Automatic Discovery of Visual Circuits
2404.14349
0
0

Abstract
To date, most discoveries of network subcomponents that implement human-interpretable computations in deep vision models have involved close study of single units and large amounts of human labor. We explore scalable methods for extracting the subgraph of a vision model's computational graph that underlies recognition of a specific visual concept. We introduce a new method for identifying these subgraphs: specifying a visual concept using a few examples, and then tracing the interdependence of neuron activations across layers, or their functional connectivity. We find that our approach extracts circuits that causally affect model output, and that editing these circuits can defend large pretrained models from adversarial attacks.
Create account to get full access
Overview
- This paper proposes a method for automatically discovering the underlying visual circuits in deep learning models for computer vision tasks.
- The authors introduce a technique called Automated Circuit Extraction (ACE) that can extract the functional circuits within vision models, revealing how they process and represent visual concepts.
- The paper demonstrates the application of ACE to various vision models, including Visual Concept Connectome (VCC), Inherent Adversarial Robustness, and Concept-Based Analysis, providing insights into the internal workings of these systems.
Plain English Explanation
Deep learning models for computer vision can be very powerful, but they can also be complex "black boxes" - it's not always clear how they process and understand the images they're shown. The authors of this paper wanted to open up these black boxes and reveal the underlying "circuits" that the models use to perform their tasks.
Imagine a vision model as a complex electronic circuit, with different components (like resistors, capacitors, and transistors) that all work together to process the input image. The authors developed a technique called Automated Circuit Extraction (ACE) that can analyze the model and identify these different circuit components and how they're connected.
By applying ACE to various vision models, the researchers were able to gain new insights into how these models work. For example, they could see how the models represent different visual concepts, like "car" or "face", and how those concepts are connected to each other. This type of information can be very valuable for understanding the strengths and limitations of these vision systems, and for improving them in the future.
The paper demonstrates ACE on several well-known vision models, including Visual Concept Connectome (VCC), Inherent Adversarial Robustness, and Concept-Based Analysis. By revealing the inner workings of these models, the authors hope to shed light on how computer vision systems process and understand the world around them.
Technical Explanation
The paper introduces a technique called Automated Circuit Extraction (ACE) that can automatically discover the underlying visual circuits within deep learning models for computer vision tasks. ACE works by analyzing the activation patterns and functional connectivity of the neurons in a vision model, and then using this information to identify the key circuit components and their interconnections.
The authors demonstrate the application of ACE to several state-of-the-art vision models, including Visual Concept Connectome (VCC), Inherent Adversarial Robustness, and Concept-Based Analysis. By extracting the visual circuits within these models, the researchers were able to gain new insights into how the models process and represent visual information.
For example, the analysis of the VCC model revealed a rich network of interconnected visual concepts, highlighting the complex ways in which these models build an understanding of the visual world. The Inherent Adversarial Robustness model was shown to have specialized circuits for processing different types of visual features, which helps explain its resilience to adversarial attacks. And the Concept-Based Analysis model was found to have a modular structure, with distinct circuits for different visual concepts that could be selectively activated.
Overall, the ACE technique provides a powerful tool for opening up the "black box" of deep learning vision models and gaining a deeper understanding of their inner workings. By revealing the visual circuits that underlie these models, the authors hope to pave the way for more transparent and interpretable computer vision systems.
Critical Analysis
The paper presents a promising approach for automatically uncovering the visual circuits within deep learning models, but there are a few potential limitations and areas for further research that could be explored.
One potential concern is the scalability of the ACE technique to very large and complex vision models. While the authors demonstrate its effectiveness on several state-of-the-art models, it's unclear how well the method would scale to the massive neural networks used in the latest computer vision breakthroughs. Extending the ACE approach to handle these larger and more sophisticated models could be an important area for future research.
Additionally, the paper focuses primarily on analyzing the extracted visual circuits, but it doesn't delve deeply into how this information could be used to improve or modify the underlying vision models. Exploring strategies for leveraging the insights gained from ACE to enhance model performance, robustness, or interpretability could be a fruitful direction for further work.
