AIGeN: An Adversarial Approach for Instruction Generation in VLN
2404.10054
0
0
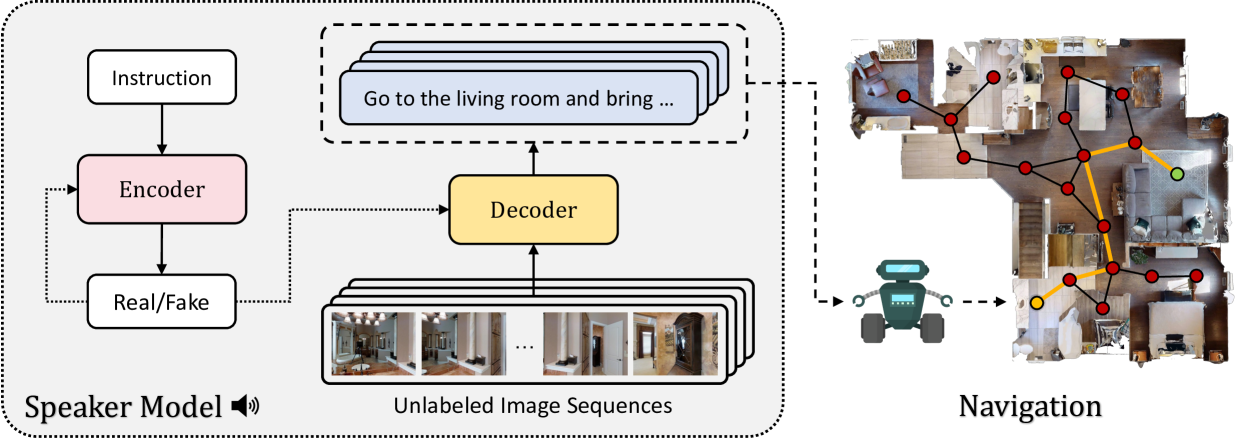
Abstract
In the last few years, the research interest in Vision-and-Language Navigation (VLN) has grown significantly. VLN is a challenging task that involves an agent following human instructions and navigating in a previously unknown environment to reach a specified goal. Recent work in literature focuses on different ways to augment the available datasets of instructions for improving navigation performance by exploiting synthetic training data. In this work, we propose AIGeN, a novel architecture inspired by Generative Adversarial Networks (GANs) that produces meaningful and well-formed synthetic instructions to improve navigation agents' performance. The model is composed of a Transformer decoder (GPT-2) and a Transformer encoder (BERT). During the training phase, the decoder generates sentences for a sequence of images describing the agent's path to a particular point while the encoder discriminates between real and fake instructions. Experimentally, we evaluate the quality of the generated instructions and perform extensive ablation studies. Additionally, we generate synthetic instructions for 217K trajectories using AIGeN on Habitat-Matterport 3D Dataset (HM3D) and show an improvement in the performance of an off-the-shelf VLN method. The validation analysis of our proposal is conducted on REVERIE and R2R and highlights the promising aspects of our proposal, achieving state-of-the-art performance.
Create account to get full access
Overview
- This document provides guidelines for authors submitting papers to the CVPR (Conference on Computer Vision and Pattern Recognition) proceedings using LaTeX.
- It covers important formatting requirements, such as paper size, margins, fonts, and citation style, to ensure consistency across accepted papers.
- The guidelines also include instructions for submitting supplementary material and navigating the review process.
Plain English Explanation
This paper outlines the formatting rules and submission guidelines for authors who want to publish their research papers in the proceedings of the CVPR conference. CVPR is a major event in the field of computer vision, where researchers present their latest findings and advancements.
The guidelines cover essential details like the page size, page margins, font types, and citation format that authors must follow when preparing their papers. This ensures a consistent look and feel across all the published papers, making it easier for readers to navigate the proceedings.
The document also provides instructions on how to submit any additional materials, such as supplementary files or data, alongside the main paper. Additionally, it explains the review process that papers go through before they are accepted for publication.
By following these guidelines, authors can ensure that their papers are properly formatted and prepared for submission to the CVPR conference, increasing the chances of their research being accepted and presented to the broader computer vision community.
Technical Explanation
The provided document outlines the LaTeX author guidelines for the CVPR (Conference on Computer Vision and Pattern Recognition) proceedings. It covers the essential formatting requirements that authors must adhere to when preparing their papers for submission.
The guidelines specify the paper size, margins, font types, and citation style to be used. For example, the paper size should be US letter (8.5 x 11 inches) with 1-inch margins on all sides. The main text should be set in a 10-point font, and citations should follow the IEEE style.
