ALI-Agent: Assessing LLMs' Alignment with Human Values via Agent-based Evaluation
2405.14125
0
0
🌀
Abstract
Large Language Models (LLMs) can elicit unintended and even harmful content when misaligned with human values, posing severe risks to users and society. To mitigate these risks, current evaluation benchmarks predominantly employ expert-designed contextual scenarios to assess how well LLMs align with human values. However, the labor-intensive nature of these benchmarks limits their test scope, hindering their ability to generalize to the extensive variety of open-world use cases and identify rare but crucial long-tail risks. Additionally, these static tests fail to adapt to the rapid evolution of LLMs, making it hard to evaluate timely alignment issues. To address these challenges, we propose ALI-Agent, an evaluation framework that leverages the autonomous abilities of LLM-powered agents to conduct in-depth and adaptive alignment assessments. ALI-Agent operates through two principal stages: Emulation and Refinement. During the Emulation stage, ALI-Agent automates the generation of realistic test scenarios. In the Refinement stage, it iteratively refines the scenarios to probe long-tail risks. Specifically, ALI-Agent incorporates a memory module to guide test scenario generation, a tool-using module to reduce human labor in tasks such as evaluating feedback from target LLMs, and an action module to refine tests. Extensive experiments across three aspects of human values--stereotypes, morality, and legality--demonstrate that ALI-Agent, as a general evaluation framework, effectively identifies model misalignment. Systematic analysis also validates that the generated test scenarios represent meaningful use cases, as well as integrate enhanced measures to probe long-tail risks. Our code is available at https://github.com/SophieZheng998/ALI-Agent.git
Create account to get full access
Overview
- Large language models (LLMs) can produce unintended and harmful content when not aligned with human values
- Current evaluation benchmarks use expert-designed scenarios, but they are labor-intensive and fail to cover the full range of real-world use cases
- This paper proposes a new framework called ALI-Agent to address these limitations by automating the generation and refinement of test scenarios
Plain English Explanation
ALI-Agent: An Autonomous and Adaptive Framework for Probing Alignment Risks in Large Language Models
As large language models (LLMs) become more powerful and widespread, there is a growing concern about the potential for these models to produce unintended and even harmful content when they are not properly aligned with human values. To address this issue, researchers have developed evaluation benchmarks that use expert-designed scenarios to assess how well LLMs align with human values. However, these benchmarks are labor-intensive to create and fail to cover the full range of real-world use cases, limiting their ability to identify rare but crucial long-tail risks.
To overcome these limitations, the researchers propose a new framework called ALI-Agent that leverages the autonomous abilities of LLM-powered agents to conduct more comprehensive and adaptive alignment assessments. ALI-Agent operates in two stages: Emulation and Refinement. During the Emulation stage, ALI-Agent automates the generation of realistic test scenarios. In the Refinement stage, it iteratively refines the scenarios to probe long-tail risks.
ALI-Agent incorporates several key components to achieve this:
- A memory module to guide the generation of test scenarios
- A tool-using module to reduce human labor in tasks like evaluating feedback from target LLMs
- An action module to refine the test scenarios
Through extensive experiments across three aspects of human values (stereotypes, morality, and legality), the researchers demonstrate that ALI-Agent is an effective and general framework for identifying model misalignment. The generated test scenarios are also shown to represent meaningful use cases and integrate enhanced measures to probe long-tail risks.
Technical Explanation
The researchers propose ALI-Agent, an evaluation framework that uses autonomous LLM-powered agents to generate and refine test scenarios for assessing the alignment of large language models (LLMs) with human values. The framework operates in two main stages:
-
Emulation Stage: During this stage, ALI-Agent automates the generation of realistic test scenarios to probe the target LLM's alignment with human values. This is achieved through a memory module that stores and retrieves relevant knowledge to guide the scenario generation process.
-
Refinement Stage: In this stage, ALI-Agent iteratively refines the generated test scenarios to identify long-tail risks. This is accomplished using a tool-using module that can perform tasks like evaluating feedback from the target LLM, as well as an action module that can modify the scenarios based on the evaluation results.
The researchers evaluate ALI-Agent across three aspects of human values: stereotypes, morality, and legality. Their experiments demonstrate that ALI-Agent is an effective and general framework for identifying model misalignment. The generated test scenarios are shown to represent meaningful use cases, and the framework integrates enhanced measures to probe long-tail risks.
Critical Analysis
The researchers have proposed a promising approach to addressing the limitations of current evaluation benchmarks for assessing the alignment of large language models (LLMs) with human values. By leveraging the autonomous abilities of LLM-powered agents, ALI-Agent aims to automate the generation and refinement of test scenarios, covering a broader range of real-world use cases and identifying rare but crucial long-tail risks.
