Vision-and-Language Navigation Generative Pretrained Transformer

0

Sign in to get full access
Overview
- The paper presents a Vision-and-Language Navigation Generative Pretrained Transformer (VLN-GPT), a model that combines vision and language understanding to navigate through environments based on natural language instructions.
- The VLN-GPT model is designed to address the task of Vision-and-Language Navigation (VLN), where an agent must navigate through a 3D environment to reach a goal location described in natural language.
- The model utilizes a pretrained Transformer architecture to jointly process visual and language inputs, allowing it to learn effective navigation strategies from data.
Plain English Explanation
The VLN-GPT model is designed to help an AI agent navigate through 3D environments based on natural language instructions. For example, the agent might be given the instruction "Walk to the kitchen and turn left at the table." The VLN-GPT model uses a powerful Transformer-based architecture to understand both the visual information from the environment and the language instructions, allowing it to plan and execute the correct sequence of actions to reach the desired location.
This is an important task because it could enable AI systems to better assist humans in real-world environments, such as guiding a robot through a building to complete a task. By using natural language instructions rather than requiring the user to provide detailed step-by-step commands, the VLN-GPT model makes the interaction more natural and accessible.
The model builds on previous research in Vision-and-Language Navigation and Neural Radiance Representation, leveraging the strengths of Transformer architectures to learn effective navigation strategies from data. This could lead to more capable and adaptable AI agents that can understand and operate in complex, dynamic environments.
Technical Explanation
The VLN-GPT model uses a Transformer-based architecture to jointly process visual and language inputs for the VLN task. The model takes in the current egocentric view of the environment, the language instruction, and the agent's previous actions and observations, and outputs the next action the agent should take.
The key components of the VLN-GPT model include:
- A vision encoder that processes the agent's current egocentric view of the environment
- A language encoder that processes the natural language instruction
- A Transformer-based module that integrates the visual and language information and reasons about the appropriate actions to take
- A memory module that allows the agent to remember and reason about its past actions and observations
During training, the model is exposed to a large dataset of VLN examples, where it learns to map language instructions and visual observations to effective navigation trajectories. The AIGEN and NavID models, which focus on generating natural language instructions and understanding video-based navigation, respectively, could provide useful insights for further improving the VLN-GPT approach.
Critical Analysis
The VLN-GPT model represents a significant advance in the field of Vision-and-Language Navigation, but it also has some limitations and areas for potential improvement:
- The model's performance is still limited by the quality and diversity of the training data, and it may struggle in environments or situations that are not well represented in the dataset.
- The memory module, while an important component, may not be sufficient to capture the full complexity of long-term navigation strategies and reasoning about past actions.
- The model's reliance on Transformer architectures means it may be computationally intensive and require significant resources to deploy in real-world applications.
Further research could explore causal learning approaches to better understand the underlying mechanisms driving successful navigation, as well as techniques to improve the model's generalization to novel environments and tasks.
Conclusion
The VLN-GPT model represents an important step forward in the field of Vision-and-Language Navigation, demonstrating the power of large-scale Transformer-based architectures to jointly process visual and language information for complex task completion. By enabling AI agents to understand and follow natural language instructions in 3D environments, this research could pave the way for more intuitive and accessible human-AI interaction in a variety of real-world applications, from robotic assistants to augmented reality navigation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Vision-and-Language Navigation Generative Pretrained Transformer
Wen Hanlin
In the Vision-and-Language Navigation (VLN) field, agents are tasked with navigating real-world scenes guided by linguistic instructions. Enabling the agent to adhere to instructions throughout the process of navigation represents a significant challenge within the domain of VLN. To address this challenge, common approaches often rely on encoders to explicitly record past locations and actions, increasing model complexity and resource consumption. Our proposal, the Vision-and-Language Navigation Generative Pretrained Transformer (VLN-GPT), adopts a transformer decoder model (GPT2) to model trajectory sequence dependencies, bypassing the need for historical encoding modules. This method allows for direct historical information access through trajectory sequence, enhancing efficiency. Furthermore, our model separates the training process into offline pre-training with imitation learning and online fine-tuning with reinforcement learning. This distinction allows for more focused training objectives and improved performance. Performance assessments on the VLN dataset reveal that VLN-GPT surpasses complex state-of-the-art encoder-based models.
Read more5/28/2024

