Embedding-Aligned Language Models

0
💬
Sign in to get full access
Overview
- The paper presents a novel approach for training large language models (LLMs) to adhere to objectives defined within a latent embedding space.
- The method uses reinforcement learning (RL), treating a pre-trained LLM as an environment.
- The "Embedding-Aligned Guided Language" (EAGLE) agent is trained to steer the LLM's generation towards optimal regions of the latent embedding space, based on a predefined criterion.
- The effectiveness of EAGLE is demonstrated using the MovieLens 25M dataset to surface content gaps that satisfy latent user demand.
- The paper also shows the benefit of using an optimal design of a state-dependent action set to improve EAGLE's efficiency.
- The research paves the way for controlled and grounded text generation using LLMs, ensuring consistency with domain-specific knowledge and data representations.
Plain English Explanation
The researchers have developed a new way to train large language models (LLMs) to generate text that aligns with specific objectives. They use a technique called reinforcement learning (RL), where the LLM is treated like an "environment" that the training agent, called EAGLE, can interact with.
The EAGLE agent is trained to guide the LLM's text generation towards optimal regions of a latent (hidden) embedding space. This embedding space represents the relevant objectives or criteria that the generated text should satisfy. For example, in the MovieLens 25M dataset, the EAGLE agent was trained to find content gaps that match latent user demand.
By using this approach, the researchers can ensure that the text generated by the LLM is consistent with specific domain knowledge and data representations. This could be useful for applications like enhancing retrieval models through large language models or training large language models as generalizable policies.
The researchers also found that using an optimal design of the agent's action set (the set of possible actions it can take) can improve the efficiency of the EAGLE agent, further enhancing the controlled and grounded text generation.
Technical Explanation
The paper presents a novel approach called "Embedding-Aligned Guided Language" (EAGLE) for training large language models (LLMs) to adhere to objectives defined within a latent embedding space. The method leverages reinforcement learning (RL), treating a pre-trained LLM as an environment.
The EAGLE agent is trained to iteratively steer the LLM's generation towards optimal regions of the latent embedding space, with respect to some predefined criterion. This is achieved by using the LLM as the environment and the EAGLE agent as the policy that interacts with this environment to generate text that satisfies the desired objectives.
The researchers demonstrate the effectiveness of the EAGLE agent using the MovieLens 25M dataset, where the goal is to surface content gaps that satisfy latent user demand. They also show the benefit of using an optimal design of a state-dependent action set to improve EAGLE's efficiency.
The paper's key insights include the ability to control and ground the text generation of LLMs, ensuring consistency with domain-specific knowledge and data representations. This paves the way for applications like using large language models as policy teachers or enhancing embedding performance through large language models.
Critical Analysis
The paper presents a compelling approach for controlling and grounding the text generation of large language models (LLMs). However, there are a few potential limitations and areas for further research:
-
The method relies on a pre-trained LLM as the environment, which may limit its applicability to cases where such a model is not available or suitable. Exploring ways to train the EAGLE agent from scratch or with different types of environments could expand the method's flexibility.
-
The paper focuses on a specific use case (the MovieLens 25M dataset) and does not provide a comprehensive evaluation of the EAGLE agent's performance across a broader range of tasks or datasets. Further research is needed to assess the generalizability of the approach.
-
The paper does not discuss the computational and resource requirements of the EAGLE training process, which could be an important consideration for practical applications. Understanding the scalability and efficiency of the method would be valuable.
-
While the paper mentions the potential for controlled and grounded text generation using LLMs, it does not explore the societal implications or ethical considerations of such capabilities. Further research could investigate these important aspects.
Overall, the paper presents a promising approach for aligning LLM generation with specific objectives, but additional research and evaluation are needed to fully understand the method's capabilities, limitations, and broader implications.
Conclusion
The researchers have developed a novel approach called "Embedding-Aligned Guided Language" (EAGLE) that uses reinforcement learning to train large language models (LLMs) to generate text that adheres to objectives defined within a latent embedding space. This method enables controlled and grounded text generation, ensuring consistency with domain-specific knowledge and data representations.
The effectiveness of the EAGLE agent is demonstrated using the MovieLens 25M dataset, where it is able to surface content gaps that satisfy latent user demand. The paper also highlights the benefit of using an optimal design of the agent's action set to improve its efficiency.
