
This research highlights the growing challenge of distinguishing machine-generated text from human-authored content, particularly as language models become more advanced. The researchers' comprehensive testbed and evaluation of text detection methods provide valuable insights into the current state of the field and the need for continued innovation to address this challenge.
As large language models become more prevalent, the ability to reliably detect AI-generated text will be crucial in mitigating the risks of fake news, plagiarism, and other potential misuses of this technology. The findings of this study contribute to the ongoing efforts to develop effective AI-generated text detection methods that can adapt to the ever-evolving landscape of language generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
A Survey on LLM-Generated Text Detection: Necessity, Methods, and Future Directions
Junchao Wu, Shu Yang, Runzhe Zhan, Yulin Yuan, Derek F. Wong, Lidia S. Chao
0
0
The powerful ability to understand, follow, and generate complex language emerging from large language models (LLMs) makes LLM-generated text flood many areas of our daily lives at an incredible speed and is widely accepted by humans. As LLMs continue to expand, there is an imperative need to develop detectors that can detect LLM-generated text. This is crucial to mitigate potential misuse of LLMs and safeguard realms like artistic expression and social networks from harmful influence of LLM-generated content. The LLM-generated text detection aims to discern if a piece of text was produced by an LLM, which is essentially a binary classification task. The detector techniques have witnessed notable advancements recently, propelled by innovations in watermarking techniques, statistics-based detectors, neural-base detectors, and human-assisted methods. In this survey, we collate recent research breakthroughs in this area and underscore the pressing need to bolster detector research. We also delve into prevalent datasets, elucidating their limitations and developmental requirements. Furthermore, we analyze various LLM-generated text detection paradigms, shedding light on challenges like out-of-distribution problems, potential attacks, real-world data issues and the lack of effective evaluation framework. Conclusively, we highlight interesting directions for future research in LLM-generated text detection to advance the implementation of responsible artificial intelligence (AI). Our aim with this survey is to provide a clear and comprehensive introduction for newcomers while also offering seasoned researchers a valuable update in the field of LLM-generated text detection. The useful resources are publicly available at: https://github.com/NLP2CT/LLM-generated-Text-Detection.
4/22/2024
🔎
Adapting Fake News Detection to the Era of Large Language Models
Jinyan Su, Claire Cardie, Preslav Nakov
0
0
In the age of large language models (LLMs) and the widespread adoption of AI-driven content creation, the landscape of information dissemination has witnessed a paradigm shift. With the proliferation of both human-written and machine-generated real and fake news, robustly and effectively discerning the veracity of news articles has become an intricate challenge. While substantial research has been dedicated to fake news detection, this either assumes that all news articles are human-written or abruptly assumes that all machine-generated news are fake. Thus, a significant gap exists in understanding the interplay between machine-(paraphrased) real news, machine-generated fake news, human-written fake news, and human-written real news. In this paper, we study this gap by conducting a comprehensive evaluation of fake news detectors trained in various scenarios. Our primary objectives revolve around the following pivotal question: How to adapt fake news detectors to the era of LLMs? Our experiments reveal an interesting pattern that detectors trained exclusively on human-written articles can indeed perform well at detecting machine-generated fake news, but not vice versa. Moreover, due to the bias of detectors against machine-generated texts cite{su2023fake}, they should be trained on datasets with a lower machine-generated news ratio than the test set. Building on our findings, we provide a practical strategy for the development of robust fake news detectors.