Another potential limitation is that the ACE technique is currently limited to analyzing the feedforward connections within vision models, and does not account for the role of recurrent or feedback connections. Incorporating these types of connections into the circuit discovery process could provide an even more comprehensive understanding of the models' internal dynamics.
Despite these potential areas for improvement, the paper represents an important step forward in the pursuit of more transparent and interpretable computer vision systems. By shedding light on the inner workings of these deep learning models, the ACE technique opens up new possibilities for better understanding and improving the way they process and represent visual information.
Conclusion
This paper introduces a novel technique called Automated Circuit Extraction (ACE) that can automatically discover the underlying visual circuits within deep learning models for computer vision tasks. By applying ACE to several state-of-the-art vision models, the authors were able to gain new insights into how these models process and represent visual information.
The findings from this research demonstrate the potential of circuit-level analysis to open up the "black box" of deep learning and provide a more transparent understanding of how these powerful vision systems work. The insights gained from ACE could have important implications for the development of more robust, interpretable, and trustworthy computer vision technologies.
While the paper highlights some promising directions, there are also opportunities for further research to address the scalability, comprehensiveness, and practical applications of the ACE approach. Nonetheless, this work represents an important step forward in the quest to demystify the inner workings of deep learning and pave the way for more transparent and accountable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

From Feature Visualization to Visual Circuits: Effect of Adversarial Model Manipulation
Geraldin Nanfack, Michael Eickenberg, Eugene Belilovsky
0
0
Understanding the inner working functionality of large-scale deep neural networks is challenging yet crucial in several high-stakes applications. Mechanistic inter- pretability is an emergent field that tackles this challenge, often by identifying human-understandable subgraphs in deep neural networks known as circuits. In vision-pretrained models, these subgraphs are usually interpreted by visualizing their node features through a popular technique called feature visualization. Recent works have analyzed the stability of different feature visualization types under the adversarial model manipulation framework. This paper starts by addressing limitations in existing works by proposing a novel attack called ProxPulse that simultaneously manipulates the two types of feature visualizations. Surprisingly, when analyzing these attacks under the umbrella of visual circuits, we find that visual circuits show some robustness to ProxPulse. We, therefore, introduce a new attack based on ProxPulse that unveils the manipulability of visual circuits, shedding light on their lack of robustness. The effectiveness of these attacks is validated using pre-trained AlexNet and ResNet-50 models on ImageNet.
6/4/2024
🤿
Visual Concept Connectome (VCC): Open World Concept Discovery and their Interlayer Connections in Deep Models
Matthew Kowal, Richard P. Wildes, Konstantinos G. Derpanis
0
0
Understanding what deep network models capture in their learned representations is a fundamental challenge in computer vision. We present a new methodology to understanding such vision models, the Visual Concept Connectome (VCC), which discovers human interpretable concepts and their interlayer connections in a fully unsupervised manner. Our approach simultaneously reveals fine-grained concepts at a layer, connection weightings across all layers and is amendable to global analysis of network structure (e.g., branching pattern of hierarchical concept assemblies). Previous work yielded ways to extract interpretable concepts from single layers and examine their impact on classification, but did not afford multilayer concept analysis across an entire network architecture. Quantitative and qualitative empirical results show the effectiveness of VCCs in the domain of image classification. Also, we leverage VCCs for the application of failure mode debugging to reveal where mistakes arise in deep networks.
