Aligning Teacher with Student Preferences for Tailored Training Data Generation
2406.19227
0
0
Abstract
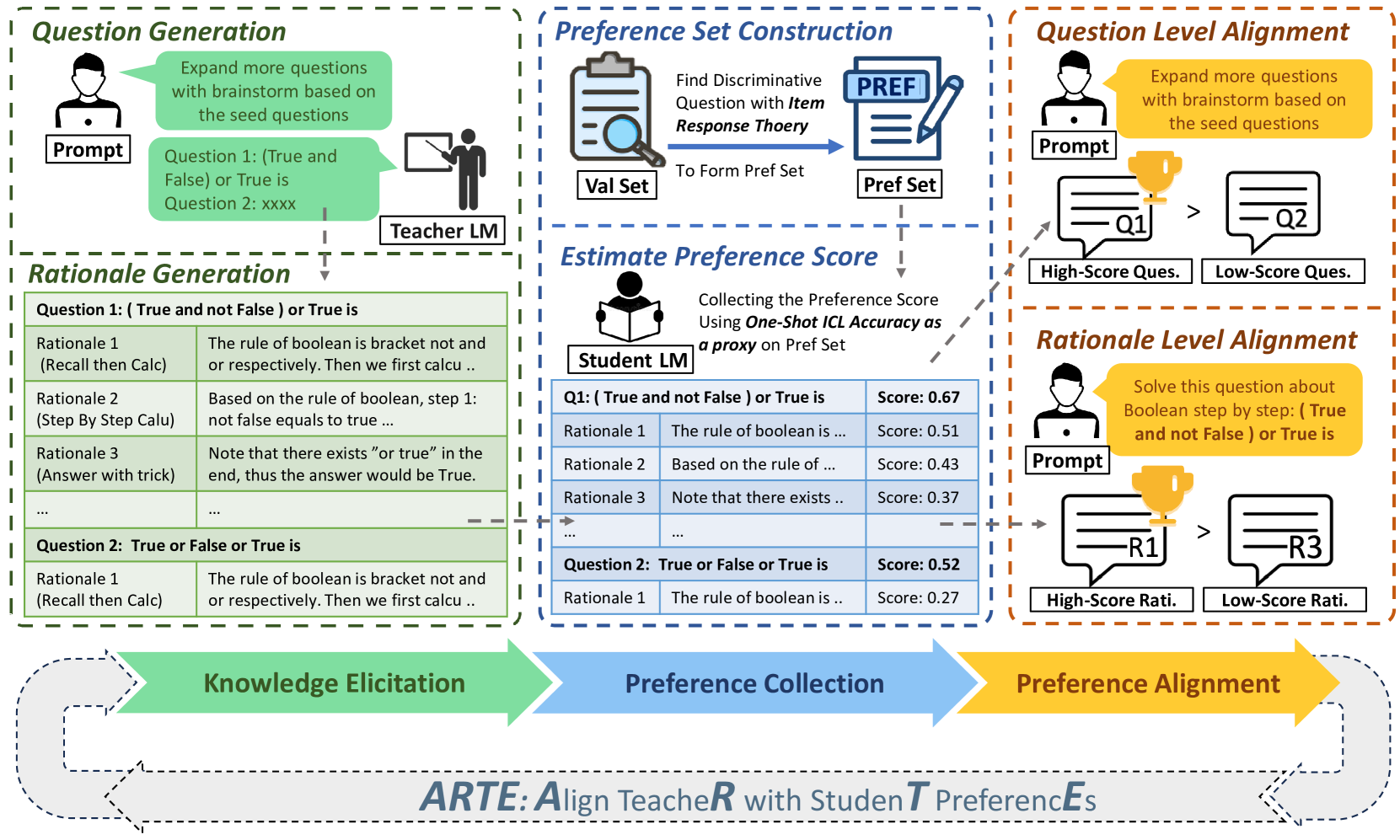
Large Language Models (LLMs) have shown significant promise as copilots in various tasks. Local deployment of LLMs on edge devices is necessary when handling privacy-sensitive data or latency-sensitive tasks. The computational constraints of such devices make direct deployment of powerful large-scale LLMs impractical, necessitating the Knowledge Distillation from large-scale models to lightweight models. Lots of work has been done to elicit diversity and quality training examples from LLMs, but little attention has been paid to aligning teacher instructional content based on student preferences, akin to responsive teaching in pedagogy. Thus, we propose ARTE, dubbed Aligning TeacheR with StudenT PreferencEs, a framework that aligns the teacher model with student preferences to generate tailored training examples for Knowledge Distillation. Specifically, we elicit draft questions and rationales from the teacher model, then collect student preferences on these questions and rationales using students' performance with in-context learning as a proxy, and finally align the teacher model with student preferences. In the end, we repeat the first step with the aligned teacher model to elicit tailored training examples for the student model on the target task. Extensive experiments on academic benchmarks demonstrate the superiority of ARTE over existing instruction-tuning datasets distilled from powerful LLMs. Moreover, we thoroughly investigate the generalization of ARTE, including the generalization of fine-tuned student models in reasoning ability and the generalization of aligned teacher models to generate tailored training data across tasks and students. In summary, our contributions lie in proposing a novel framework for tailored training example generation, demonstrating its efficacy in experiments, and investigating the generalization of both student & aligned teacher models in ARTE.