4/16/2024

Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics for Detecting Human vs. Machine-Generated Text
Mazal Bethany, Brandon Wherry, Emet Bethany, Nishant Vishwamitra, Anthony Rios, Peyman Najafirad
0
0
With the recent proliferation of Large Language Models (LLMs), there has been an increasing demand for tools to detect machine-generated text. The effective detection of machine-generated text face two pertinent problems: First, they are severely limited in generalizing against real-world scenarios, where machine-generated text is produced by a variety of generators, including but not limited to GPT-4 and Dolly, and spans diverse domains, ranging from academic manuscripts to social media posts. Second, existing detection methodologies treat texts produced by LLMs through a restrictive binary classification lens, neglecting the nuanced diversity of artifacts generated by different LLMs. In this work, we undertake a systematic study on the detection of machine-generated text in real-world scenarios. We first study the effectiveness of state-of-the-art approaches and find that they are severely limited against text produced by diverse generators and domains in the real world. Furthermore, t-SNE visualizations of the embeddings from a pretrained LLM's encoder show that they cannot reliably distinguish between human and machine-generated text. Based on our findings, we introduce a novel system, T5LLMCipher, for detecting machine-generated text using a pretrained T5 encoder combined with LLM embedding sub-clustering to address the text produced by diverse generators and domains in the real world. We evaluate our approach across 9 machine-generated text systems and 9 domains and find that our approach provides state-of-the-art generalization ability, with an average increase in F1 score on machine-generated text of 19.6% on unseen generators and domains compared to the top performing existing approaches and correctly attributes the generator of text with an accuracy of 93.6%.
4/4/2024
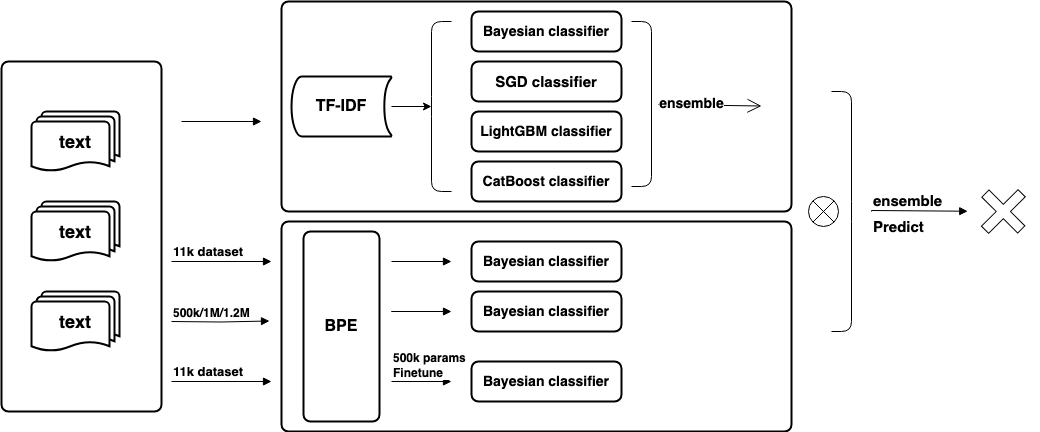
Enhancing Text Authenticity: A Novel Hybrid Approach for AI-Generated Text Detection
Ye Zhang, Qian Leng, Mengran Zhu, Rui Ding, Yue Wu, Jintong Song, Yulu Gong
0
0
The rapid advancement of Large Language Models (LLMs) has ushered in an era where AI-generated text is increasingly indistinguishable from human-generated content. Detecting AI-generated text has become imperative to combat misinformation, ensure content authenticity, and safeguard against malicious uses of AI. In this paper, we propose a novel hybrid approach that combines traditional TF-IDF techniques with advanced machine learning models, including Bayesian classifiers, Stochastic Gradient Descent (SGD), Categorical Gradient Boosting (CatBoost), and 12 instances of Deberta-v3-large models. Our approach aims to address the challenges associated with detecting AI-generated text by leveraging the strengths of both traditional feature extraction methods and state-of-the-art deep learning models. Through extensive experiments on a comprehensive dataset, we demonstrate the effectiveness of our proposed method in accurately distinguishing between human and AI-generated text. Our approach achieves superior performance compared to existing methods. This research contributes to the advancement of AI-generated text detection techniques and lays the foundation for developing robust solutions to mitigate the challenges posed by AI-generated content.
6/12/2024