Who Validates the Validators? Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences
2404.12272
2
0
🚀
Abstract
Due to the cumbersome nature of human evaluation and limitations of code-based evaluation, Large Language Models (LLMs) are increasingly being used to assist humans in evaluating LLM outputs. Yet LLM-generated evaluators simply inherit all the problems of the LLMs they evaluate, requiring further human validation. We present a mixed-initiative approach to ``validate the validators'' -- aligning LLM-generated evaluation functions (be it prompts or code) with human requirements. Our interface, EvalGen, provides automated assistance to users in generating evaluation criteria and implementing assertions. While generating candidate implementations (Python functions, LLM grader prompts), EvalGen asks humans to grade a subset of LLM outputs; this feedback is used to select implementations that better align with user grades. A qualitative study finds overall support for EvalGen but underscores the subjectivity and iterative process of alignment. In particular, we identify a phenomenon we dub emph{criteria drift}: users need criteria to grade outputs, but grading outputs helps users define criteria. What is more, some criteria appears emph{dependent} on the specific LLM outputs observed (rather than independent criteria that can be defined emph{a priori}), raising serious questions for approaches that assume the independence of evaluation from observation of model outputs. We present our interface and implementation details, a comparison of our algorithm with a baseline approach, and implications for the design of future LLM evaluation assistants.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Human evaluation of large language models (LLMs) is challenging and limited, leading to increased use of LLM-generated evaluators
- However, LLM-generated evaluators inherit the problems of the LLMs they evaluate, requiring further human validation
- The paper presents a "mixed-initiative" approach called EvalGen to help align LLM-generated evaluation functions with human requirements
Plain English Explanation
Evaluating the outputs of large language models (LLMs) like ChatGPT can be difficult and time-consuming for humans. As a result, researchers are increasingly using LLM-generated tools to help with this evaluation process. However, these LLM-generated evaluators simply inherit all the problems of the LLMs they are trying to evaluate, so they still need to be validated by humans.
The researchers in this paper present a new approach called EvalGen to help address this issue. EvalGen provides automated assistance to users in generating evaluation criteria and implementing assertions to assess LLM outputs. As EvalGen generates candidate evaluation functions (like Python code or prompts for LLMs), it also asks humans to grade a sample of the LLM outputs. This human feedback is then used to select the evaluation functions that best align with the user's requirements.
The researchers found that this approach was generally supported by users, but also highlighted the subjective and iterative nature of the alignment process. They observed a phenomenon they call "criteria drift" - users need initial criteria to grade outputs, but grading the outputs helps them refine and define their criteria further. Additionally, some evaluation criteria seem to depend on the specific LLM outputs observed, rather than being independent criteria that can be defined ahead of time.
These findings raise important questions for approaches that assume evaluation can be done independently of observing the model outputs, which is a common assumption in LLM evaluation research. The researchers present their interface, implementation details, and compare their approach to a baseline, providing insights for the design of future LLM evaluation assistants.
Technical Explanation
The paper presents a "mixed-initiative" approach called EvalGen to help align LLM-generated evaluation functions with human requirements. EvalGen provides automated assistance to users in generating evaluation criteria and implementing assertions to assess LLM outputs.
The EvalGen system works as follows:
- Users provide initial evaluation criteria or prompts.
- EvalGen generates candidate implementations of these criteria, such as Python functions or LLM grading prompts.
- EvalGen asks users to grade a subset of LLM outputs using these candidate implementations.
- EvalGen uses the human feedback to select the implementations that best align with the user's requirements.
The researchers conducted a qualitative study to evaluate EvalGen. They found overall support for the approach, but also identified several key challenges:
- Criteria Drift: Users need initial criteria to grade outputs, but grading the outputs helps them refine and define their criteria further. This suggests the evaluation process is iterative and subjective.
- Criteria Dependence: Some evaluation criteria appear to depend on the specific LLM outputs observed, rather than being independent criteria that can be defined a priori. This raises issues for approaches that assume evaluation can be done independently of observing model outputs.
The paper also includes a comparison of EvalGen's algorithm to a baseline approach, as well as implications for the design of future LLM evaluation assistants.
Critical Analysis
The paper highlights important challenges in the design of LLM evaluation assistants. The finding of "criteria drift" - where users refine their evaluation criteria based on observing model outputs - is a significant obstacle for approaches that assume evaluation can be done independently.
Additionally, the observation that some evaluation criteria appear to depend on the specific outputs observed, rather than being independent, is a crucial insight. This suggests that LLM evaluation may require an iterative, interactive process, rather than a one-time, fixed set of criteria.
While the paper presents a novel approach in EvalGen, the qualitative study reveals the inherent subjectivity and complexity of the evaluation process. The researchers acknowledge that further research is needed to fully understand the dynamics of aligning LLM-generated evaluations with human requirements.
One potential limitation of the study is the small sample size of the qualitative evaluation. Conducting a larger-scale user study could provide additional insights and help validate the findings.