The document also provides instructions on how to submit supplementary material, such as videos or datasets, alongside the main paper. This additional content can provide valuable context and support for the research presented in the paper.
Furthermore, the guidelines outline the review process that papers go through before being accepted for publication in the CVPR proceedings. This includes details on the submission deadlines, review timeline, and notification of acceptance.
By following these guidelines, authors can ensure that their papers are properly formatted and prepared for submission to the CVPR conference, increasing the chances of their research being accepted and presented to the broader computer vision community.
Critical Analysis
The CVPR author guidelines serve an important purpose in maintaining consistency and quality across the conference proceedings. By enforcing standardized formatting requirements, the guidelines help ensure that the published papers are easy to read, navigate, and compare.
However, one potential limitation of the guidelines is that they may not accommodate the evolving needs and preferences of the computer vision community. As research fields progress, there may be a need to revisit the formatting rules to better suit new modes of presentation or emerging best practices.
Additionally, the guidelines do not address potential issues related to the review process, such as potential biases or lack of transparency. While the guidelines provide a high-level overview of the review timeline, they do not delve into the specifics of how papers are evaluated or the criteria used for acceptance.
It would be valuable for the CVPR organizers to periodically review and update the guidelines based on feedback from the community. This could help ensure that the formatting requirements remain relevant and that the review process is as fair and inclusive as possible.
Conclusion
The CVPR author guidelines provide a clear and concise set of instructions for formatting and submitting research papers to the conference proceedings. By adhering to these guidelines, authors can ensure that their work is presented in a consistent and accessible manner, making it easier for readers to engage with the latest advancements in computer vision research.
While the guidelines serve an important purpose, it is crucial that they continue to evolve to meet the changing needs of the research community. Regular reviews and updates to the guidelines, as well as greater transparency around the review process, could help strengthen the CVPR conference and its contributions to the field of computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Vision-and-Language Navigation Generative Pretrained Transformer
Wen Hanlin
0
0
In the Vision-and-Language Navigation (VLN) field, agents are tasked with navigating real-world scenes guided by linguistic instructions. Enabling the agent to adhere to instructions throughout the process of navigation represents a significant challenge within the domain of VLN. To address this challenge, common approaches often rely on encoders to explicitly record past locations and actions, increasing model complexity and resource consumption. Our proposal, the Vision-and-Language Navigation Generative Pretrained Transformer (VLN-GPT), adopts a transformer decoder model (GPT2) to model trajectory sequence dependencies, bypassing the need for historical encoding modules. This method allows for direct historical information access through trajectory sequence, enhancing efficiency. Furthermore, our model separates the training process into offline pre-training with imitation learning and online fine-tuning with reinforcement learning. This distinction allows for more focused training objectives and improved performance. Performance assessments on the VLN dataset reveal that VLN-GPT surpasses complex state-of-the-art encoder-based models.
5/28/2024

MC-GPT: Empowering Vision-and-Language Navigation with Memory Map and Reasoning Chains
Zhaohuan Zhan, Lisha Yu, Sijie Yu, Guang Tan
0
0
In the Vision-and-Language Navigation (VLN) task, the agent is required to navigate to a destination following a natural language instruction. While learning-based approaches have been a major solution to the task, they suffer from high training costs and lack of interpretability. Recently, Large Language Models (LLMs) have emerged as a promising tool for VLN due to their strong generalization capabilities. However, existing LLM-based methods face limitations in memory construction and diversity of navigation strategies. To address these challenges, we propose a suite of techniques. Firstly, we introduce a method to maintain a topological map that stores navigation history, retaining information about viewpoints, objects, and their spatial relationships. This map also serves as a global action space. Additionally, we present a Navigation Chain of Thoughts module, leveraging human navigation examples to enrich navigation strategy diversity. Finally, we establish a pipeline that integrates navigational memory and strategies with perception and action prediction modules. Experimental results on the REVERIE and R2R datasets show that our method effectively enhances the navigation ability of the LLM and improves the interpretability of navigation reasoning.
