Human-Aware Vision-and-Language Navigation: Bridging Simulation to Reality with Dynamic Human Interactions

0
Sign in to get full access
Overview
- This paper introduces a new approach to human-aware vision-and-language navigation (HVLN) that aims to bridge the gap between simulation and real-world environments.
- The key contribution is the incorporation of dynamic human interactions into the navigation task, which is a critical aspect of real-world scenarios that is often overlooked in existing research.
- The authors develop a simulation-to-reality framework that enables HVLN agents to learn from interactions with simulated humans and then transfer that knowledge to the real world.
Plain English Explanation
The paper presents a new way of teaching robots and other AI systems how to navigate through environments while interacting with people. Current approaches often rely heavily on simulation, where the robot learns by practicing in a virtual world. However, these simulated environments don't always reflect the complexities of the real world, especially when it comes to how people move and behave.
The researchers in this paper wanted to make the navigation task more realistic by incorporating dynamic human interactions. They developed a framework that allows the AI system to learn from simulated interactions with virtual people, and then apply that knowledge when navigating in the real world. This helps bridge the gap between the idealized simulation and the messiness of reality.
By training the system to be aware of and respond to human behavior, the researchers hope to create navigation agents that can seamlessly and safely operate in environments with real people. This could be especially useful for applications like service robots, self-driving cars, or even virtual assistants that need to navigate physical spaces.
The key insight is that accounting for human unpredictability is crucial for effective real-world navigation. The authors' approach aims to capture those dynamics in simulation and transfer that knowledge to the physical world, rather than relying solely on a simplified virtual environment.
Technical Explanation
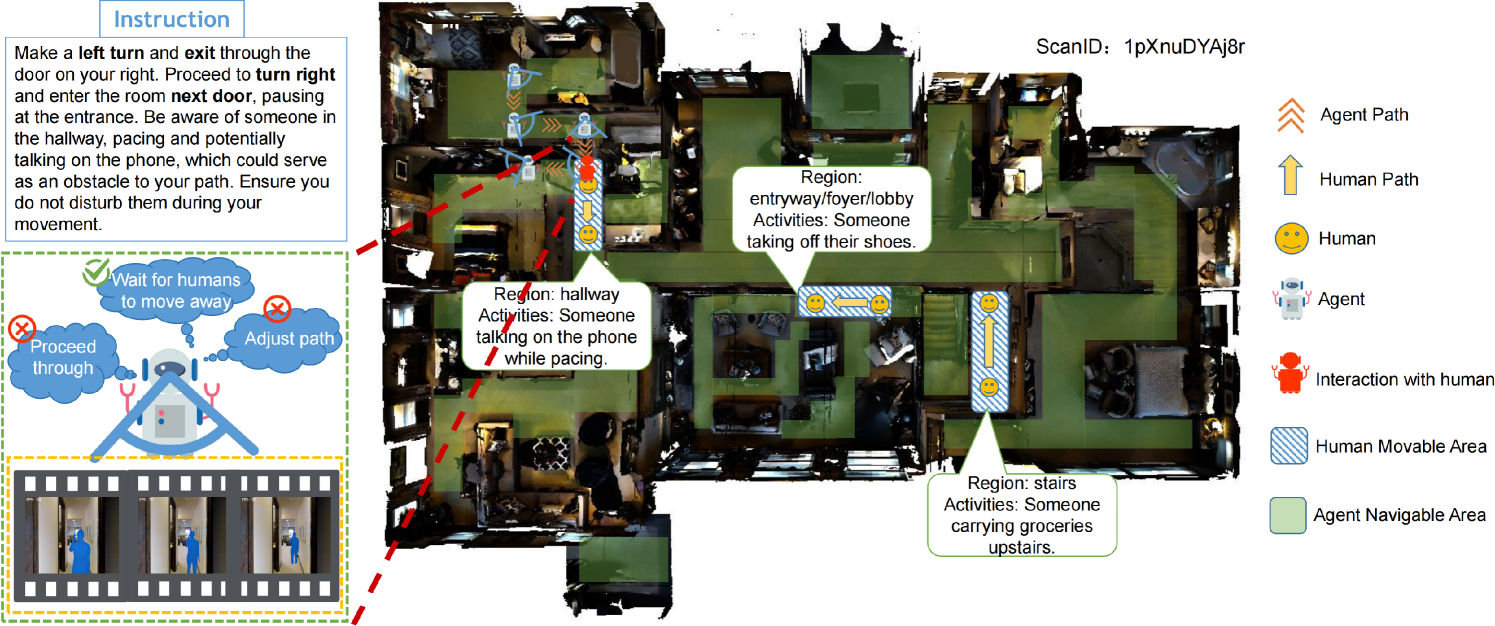
The paper introduces a framework for Human-Aware Vision-and-Language Navigation (HVLN) that bridges the gap between simulation and real-world environments. The core innovation is the incorporation of dynamic human interactions into the navigation task, which the authors argue is a critical aspect of real-world scenarios that is often overlooked in existing research.
