Aligning Large Language Models with Representation Editing: A Control Perspective
2406.05954
0
0

Abstract
Aligning large language models (LLMs) with human objectives is crucial for real-world applications. However, fine-tuning LLMs for alignment often suffers from unstable training and requires substantial computing resources. Test-time alignment techniques, such as prompting and guided decoding, do not modify the underlying model, and their performance remains dependent on the original model's capabilities. To address these challenges, we propose aligning LLMs through representation editing. The core of our method is to view a pre-trained autoregressive LLM as a discrete-time stochastic dynamical system. To achieve alignment for specific objectives, we introduce external control signals into the state space of this language dynamical system. We train a value function directly on the hidden states according to the Bellman equation, enabling gradient-based optimization to obtain the optimal control signals at test time. Our experiments demonstrate that our method outperforms existing test-time alignment techniques while requiring significantly fewer resources compared to fine-tuning methods.
Create account to get full access
Overview
- This paper explores a control-based approach to aligning large language models (LLMs) with desired representations, rather than direct reward modeling or fine-tuning.
- The authors propose a novel "representation editing" technique that allows for targeted adjustments to the internal representations of LLMs to better align them with specific objectives.
- The paper demonstrates the effectiveness of this approach through various experiments, including language model prompting, commonsense reasoning, and safety-critical tasks.
Plain English Explanation
The researchers behind this paper are trying to find a better way to "align" large language models (LLMs) - powerful AI systems that can generate human-like text - with our desired goals and values. Rather than just fine-tuning the models or directly rewarding specific behaviors, the team developed a new technique called "representation editing."
The key idea is that instead of only changing the final outputs of the LLM, you can actually go inside the model and make targeted adjustments to the way it represents and processes information. This allows for more precise and nuanced alignment, without just blindly pushing the model towards a particular set of behaviors.
Through a series of experiments, the researchers show that this representation editing approach can help LLMs perform better on tasks that require commonsense reasoning, adherence to safety guidelines, and other desirable capabilities. By directly shaping the internal workings of the model, they are able to nudge it towards more aligned and beneficial outputs.
This is an important step forward in the challenge of ensuring that powerful AI systems like LLMs are working in service of human values and interests, rather than just optimizing for narrow objectives that could lead to unintended consequences. The representation editing technique offers a new tool in the ongoing effort to align large language models with our needs and priorities.
Technical Explanation
The paper proposes a novel approach to aligning large language models called "representation editing." Rather than relying on techniques like fine-tuning or direct reward modeling, the authors explore directly manipulating the internal representations of the LLM to better align it with desired objectives.
The core idea is to leverage the fact that LLMs like GPT-3 build up complex internal representations of language and concepts as they are trained on massive datasets. By identifying and adjusting these representations in targeted ways, the researchers aim to shape the model's behavior without necessarily changing its final outputs.
Through a series of experiments, the team demonstrates the effectiveness of this representation editing approach. For example, they show how it can be used to improve the model's commonsense reasoning abilities, ensure it adheres to safety-critical guidelines, and exhibit other desirable capabilities. The results suggest that this control-based technique offers a promising avenue for aligning large language models that goes beyond simple fine-tuning or reward modeling.
One key benefit of representation editing is that it allows for more nuanced and granular adjustments to the model's behavior, rather than just pushing it towards a particular set of outputs. By directly shaping the underlying representations, the approach can potentially lead to more aligned and beneficial language models that maintain flexibility and generalization while still adhering to desired principles and constraints.
Critical Analysis
The representation editing approach proposed in this paper offers a potentially powerful tool for aligning large language models with desired objectives. By going beyond simple fine-tuning or reward modeling, the technique allows for more granular and nuanced adjustments to the model's internal workings.
However, the paper does acknowledge some important limitations and caveats. For example, the specific mechanisms by which representation editing affects model behavior are not yet fully understood, and the approach may be more computationally intensive than other alignment techniques. There are also open questions around the scalability and generalization of the method to larger and more complex LLMs.
Additionally, while the experiments demonstrate the effectiveness of representation editing on specific tasks, it remains to be seen how well the approach will perform in real-world, open-ended scenarios where language models must navigate complex and ambiguous situations. Further research is needed to better understand the broader implications and potential pitfalls of this control-based alignment strategy.
Nonetheless, this paper represents an important step forward in the ongoing challenge of aligning large language models with human values and needs. By exploring novel techniques like representation editing, the researchers are expanding the toolbox available for ensuring these powerful AI systems are reliable, safe, and beneficial to society.
Conclusion
The paper "Aligning Large Language Models with Representation Editing: A Control Perspective" proposes a novel approach to the challenge of aligning large language models with desired objectives and behaviors. Rather than relying on techniques like fine-tuning or direct reward modeling, the authors explore a control-based strategy of directly manipulating the internal representations of the LLM.
Through a series of experiments, the team demonstrates the effectiveness of this representation editing approach in areas such as commonsense reasoning, safety-critical tasks, and other desirable capabilities. This suggests that the technique offers a promising avenue for aligning large language models that goes beyond simple output-level adjustments.