This research paves the way for a range of applications, such as enhancing retrieval models through large language models, using large language models as policy teachers, and leveraging large language models as generalizable policies. However, further research is needed to address potential limitations and explore the broader implications of this approach for controlled and grounded text generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Embedding-Aligned Language Models
Guy Tennenholtz, Yinlam Chow, Chih-Wei Hsu, Lior Shani, Ethan Liang, Craig Boutilier
We propose a novel approach for training large language models (LLMs) to adhere to objectives defined within a latent embedding space. Our method leverages reinforcement learning (RL), treating a pre-trained LLM as an environment. Our embedding-aligned guided language (EAGLE) agent is trained to iteratively steer the LLM's generation towards optimal regions of the latent embedding space, w.r.t. some predefined criterion. We demonstrate the effectiveness of the EAGLE agent using the MovieLens 25M dataset to surface content gaps that satisfy latent user demand. We also demonstrate the benefit of using an optimal design of a state-dependent action set to improve EAGLE's efficiency. Our work paves the way for controlled and grounded text generation using LLMs, ensuring consistency with domain-specific knowledge and data representations.
Read more6/4/2024
0
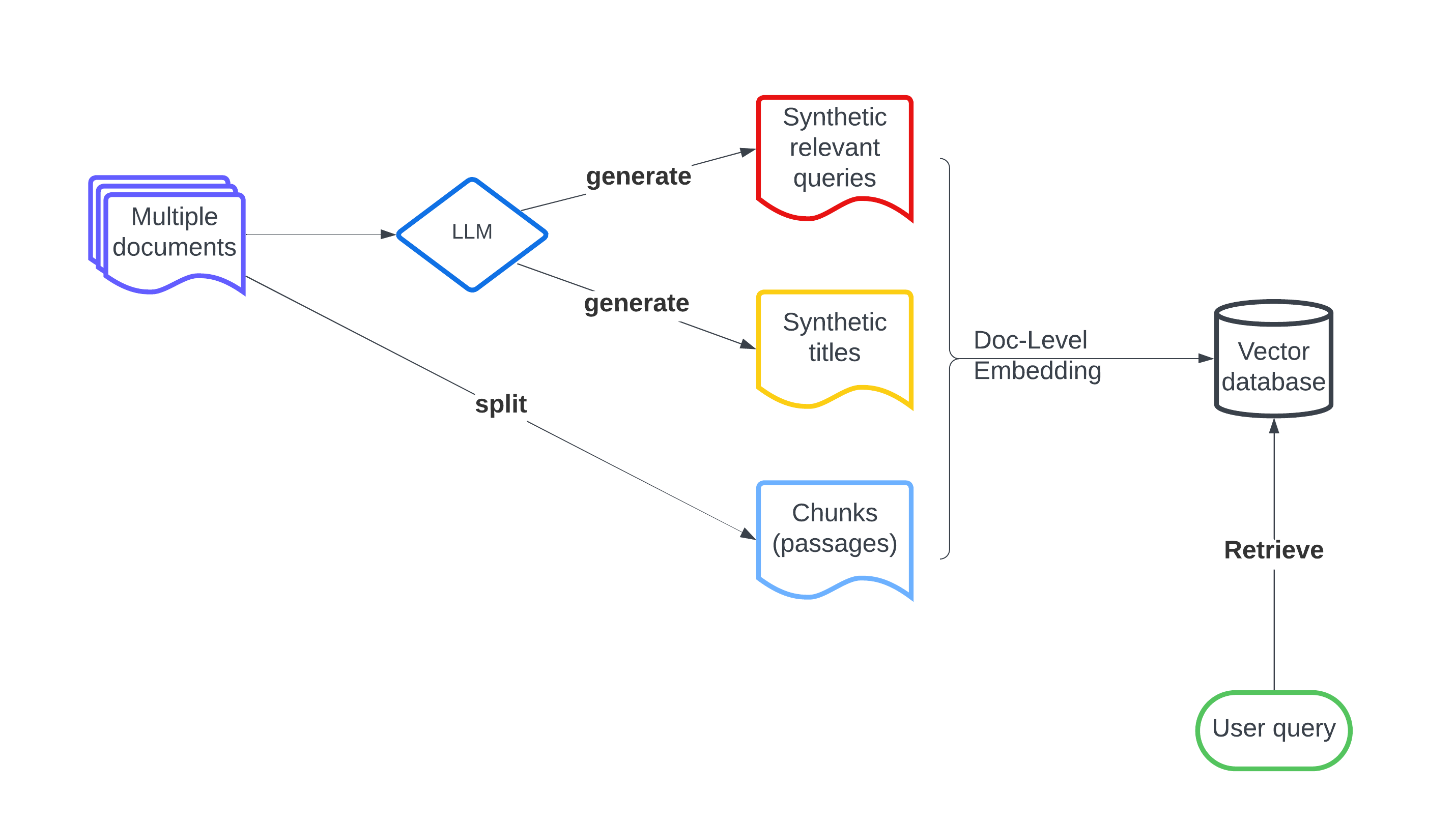
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
Read more4/10/2024
💬
0
When large language models meet evolutionary algorithms
Wang Chao, Jiaxuan Zhao, Licheng Jiao, Lingling Li, Fang Liu, Shuyuan Yang
Pre-trained large language models (LLMs) have powerful capabilities for generating creative natural text. Evolutionary algorithms (EAs) can discover diverse solutions to complex real-world problems. Motivated by the common collective and directionality of text generation and evolution, this paper illustrates the parallels between LLMs and EAs, which includes multiple one-to-one key characteristics: token representation and individual representation, position encoding and fitness shaping, position embedding and selection, Transformers block and reproduction, and model training and parameter adaptation. By examining these parallels, we analyze existing interdisciplinary research, with a specific focus on evolutionary fine-tuning and LLM-enhanced EAs. Drawing from these insights, valuable future directions are presented for advancing the integration of LLMs and EAs, while highlighting key challenges along the way. These parallels not only reveal the evolution mechanism behind LLMs but also facilitate the development of evolved artificial agents that approach or surpass biological organisms.