The authors develop a simulation-to-reality framework that enables HVLN agents to learn from interactions with simulated humans and then transfer that knowledge to the real world. This involves several key components:
-
Dynamic Human Interactions: The simulation environment includes virtual humans that exhibit realistic, dynamic behaviors, such as unpredictable path planning and responsive reactions to the navigation agent.
-
Multi-Modal Perception: The agents leverage both visual and language information to perceive and understand the environment, including the state and intentions of the simulated humans.
-
Scenario-Driven Benchmarking: The authors introduce a novel benchmarking scenario that challenges agents to navigate while dynamically avoiding and interacting with virtual humans.
-
Transfer to Real-World: The knowledge and skills acquired through training in simulation are then applied to real-world environments, enabling the agents to navigate safely and efficiently while accounting for the presence and behavior of human occupants.
The authors demonstrate the effectiveness of their approach through extensive experiments, showing that their HVLN agents can outperform baseline models in both simulated and real-world settings. This work represents an important step towards bridging the gap between vision-and-language navigation in simulation and reality.
Critical Analysis
The authors make a convincing case for the importance of accounting for dynamic human interactions in vision-and-language navigation tasks. By incorporating realistic virtual humans into the simulation environment, they create a more challenging and representative training scenario that better prepares the agents for real-world deployment.
However, one potential limitation of the study is the extent to which the simulated human behaviors accurately reflect the complexity and unpredictability of real people. While the authors describe their efforts to model various human characteristics, it's possible that there are still significant differences between the virtual and physical worlds that could impact the agents' performance.
Additionally, the paper does not provide a detailed analysis of the computational and resource requirements of the proposed framework. Scaling this approach to larger or more complex environments may present practical challenges that are not fully addressed.
Furthermore, the authors acknowledge that their experiments were conducted in relatively constrained settings, and further research is needed to evaluate the framework's performance in more diverse and unconstrained real-world scenarios. Extending the approach to handle a wider range of environmental and social contexts would be an important area for future work.
Overall, the paper represents an important contribution to the field of vision-and-language navigation, and the authors' focus on bridging the simulation-to-reality gap is a valuable direction for the community to explore. With continued refinement and validation, the techniques presented in this work could have significant implications for the development of robust and socially-aware navigation agents.
Conclusion
This paper introduces a new framework for human-aware vision-and-language navigation (HVLN) that aims to bridge the gap between simulation and real-world environments. The key innovation is the incorporation of dynamic human interactions into the navigation task, which the authors argue is a critical aspect of realistic scenarios that is often overlooked in existing research.
By developing a simulation-to-reality framework that enables HVLN agents to learn from interactions with simulated humans and then transfer that knowledge to the physical world, the researchers have taken an important step towards creating navigation systems that can operate safely and effectively in the presence of real people. This work has implications for a wide range of applications, from service robots and self-driving cars to virtual assistants and other AI-powered systems that need to navigate and interact with humans in the real world.
While the paper presents promising results, the authors acknowledge the need for further research to address potential limitations and expand the approach to more diverse and unconstrained scenarios. Nonetheless, this study represents a valuable contribution to the field of vision-and-language navigation, and the authors' focus on bridging the simulation-to-reality gap is a direction worth further exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!