5/20/2024
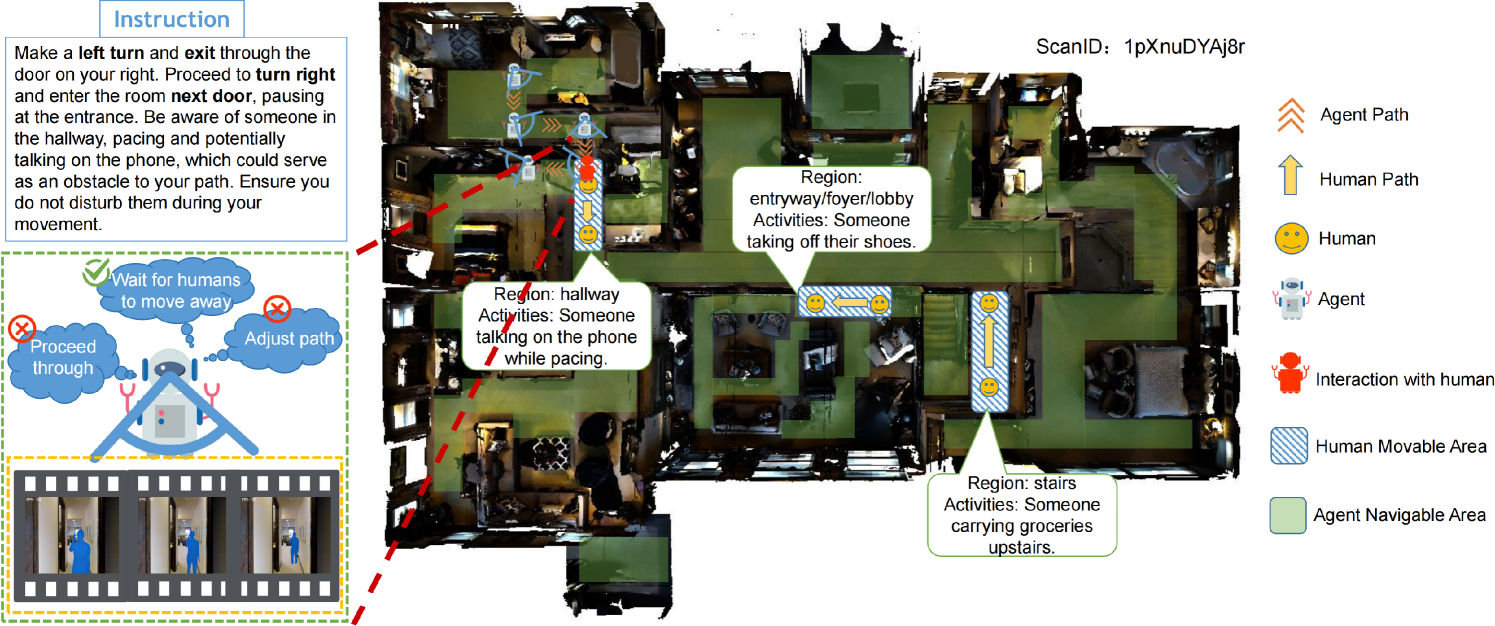
Human-Aware Vision-and-Language Navigation: Bridging Simulation to Reality with Dynamic Human Interactions
Minghan Li, Heng Li, Zhi-Qi Cheng, Yifei Dong, Yuxuan Zhou, Jun-Yan He, Qi Dai, Teruko Mitamura, Alexander G. Hauptmann
0
0
Vision-and-Language Navigation (VLN) aims to develop embodied agents that navigate based on human instructions. However, current VLN frameworks often rely on static environments and optimal expert supervision, limiting their real-world applicability. To address this, we introduce Human-Aware Vision-and-Language Navigation (HA-VLN), extending traditional VLN by incorporating dynamic human activities and relaxing key assumptions. We propose the Human-Aware 3D (HA3D) simulator, which combines dynamic human activities with the Matterport3D dataset, and the Human-Aware Room-to-Room (HA-R2R) dataset, extending R2R with human activity descriptions. To tackle HA-VLN challenges, we present the Expert-Supervised Cross-Modal (VLN-CM) and Non-Expert-Supervised Decision Transformer (VLN-DT) agents, utilizing cross-modal fusion and diverse training strategies for effective navigation in dynamic human environments. A comprehensive evaluation, including metrics considering human activities, and systematic analysis of HA-VLN's unique challenges, underscores the need for further research to enhance HA-VLN agents' real-world robustness and adaptability. Ultimately, this work provides benchmarks and insights for future research on embodied AI and Sim2Real transfer, paving the way for more realistic and applicable VLN systems in human-populated environments.
6/28/2024

NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, He Wang
0
0
Vision-and-language navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavor to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometers, or depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision making and instruction following. We train NaVid with 510k navigation samples collected from continuous environments, including action-planning and instruction-reasoning samples, along with 763k large-scale web data. Extensive experiments show that NaVid achieves state-of-the-art performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
5/28/2024