4/11/2024
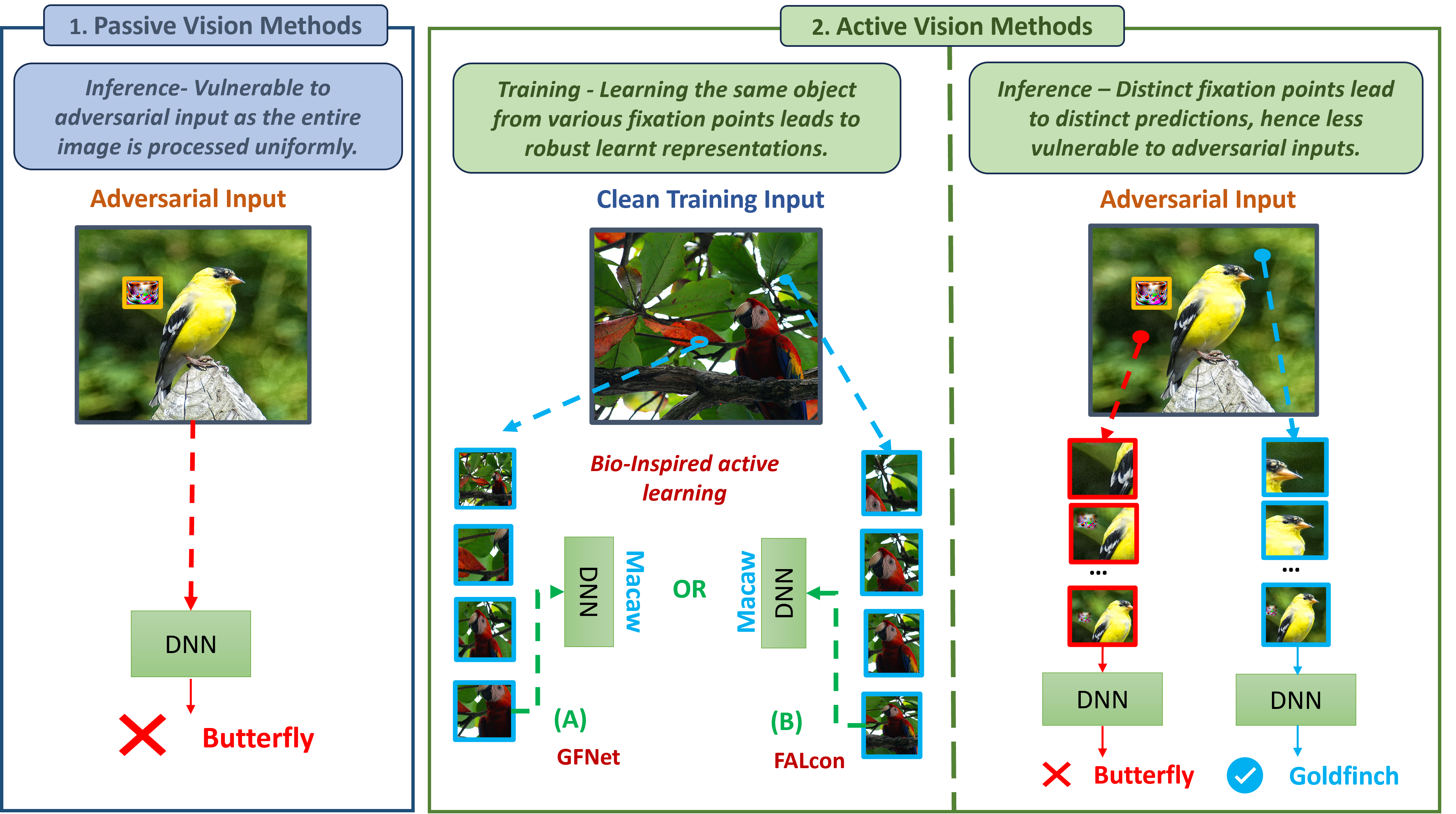
On Inherent Adversarial Robustness of Active Vision Systems
Amitangshu Mukherjee, Timur Ibrayev, Kaushik Roy
0
0
Current Deep Neural Networks are vulnerable to adversarial examples, which alter their predictions by adding carefully crafted noise. Since human eyes are robust to such inputs, it is possible that the vulnerability stems from the standard way of processing inputs in one shot by processing every pixel with the same importance. In contrast, neuroscience suggests that the human vision system can differentiate salient features by (1) switching between multiple fixation points (saccades) and (2) processing the surrounding with a non-uniform external resolution (foveation). In this work, we advocate that the integration of such active vision mechanisms into current deep learning systems can offer robustness benefits. Specifically, we empirically demonstrate the inherent robustness of two active vision methods - GFNet and FALcon - under a black box threat model. By learning and inferencing based on downsampled glimpses obtained from multiple distinct fixation points within an input, we show that these active methods achieve (2-3) times greater robustness compared to a standard passive convolutional network under state-of-the-art adversarial attacks. More importantly, we provide illustrative and interpretable visualization analysis that demonstrates how performing inference from distinct fixation points makes active vision methods less vulnerable to malicious inputs.