Overall, this paper makes an important contribution by highlighting the challenges in developing effective LLM evaluation tools. The insights around criteria drift and dependence on observed outputs should inform the design of future evaluation systems, encouraging a more nuanced and iterative approach to assessing LLM capabilities.
Conclusion
This paper presents a mixed-initiative approach called EvalGen to help align LLM-generated evaluation functions with human requirements. While EvalGen was generally supported by users, the study uncovered significant challenges in the LLM evaluation process.
The key findings include the phenomenon of "criteria drift", where users refine their evaluation criteria based on observing model outputs, and the observation that some criteria appear to depend on the specific outputs observed, rather than being independent. These insights raise serious questions for approaches that assume evaluation can be done independently of model outputs.
The paper's findings have important implications for the design of future LLM evaluation assistants. Acknowledging the subjectivity and iterative nature of the evaluation process, as well as the potential dependence of criteria on observed outputs, will be crucial for developing effective tools to help humans assess the capabilities of large language models.
Related Papers
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Hussein Mozannar, Valerie Chen, Mohammed Alsobay, Subhro Das, Sebastian Zhao, Dennis Wei, Manish Nagireddy, Prasanna Sattigeri, Ameet Talwalkar, David Sontag
0
0
Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
4/4/2024

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024
Large Language Models are Inconsistent and Biased Evaluators
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
0
0
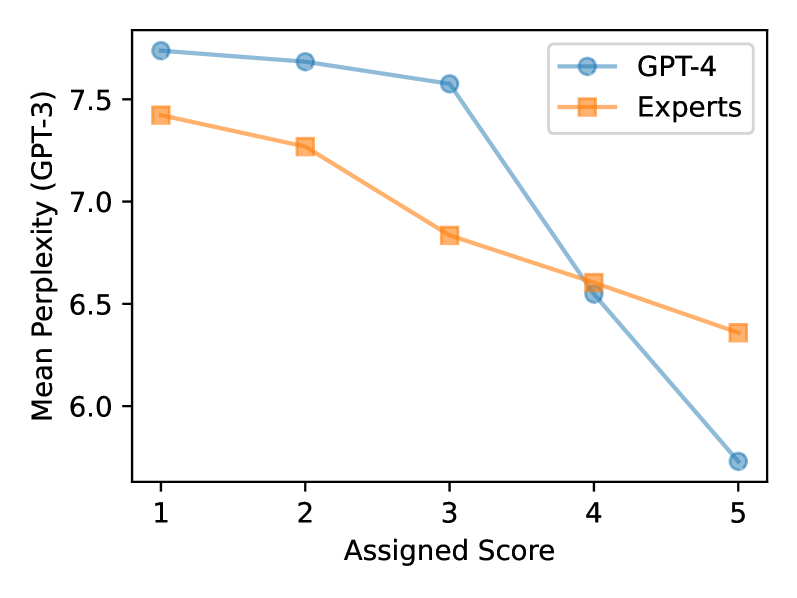
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
5/6/2024
💬
A Literature Review and Framework for Human Evaluation of Generative Large Language Models in Healthcare
Thomas Yu Chow Tam, Sonish Sivarajkumar, Sumit Kapoor, Alisa V Stolyar, Katelyn Polanska, Karleigh R McCarthy, Hunter Osterhoudt, Xizhi Wu, Shyam Visweswaran, Sunyang Fu, Piyush Mathur, Giovanni E. Cacciamani, Cong Sun, Yifan Peng, Yanshan Wang
0
0
As generative artificial intelligence (AI), particularly Large Language Models (LLMs), continues to permeate healthcare, it remains crucial to supplement traditional automated evaluations with human expert evaluation. Understanding and evaluating the generated texts is vital for ensuring safety, reliability, and effectiveness. However, the cumbersome, time-consuming, and non-standardized nature of human evaluation presents significant obstacles to the widespread adoption of LLMs in practice. This study reviews existing literature on human evaluation methodologies for LLMs within healthcare. We highlight a notable need for a standardized and consistent human evaluation approach. Our extensive literature search, adhering to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines, spans publications from January 2018 to February 2024. This review provides a comprehensive overview of the human evaluation approaches used in diverse healthcare applications.This analysis examines the human evaluation of LLMs across various medical specialties, addressing factors such as evaluation dimensions, sample types, and sizes, the selection and recruitment of evaluators, frameworks and metrics, the evaluation process, and statistical analysis of the results. Drawing from diverse evaluation strategies highlighted in these studies, we propose a comprehensive and practical framework for human evaluation of generative LLMs, named QUEST: Quality of Information, Understanding and Reasoning, Expression Style and Persona, Safety and Harm, and Trust and Confidence. This framework aims to improve the reliability, generalizability, and applicability of human evaluation of generative LLMs in different healthcare applications by defining clear evaluation dimensions and offering detailed guidelines.
5/7/2024