Aligning Agents like Large Language Models
2406.04208
0
0
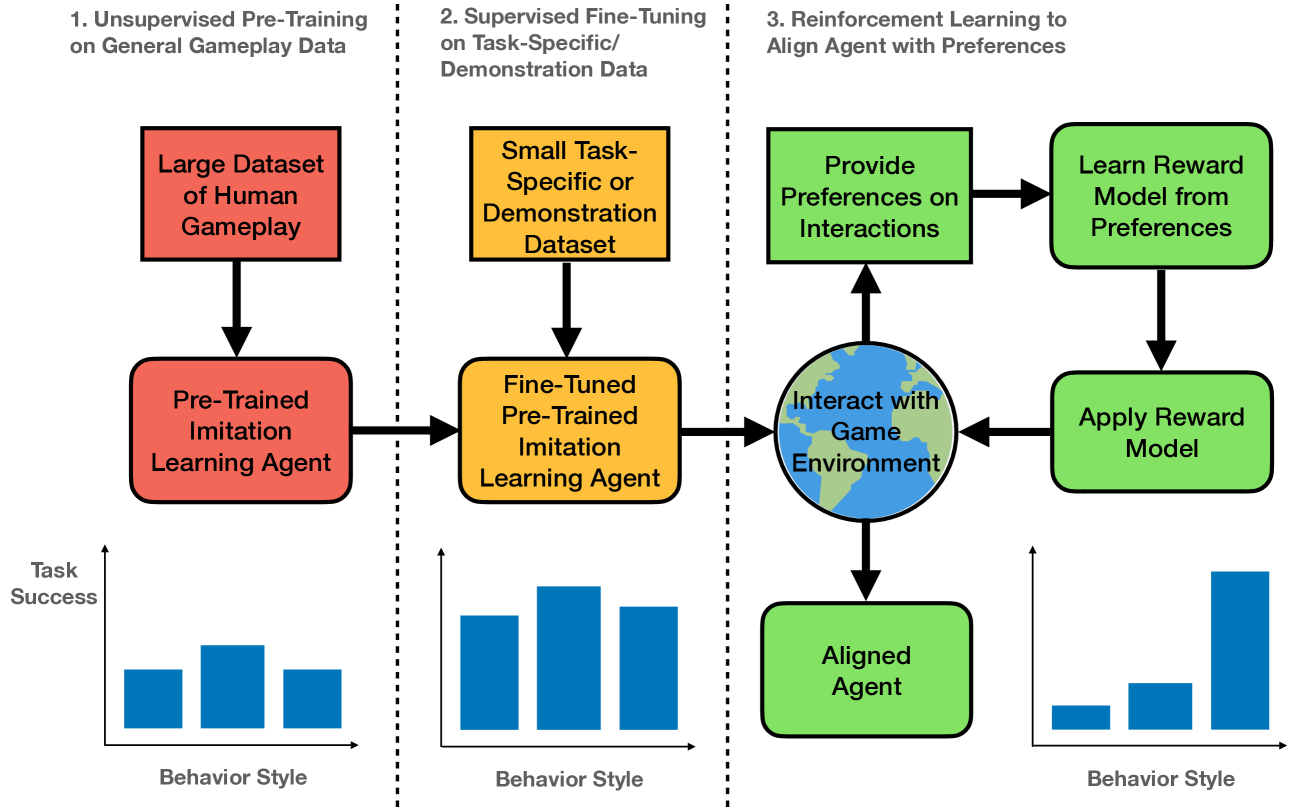
Abstract
Training agents to behave as desired in complex 3D environments from high-dimensional sensory information is challenging. Imitation learning from diverse human behavior provides a scalable approach for training an agent with a sensible behavioral prior, but such an agent may not perform the specific behaviors of interest when deployed. To address this issue, we draw an analogy between the undesirable behaviors of imitation learning agents and the unhelpful responses of unaligned large language models (LLMs). We then investigate how the procedure for aligning LLMs can be applied to aligning agents in a 3D environment from pixels. For our analysis, we utilize an academically illustrative part of a modern console game in which the human behavior distribution is multi-modal, but we want our agent to imitate a single mode of this behavior. We demonstrate that we can align our agent to consistently perform the desired mode, while providing insights and advice for successfully applying this approach to training agents. Project webpage at https://adamjelley.github.io/aligning-agents-like-llms .