4/8/2024
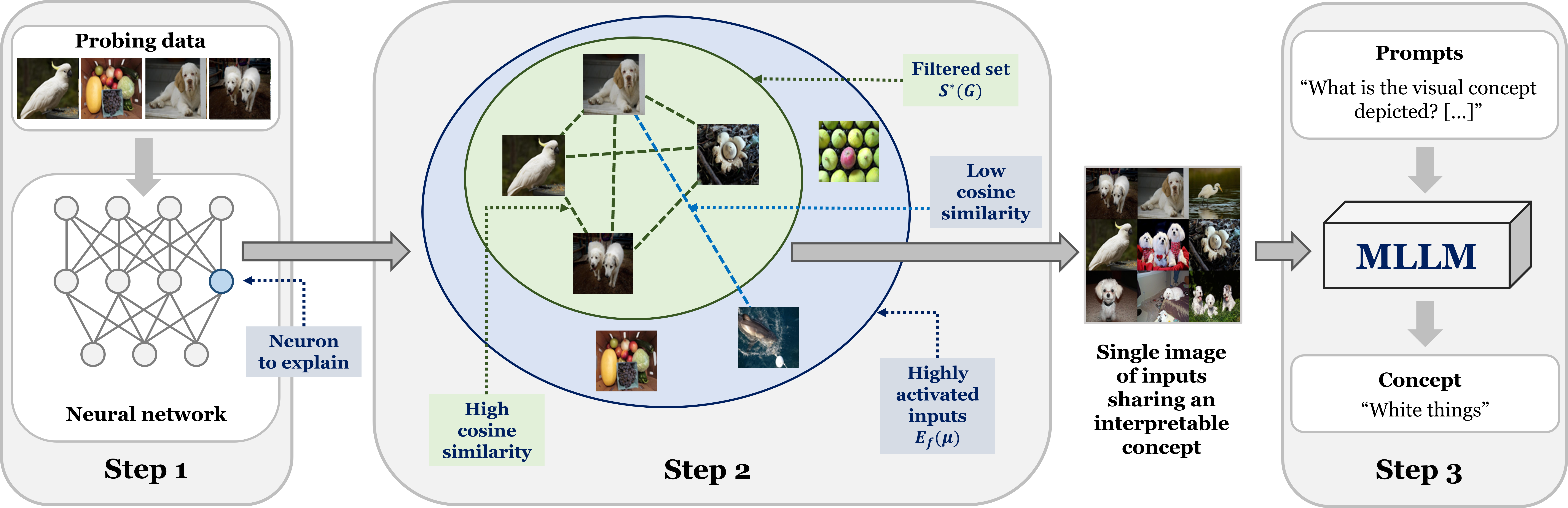
LLM-assisted Concept Discovery: Automatically Identifying and Explaining Neuron Functions
Nhat Hoang-Xuan, Minh Vu, My T. Thai
0
0
Providing textual concept-based explanations for neurons in deep neural networks (DNNs) is of importance in understanding how a DNN model works. Prior works have associated concepts with neurons based on examples of concepts or a pre-defined set of concepts, thus limiting possible explanations to what the user expects, especially in discovering new concepts. Furthermore, defining the set of concepts requires manual work from the user, either by directly specifying them or collecting examples. To overcome these, we propose to leverage multimodal large language models for automatic and open-ended concept discovery. We show that, without a restricted set of pre-defined concepts, our method gives rise to novel interpretable concepts that are more faithful to the model's behavior. To quantify this, we validate each concept by generating examples and counterexamples and evaluating the neuron's response on this new set of images. Collectively, our method can discover concepts and simultaneously validate them, providing a credible automated tool to explain deep neural networks.
6/14/2024