However, the paper does not fully address the challenges of ensuring the reliability and validity of the automatically generated test scenarios. While the researchers demonstrate that the scenarios represent meaningful use cases, there may be concerns about their ability to capture the full complexity and nuance of human values. Additionally, the reliance on LLM-powered agents raises questions about the potential for biases or errors to be introduced into the evaluation process.
Further research is needed to explore the long-term implications of using autonomous agents for evaluating the alignment of LLMs. For example, it would be important to investigate how the framework could adapt to the rapid evolution of LLMs and ensure that the evaluation process remains relevant and up-to-date. Additionally, the researchers could explore ways to incorporate human feedback and oversight into the evaluation process to enhance its reliability and trustworthiness.
Conclusion
The paper presents a novel framework, ALI-Agent, that leverages the autonomous abilities of LLM-powered agents to automate the generation and refinement of test scenarios for assessing the alignment of large language models (LLMs) with human values. This approach addresses the limitations of current expert-designed benchmarks, which are labor-intensive and fail to cover the full range of real-world use cases.
ALI-Agent's two-stage process of Emulation and Refinement, along with its incorporation of a memory module, tool-using module, and action module, demonstrates its potential as a general and effective framework for identifying model misalignment. The experiments conducted by the researchers provide promising results, suggesting that ALI-Agent can generate meaningful test scenarios and probe long-tail risks.
While the framework shows promise, further research is needed to address the potential challenges and limitations, such as ensuring the reliability and validity of the automatically generated test scenarios and exploring the long-term implications of using autonomous agents for evaluating LLM alignment. Overall, the paper presents an innovative approach to a critical challenge in the development and deployment of large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
How Ethical Should AI Be? How AI Alignment Shapes the Risk Preferences of LLMs
Shumiao Ouyang, Hayong Yun, Xingjian Zheng
0
0
This study explores the risk preferences of Large Language Models (LLMs) and how the process of aligning them with human ethical standards influences their economic decision-making. By analyzing 30 LLMs, we uncover a broad range of inherent risk profiles ranging from risk-averse to risk-seeking. We then explore how different types of AI alignment, a process that ensures models act according to human values and that focuses on harmlessness, helpfulness, and honesty, alter these base risk preferences. Alignment significantly shifts LLMs towards risk aversion, with models that incorporate all three ethical dimensions exhibiting the most conservative investment behavior. Replicating a prior study that used LLMs to predict corporate investments from company earnings call transcripts, we demonstrate that although some alignment can improve the accuracy of investment forecasts, excessive alignment results in overly cautious predictions. These findings suggest that deploying excessively aligned LLMs in financial decision-making could lead to severe underinvestment. We underline the need for a nuanced approach that carefully balances the degree of ethical alignment with the specific requirements of economic domains when leveraging LLMs within finance.
6/4/2024

Self-Alignment of Large Language Models via Monopolylogue-based Social Scene Simulation
Xianghe Pang, Shuo Tang, Rui Ye, Yuxin Xiong, Bolun Zhang, Yanfeng Wang, Siheng Chen
0
0
Aligning large language models (LLMs) with human values is imperative to mitigate potential adverse effects resulting from their misuse. Drawing from the sociological insight that acknowledging all parties' concerns is a key factor in shaping human values, this paper proposes a novel direction to align LLMs by themselves: social scene simulation. To achieve this, we present MATRIX, a novel social scene simulator that emulates realistic scenes around a user's input query, enabling the LLM to take social consequences into account before responding. MATRIX serves as a virtual rehearsal space, akin to a Monopolylogue, where the LLM performs diverse roles related to the query and practice by itself. To inject this alignment, we fine-tune the LLM with MATRIX-simulated data, ensuring adherence to human values without compromising inference speed. We theoretically show that the LLM with MATRIX outperforms Constitutional AI under mild assumptions. Finally, extensive experiments validate that our method outperforms over 10 baselines across 4 benchmarks. As evidenced by 875 user ratings, our tuned 13B-size LLM exceeds GPT-4 in aligning with human values. See our project page at https://shuotang123.github.io/MATRIX.
6/11/2024
🧠
Assessing and Verifying Task Utility in LLM-Powered Applications
Negar Arabzadeh, Siqing Huo, Nikhil Mehta, Qinqyun Wu, Chi Wang, Ahmed Awadallah, Charles L. A. Clarke, Julia Kiseleva
0
0
The rapid development of Large Language Models (LLMs) has led to a surge in applications that facilitate collaboration among multiple agents, assisting humans in their daily tasks. However, a significant gap remains in assessing to what extent LLM-powered applications genuinely enhance user experience and task execution efficiency. This highlights the need to verify utility of LLM-powered applications, particularly by ensuring alignment between the application's functionality and end-user needs. We introduce AgentEval, a novel framework designed to simplify the utility verification process by automatically proposing a set of criteria tailored to the unique purpose of any given application. This allows for a comprehensive assessment, quantifying the utility of an application against the suggested criteria. We present a comprehensive analysis of the effectiveness and robustness of AgentEval for two open source datasets including Math Problem solving and ALFWorld House-hold related tasks. For reproducibility purposes, we make the data, code and all the logs publicly available at https://bit.ly/3w3yKcS .