Create account to get full access
Overview
- The paper explores the challenge of aligning large language models (LLMs) with human values and preferences, a crucial issue as these models become more advanced and influential.
- It proposes a game environment and alignment goal to study this problem, building on previous research on aligning agents like LLMs, understanding the learning dynamics of alignment with human feedback, and using LLMs as policy teachers for agent training.
- The paper also provides a survey of LLM-based game agents to contextualize the research.
- The goal is to develop AI models that are well-aligned with human values to ensure they behave in ways that are beneficial to humanity.
Plain English Explanation
As large language models (LLMs) become more advanced and influential, it's crucial to ensure they are aligned with human values and preferences. This paper proposes a game environment and alignment goal to study this challenge.
The researchers build on previous work that has explored ways to better align agents like LLMs with human values, understand how agents learn to align with human feedback, and use LLMs to help train other agents. They also provide an overview of existing research on LLM-based game agents.
The goal is to develop AI models that are well-aligned with human values, so that they behave in ways that are beneficial to humanity. This is a complex challenge, as LLMs can be very powerful but may not naturally share human values or preferences. The researchers hope that by studying this problem in a game environment, they can make progress towards creating AI systems that are reliably aligned with what humans consider to be good and desirable.
Technical Explanation
The paper proposes a game environment and alignment goal to study the challenge of aligning large language models (LLMs) with human values and preferences. This builds on previous work in several related areas:
-
Aligning agents like large language models: Research on techniques to better align the behavior of agents, including LLMs, with human values.
-
Understanding the learning dynamics of alignment with human feedback: Studies on how agents can learn to align their behavior with human feedback and preferences.
-
Using LLMs as policy teachers for agent training: Exploring the use of LLMs to help train other AI agents by providing guidance on desirable behaviors.
-
A survey of LLM-based game agents: An overview of existing research on the use of LLMs in the context of game agents.
The proposed game environment and alignment goal aim to provide a framework for studying the development of AI models that are well-aligned with human values. This is a crucial challenge as LLMs become more powerful and influential, to ensure they behave in ways that are beneficial to humanity.
Critical Analysis
The paper provides a well-structured approach to studying the alignment of LLMs with human values, building on relevant prior research. However, some potential limitations and areas for further exploration are worth considering:
-
The proposed game environment may not fully capture the complexity of real-world interactions and value alignment challenges that LLMs may face. More research may be needed to explore the scalability and generalization of the insights gained from this simplified setting.
-
The paper does not delve into potential biases or ethical concerns that may arise from using LLMs as policy teachers or from the alignment process itself. These issues should be carefully considered, as they can have significant implications for the development of truly beneficial AI systems.
-
The survey of LLM-based game agents provides useful context, but a more in-depth analysis of the strengths, weaknesses, and lessons learned from these existing approaches could further inform the research presented in this paper.
-
Ultimately, the success of the proposed approach will depend on the ability to translate the insights gained in the game environment into effective techniques for aligning LLMs with human values in real-world applications. Careful validation and testing will be crucial.
Conclusion
This paper presents a promising approach to addressing the challenge of aligning large language models (LLMs) with human values and preferences. By proposing a game environment and alignment goal, the researchers are leveraging insights from previous work to develop a framework for studying this critical issue.
As LLMs become increasingly powerful and influential, ensuring their behavior is well-aligned with human values is essential to ensure they benefit humanity. The proposed research, combined with ongoing work in related areas, represents an important step towards creating AI systems that reliably act in ways that are consistent with human preferences and ethical considerations.