Create account to get full access
Overview
• This paper introduces a novel approach for aligning teacher and student preferences in the context of tailored training data generation.
• The proposed method aims to improve the effectiveness of knowledge distillation by ensuring that the training data generated by the teacher model matches the student's preferences and abilities.
• The authors draw inspiration from prior work on bidirectional alignment, teacher-student collaborative frameworks, and preference-based language model distillation.
Plain English Explanation
The paper explores a way to improve how a "teacher" artificial intelligence (AI) model generates training data for a "student" AI model. Typically, the teacher model creates training data based on its own preferences and abilities, which may not match what the student model needs to learn effectively.
The researchers propose a new method that aligns the teacher's data generation process with the student's preferences and skills. This ensures the training data is tailored to the student's specific requirements, leading to more efficient knowledge transfer from the teacher to the student.
The key insight is that by understanding the student's preferences and adjusting the teacher's data generation accordingly, the student can learn more effectively. This is similar to how a human teacher might curate and adjust the learning materials they provide to best suit the needs and abilities of their students.
The authors draw on related ideas, such as bidirectional alignment, where the teacher and student models work together to improve each other, and preference-based distillation, where the student's preferences guide the knowledge transfer process.
Technical Explanation
The paper introduces a framework called "Aligning Teacher with Student Preferences for Tailored Training Data Generation" (AT-PREF), which aims to improve the effectiveness of knowledge distillation by ensuring that the training data generated by the teacher model matches the student's preferences and abilities.
The key components of the AT-PREF framework are:
-
Student Preference Modeling: The researchers propose a method to explicitly model the student's preferences and abilities, which are then used to guide the training data generation process.
-
Preference-Aware Data Generation: The teacher model is trained to generate training data that not only aligns with the original task objective but also matches the student's learned preferences.
-
Preference-Guided Knowledge Distillation: The student model is trained using the tailored training data generated by the teacher, leading to more efficient knowledge transfer.
The authors draw inspiration from related work, such as bidirectional alignment, teacher-student collaborative frameworks, and preference-based language model distillation.
Through extensive experiments, the researchers demonstrate that the AT-PREF framework outperforms traditional knowledge distillation approaches in various tasks, highlighting the benefits of aligning the teacher's data generation process with the student's preferences and abilities.
Critical Analysis
The paper presents a compelling approach to improving knowledge distillation by considering the student's preferences and abilities. However, the authors acknowledge some potential limitations and areas for future research:
-
Scalability: The proposed framework may face challenges in scaling to larger and more complex models, as the preference modeling and alignment process could become computationally expensive.
-
Preference Interpretation: The researchers rely on the student's preferences being accurately captured and modeled, which could be challenging in practice, especially for more complex cognitive traits.
-
Generalization: The effectiveness of the AT-PREF framework may be task-dependent, and it remains to be seen how well it would generalize to a broader range of applications beyond the specific scenarios explored in the paper.
Additionally, one could question the broader implications of such an approach. While tailoring training data to student preferences can improve learning efficiency, it raises concerns about potential biases and the risk of reinforcing individual cognitive limitations rather than pushing students to expand their abilities.
Conclusion
The "Aligning Teacher with Student Preferences for Tailored Training Data Generation" paper presents a novel approach to improving knowledge distillation by aligning the teacher model's data generation process with the student's preferences and abilities. By explicitly modeling the student's preferences and using them to guide the teacher's data generation, the researchers demonstrate enhanced learning outcomes compared to traditional knowledge distillation methods.
This work builds on previous research on teacher-student collaboration and preference-based distillation, showcasing the potential benefits of considering the student's unique characteristics in the knowledge transfer process.