5/14/2024
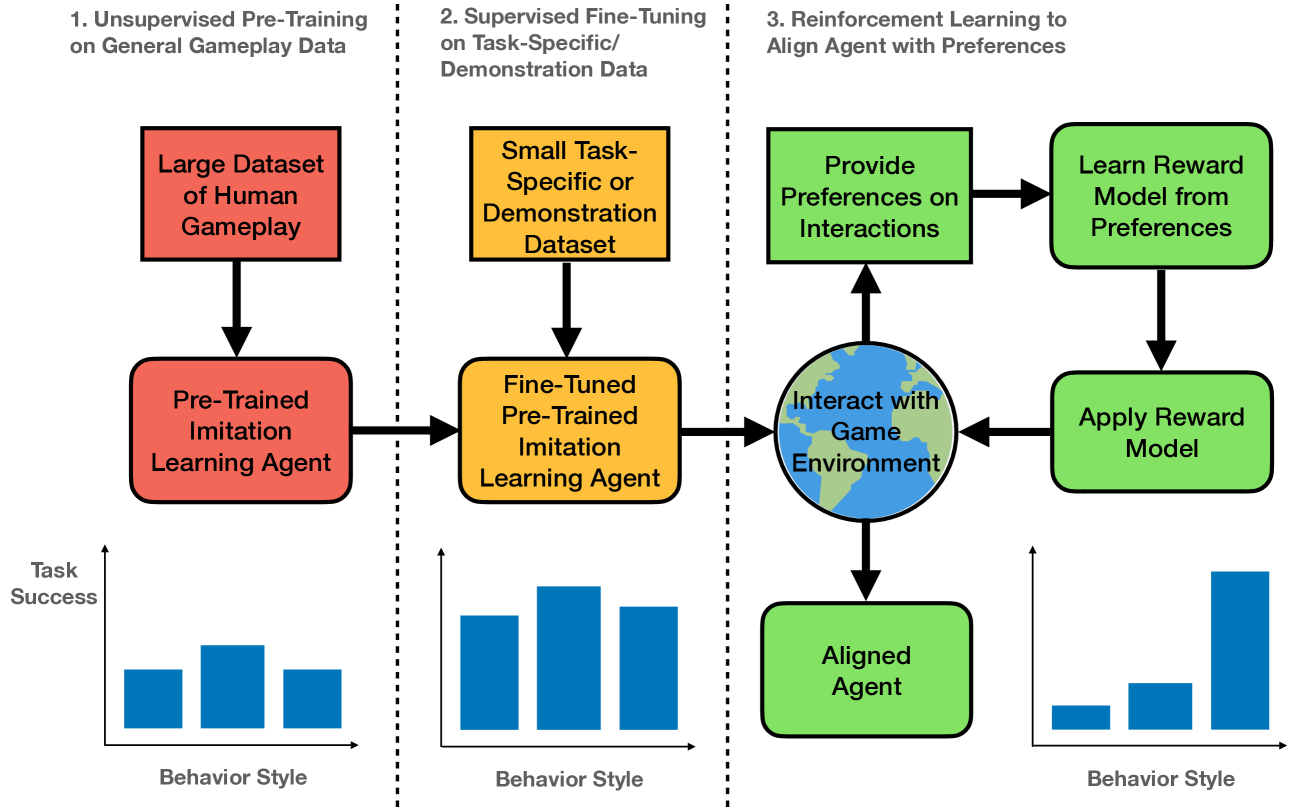
Aligning Agents like Large Language Models
Adam Jelley, Yuhan Cao, Dave Bignell, Sam Devlin, Tabish Rashid
0
0
Training agents to behave as desired in complex 3D environments from high-dimensional sensory information is challenging. Imitation learning from diverse human behavior provides a scalable approach for training an agent with a sensible behavioral prior, but such an agent may not perform the specific behaviors of interest when deployed. To address this issue, we draw an analogy between the undesirable behaviors of imitation learning agents and the unhelpful responses of unaligned large language models (LLMs). We then investigate how the procedure for aligning LLMs can be applied to aligning agents in a 3D environment from pixels. For our analysis, we utilize an academically illustrative part of a modern console game in which the human behavior distribution is multi-modal, but we want our agent to imitate a single mode of this behavior. We demonstrate that we can align our agent to consistently perform the desired mode, while providing insights and advice for successfully applying this approach to training agents. Project webpage at https://adamjelley.github.io/aligning-agents-like-llms .
6/7/2024