While the paper acknowledges some limitations and open questions, the representation editing approach represents an important step forward in the ongoing effort to embed aligned language models that can reliably and beneficially assist humans. As AI systems like LLMs become increasingly capable and pervasive, developing techniques to ensure their alignment with human values will be crucial for realizing the full potential of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Aligning Large Language Models via Fine-grained Supervision
Dehong Xu, Liang Qiu, Minseok Kim, Faisal Ladhak, Jaeyoung Do
0
0
Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
6/6/2024
💬
Privately Aligning Language Models with Reinforcement Learning
Fan Wu, Huseyin A. Inan, Arturs Backurs, Varun Chandrasekaran, Janardhan Kulkarni, Robert Sim
0
0
Positioned between pre-training and user deployment, aligning large language models (LLMs) through reinforcement learning (RL) has emerged as a prevailing strategy for training instruction following-models such as ChatGPT. In this work, we initiate the study of privacy-preserving alignment of LLMs through Differential Privacy (DP) in conjunction with RL. Following the influential work of Ziegler et al. (2020), we study two dominant paradigms: (i) alignment via RL without human in the loop (e.g., positive review generation) and (ii) alignment via RL from human feedback (RLHF) (e.g., summarization in a human-preferred way). We give a new DP framework to achieve alignment via RL, and prove its correctness. Our experimental results validate the effectiveness of our approach, offering competitive utility while ensuring strong privacy protections.
5/6/2024

Understanding the Learning Dynamics of Alignment with Human Feedback
Shawn Im, Yixuan Li
0
0
Aligning large language models (LLMs) with human intentions has become a critical task for safely deploying models in real-world systems. While existing alignment approaches have seen empirical success, theoretically understanding how these methods affect model behavior remains an open question. Our work provides an initial attempt to theoretically analyze the learning dynamics of human preference alignment. We formally show how the distribution of preference datasets influences the rate of model updates and provide rigorous guarantees on the training accuracy. Our theory also reveals an intricate phenomenon where the optimization is prone to prioritizing certain behaviors with higher preference distinguishability. We empirically validate our findings on contemporary LLMs and alignment tasks, reinforcing our theoretical insights and shedding light on considerations for future alignment approaches. Disclaimer: This paper contains potentially offensive text; reader discretion is advised.
4/17/2024
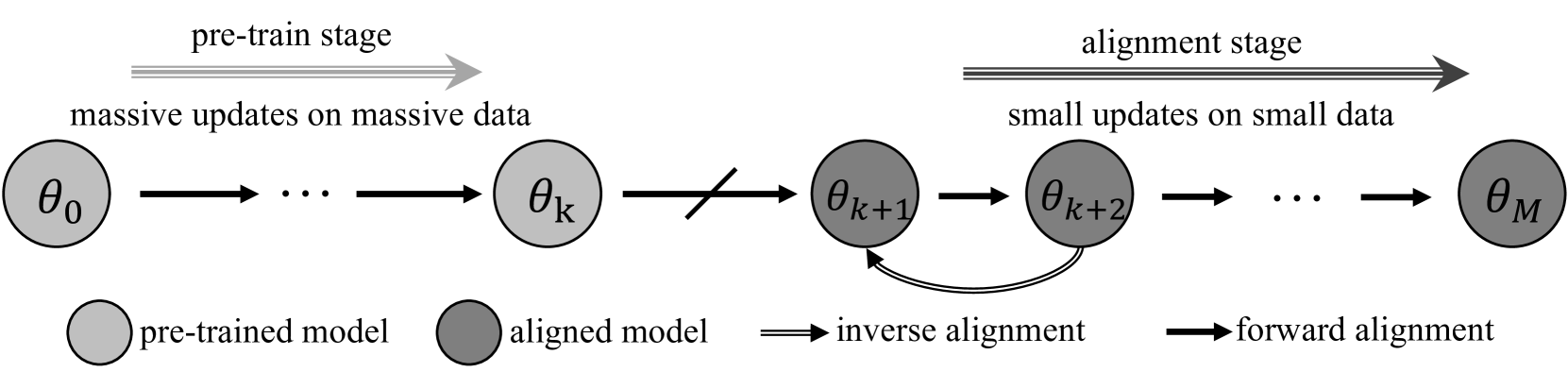
Language Models Resist Alignment
Jiaming Ji, Kaile Wang, Tianyi Qiu, Boyuan Chen, Jiayi Zhou, Changye Li, Hantao Lou, Yaodong Yang
0
0
Large language models (LLMs) may exhibit undesirable behaviors. Recent efforts have focused on aligning these models to prevent harmful generation. Despite these efforts, studies have shown that even a well-conducted alignment process can be easily circumvented, whether intentionally or accidentally. Do alignment fine-tuning have robust effects on models, or are merely superficial? In this work, we answer this question through both theoretical and empirical means. Empirically, we demonstrate the elasticity of post-alignment models, i.e., the tendency to revert to the behavior distribution formed during the pre-training phase upon further fine-tuning. Using compression theory, we formally derive that such fine-tuning process disproportionately undermines alignment compared to pre-training, potentially by orders of magnitude. We conduct experimental validations to confirm the presence of elasticity across models of varying types and sizes. Specifically, we find that model performance declines rapidly before reverting to the pre-training distribution, after which the rate of decline drops significantly. We further reveal that elasticity positively correlates with increased model size and the expansion of pre-training data. Our discovery signifies the importance of taming the inherent elasticity of LLMs, thereby overcoming the resistance of LLMs to alignment finetuning.
6/14/2024