0
NavGPT-2: Unleashing Navigational Reasoning Capability for Large Vision-Language Models
Gengze Zhou, Yicong Hong, Zun Wang, Xin Eric Wang, Qi Wu
Capitalizing on the remarkable advancements in Large Language Models (LLMs), there is a burgeoning initiative to harness LLMs for instruction following robotic navigation. Such a trend underscores the potential of LLMs to generalize navigational reasoning and diverse language understanding. However, a significant discrepancy in agent performance is observed when integrating LLMs in the Vision-and-Language navigation (VLN) tasks compared to previous downstream specialist models. Furthermore, the inherent capacity of language to interpret and facilitate communication in agent interactions is often underutilized in these integrations. In this work, we strive to bridge the divide between VLN-specialized models and LLM-based navigation paradigms, while maintaining the interpretative prowess of LLMs in generating linguistic navigational reasoning. By aligning visual content in a frozen LLM, we encompass visual observation comprehension for LLMs and exploit a way to incorporate LLMs and navigation policy networks for effective action predictions and navigational reasoning. We demonstrate the data efficiency of the proposed methods and eliminate the gap between LM-based agents and state-of-the-art VLN specialists.
Read more9/23/2024

0
MC-GPT: Empowering Vision-and-Language Navigation with Memory Map and Reasoning Chains
Zhaohuan Zhan, Lisha Yu, Sijie Yu, Guang Tan
In the Vision-and-Language Navigation (VLN) task, the agent is required to navigate to a destination following a natural language instruction. While learning-based approaches have been a major solution to the task, they suffer from high training costs and lack of interpretability. Recently, Large Language Models (LLMs) have emerged as a promising tool for VLN due to their strong generalization capabilities. However, existing LLM-based methods face limitations in memory construction and diversity of navigation strategies. To address these challenges, we propose a suite of techniques. Firstly, we introduce a method to maintain a topological map that stores navigation history, retaining information about viewpoints, objects, and their spatial relationships. This map also serves as a global action space. Additionally, we present a Navigation Chain of Thoughts module, leveraging human navigation examples to enrich navigation strategy diversity. Finally, we establish a pipeline that integrates navigational memory and strategies with perception and action prediction modules. Experimental results on the REVERIE and R2R datasets show that our method effectively enhances the navigation ability of the LLM and improves the interpretability of navigation reasoning.
Read more8/13/2024
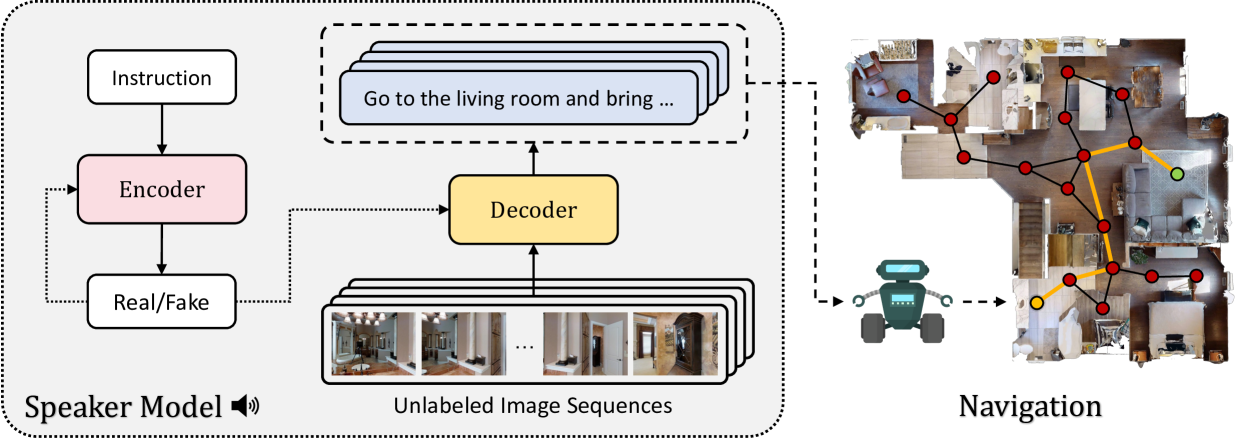
0
AIGeN: An Adversarial Approach for Instruction Generation in VLN
Niyati Rawal, Roberto Bigazzi, Lorenzo Baraldi, Rita Cucchiara
In the last few years, the research interest in Vision-and-Language Navigation (VLN) has grown significantly. VLN is a challenging task that involves an agent following human instructions and navigating in a previously unknown environment to reach a specified goal. Recent work in literature focuses on different ways to augment the available datasets of instructions for improving navigation performance by exploiting synthetic training data. In this work, we propose AIGeN, a novel architecture inspired by Generative Adversarial Networks (GANs) that produces meaningful and well-formed synthetic instructions to improve navigation agents' performance. The model is composed of a Transformer decoder (GPT-2) and a Transformer encoder (BERT). During the training phase, the decoder generates sentences for a sequence of images describing the agent's path to a particular point while the encoder discriminates between real and fake instructions. Experimentally, we evaluate the quality of the generated instructions and perform extensive ablation studies. Additionally, we generate synthetic instructions for 217K trajectories using AIGeN on Habitat-Matterport 3D Dataset (HM3D) and show an improvement in the performance of an off-the-shelf VLN method. The validation analysis of our proposal is conducted on REVERIE and R2R and highlights the promising aspects of our proposal, achieving state-of-the-art performance.
Read more4/17/2024