Read more7/2/2024
0
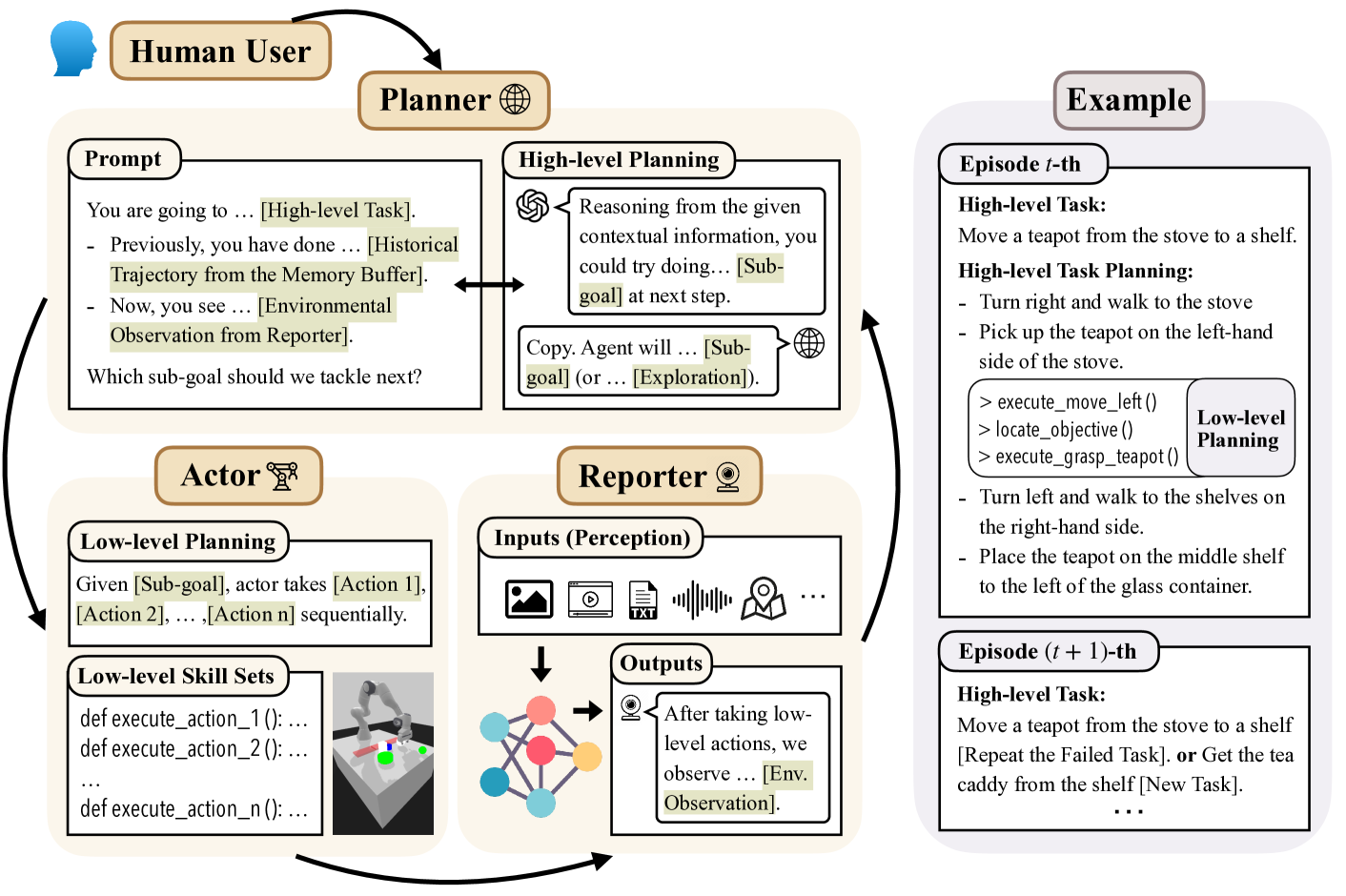
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
Read more7/23/2024