While the proposed framework shows promise, it also raises some critical questions about scalability, preference interpretation, and the broader implications of tailoring training data to individual cognitive traits. As the field of AI continues to advance, these are important considerations that will shape the future of education and training systems powered by machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Improving In-context Learning via Bidirectional Alignment
Chengwei Qin, Wenhan Xia, Fangkai Jiao, Chen Chen, Yuchen Hu, Bosheng Ding, Shafiq Joty
0
0
Large language models (LLMs) have shown impressive few-shot generalization on many tasks via in-context learning (ICL). Despite their success in showing such emergent abilities, the scale and complexity of larger models also lead to unprecedentedly high computational demands and deployment challenges. In reaction, researchers explore transferring the powerful capabilities of larger models to more efficient and compact models by typically aligning the output of smaller (student) models with that of larger (teacher) models. Existing methods either train student models on the generated outputs of teacher models or imitate their token-level probability distributions. However, these distillation methods pay little to no attention to the input, which also plays a crucial role in ICL. Based on the finding that the performance of ICL is highly sensitive to the selection of demonstration examples, we propose Bidirectional Alignment (BiAlign) to fully leverage the models' preferences for ICL examples to improve the ICL abilities of student models. Specifically, we introduce the alignment of input preferences between student and teacher models by incorporating a novel ranking loss, in addition to aligning the token-level output distribution. With extensive experiments and analysis, we demonstrate that BiAlign can consistently outperform existing baselines on a variety of tasks involving language understanding, reasoning, and coding.
6/26/2024

TS-Align: A Teacher-Student Collaborative Framework for Scalable Iterative Finetuning of Large Language Models
Chen Zhang, Chengguang Tang, Dading Chong, Ke Shi, Guohua Tang, Feng Jiang, Haizhou Li
0
0
Mainstream approaches to aligning large language models (LLMs) heavily rely on human preference data, particularly when models require periodic updates. The standard process for iterative alignment of LLMs involves collecting new human feedback for each update. However, the data collection process is costly and challenging to scale. To address this issue, we introduce the TS-Align framework, which fine-tunes a policy model using pairwise feedback data automatically mined from its outputs. This automatic mining process is efficiently accomplished through the collaboration between a large-scale teacher model and a small-scale student model. The policy fine-tuning process can be iteratively repeated using on-policy generations within our proposed teacher-student collaborative framework. Through extensive experiments, we demonstrate that our final aligned policy outperforms the base policy model with an average win rate of 69.7% across seven conversational or instruction-following datasets. Furthermore, we show that the ranking capability of the teacher is effectively distilled into the student through our pipeline, resulting in a small-scale yet effective reward model for policy model alignment.
6/17/2024
💬
Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning
Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang
0
0
The process of instruction tuning aligns pre-trained large language models (LLMs) with open-domain instructions and human-preferred responses. While several studies have explored autonomous approaches to distilling and annotating instructions from more powerful proprietary LLMs, such as ChatGPT, they often neglect the impact of task distributions and the varying difficulty of instructions of the training sets. This oversight can lead to imbalanced knowledge capabilities and poor generalization powers of small student LLMs. To address this challenge, we introduce Task-Aware Curriculum Planning for Instruction Refinement (TAPIR), a multi-round distillation framework with balanced task distributions and dynamic difficulty adjustment. This approach utilizes an oracle LLM to select instructions that are difficult for a student LLM to follow and distill instructions with balanced task distributions. By incorporating curriculum planning, our approach systematically escalates the difficulty levels, progressively enhancing the student LLM's capabilities. We rigorously evaluate TAPIR using two widely recognized benchmarks, including AlpacaEval 2.0 and MT-Bench. The empirical results demonstrate that the student LLMs, trained with our method and less training data, outperform larger instruction-tuned models and strong distillation baselines. The improvement is particularly notable in complex tasks, such as logical reasoning and code generation.
5/24/2024

PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
Rongzhi Zhang, Jiaming Shen, Tianqi Liu, Haorui Wang, Zhen Qin, Feng Han, Jialu Liu, Simon Baumgartner, Michael Bendersky, Chao Zhang
0
0
Large Language Models (LLMs) have exhibited impressive capabilities in various tasks, yet their vast parameter sizes restrict their applicability in resource-constrained settings. Knowledge distillation (KD) offers a viable solution by transferring expertise from large teacher models to compact student models. However, traditional KD techniques face specific challenges when applied to LLMs, including restricted access to LLM outputs, significant teacher-student capacity gaps, and the inherited mis-calibration issue. In this work, we present PLaD, a novel preference-based LLM distillation framework. PLaD exploits the teacher-student capacity discrepancy to generate pseudo-preference pairs where teacher outputs are preferred over student outputs. Then, PLaD leverages a ranking loss to re-calibrate student's estimation of sequence likelihood, which steers the student's focus towards understanding the relative quality of outputs instead of simply imitating the teacher. PLaD bypasses the need for access to teacher LLM's internal states, tackles the student's expressivity limitations, and mitigates the student mis-calibration issue. Through extensive experiments on two sequence generation tasks and with various LLMs, we demonstrate the effectiveness of our proposed PLaD framework.
6/7/2024