While there are some potential limitations and areas for further exploration, the paper provides a solid foundation for continued research and development in this crucial domain. Ultimately, the successful alignment of LLMs with human values will be a key milestone in the responsible advancement of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
The Real, the Better: Aligning Large Language Models with Online Human Behaviors
Guanying Jiang, Lingyong Yan, Haibo Shi, Dawei Yin
0
0
Large language model alignment is widely used and studied to avoid LLM producing unhelpful and harmful responses. However, the lengthy training process and predefined preference bias hinder adaptation to online diverse human preferences. To this end, this paper proposes an alignment framework, called Reinforcement Learning with Human Behavior (RLHB), to align LLMs by directly leveraging real online human behaviors. By taking the generative adversarial framework, the generator is trained to respond following expected human behavior; while the discriminator tries to verify whether the triplets of query, response, and human behavior come from real online environments. Behavior modeling in natural-language form and the multi-model joint training mechanism enable an active and sustainable online alignment. Experimental results confirm the effectiveness of our proposed methods by both human and automatic evaluations.
5/2/2024

Understanding the Learning Dynamics of Alignment with Human Feedback
Shawn Im, Yixuan Li
0
0
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
4/17/2024
💬
RecExplainer: Aligning Large Language Models for Explaining Recommendation Models
Yuxuan Lei, Jianxun Lian, Jing Yao, Xu Huang, Defu Lian, Xing Xie
0
0
Recommender systems are widely used in online services, with embedding-based models being particularly popular due to their expressiveness in representing complex signals. However, these models often function as a black box, making them less transparent and reliable for both users and developers. Recently, large language models (LLMs) have demonstrated remarkable intelligence in understanding, reasoning, and instruction following. This paper presents the initial exploration of using LLMs as surrogate models to explaining black-box recommender models. The primary concept involves training LLMs to comprehend and emulate the behavior of target recommender models. By leveraging LLMs' own extensive world knowledge and multi-step reasoning abilities, these aligned LLMs can serve as advanced surrogates, capable of reasoning about observations. Moreover, employing natural language as an interface allows for the creation of customizable explanations that can be adapted to individual user preferences. To facilitate an effective alignment, we introduce three methods: behavior alignment, intention alignment, and hybrid alignment. Behavior alignment operates in the language space, representing user preferences and item information as text to mimic the target model's behavior; intention alignment works in the latent space of the recommendation model, using user and item representations to understand the model's behavior; hybrid alignment combines both language and latent spaces. Comprehensive experiments conducted on three public datasets show that our approach yields promising results in understanding and mimicking target models, producing high-quality, high-fidelity, and distinct explanations. Our code is available at https://github.com/microsoft/RecAI.
6/26/2024
💬
Large Language Model as a Policy Teacher for Training Reinforcement Learning Agents
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, Bin Liu
0
0
Recent studies have uncovered the potential of Large Language Models (LLMs) in addressing complex sequential decision-making tasks through the provision of high-level instructions. However, LLM-based agents lack specialization in tackling specific target problems, particularly in real-time dynamic environments. Additionally, deploying an LLM-based agent in practical scenarios can be both costly and time-consuming. On the other hand, reinforcement learning (RL) approaches train agents that specialize in the target task but often suffer from low sampling efficiency and high exploration costs. In this paper, we introduce a novel framework that addresses these challenges by training a smaller, specialized student RL agent using instructions from an LLM-based teacher agent. By incorporating the guidance from the teacher agent, the student agent can distill the prior knowledge of the LLM into its own model. Consequently, the student agent can be trained with significantly less data. Moreover, through further training with environment feedback, the student agent surpasses the capabilities of its teacher for completing the target task. We conducted experiments on challenging MiniGrid and Habitat environments, specifically designed for embodied AI research, to evaluate the effectiveness of our framework. The results clearly demonstrate that our approach achieves superior performance compared to strong baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
4/23/2024