TS-Align: A Teacher-Student Collaborative Framework for Scalable Iterative Finetuning of Large Language Models
2405.20215
0
0

Abstract
Mainstream approaches to aligning large language models (LLMs) heavily rely on human preference data, particularly when models require periodic updates. The standard process for iterative alignment of LLMs involves collecting new human feedback for each update. However, the data collection process is costly and challenging to scale. To address this issue, we introduce the TS-Align framework, which fine-tunes a policy model using pairwise feedback data automatically mined from its outputs. This automatic mining process is efficiently accomplished through the collaboration between a large-scale teacher model and a small-scale student model. The policy fine-tuning process can be iteratively repeated using on-policy generations within our proposed teacher-student collaborative framework. Through extensive experiments, we demonstrate that our final aligned policy outperforms the base policy model with an average win rate of 69.7% across seven conversational or instruction-following datasets. Furthermore, we show that the ranking capability of the teacher is effectively distilled into the student through our pipeline, resulting in a small-scale yet effective reward model for policy model alignment.
Create account to get full access
Overview
- This paper proposes a framework called TS-Align to efficiently fine-tune large language models by leveraging a collaborative approach between a teacher model and a student model.
- The key idea is to use the teacher model to guide the fine-tuning of the student model, which is computationally less expensive, leading to faster and more scalable fine-tuning.
- The framework includes several novel components, such as a temperature-controlled distillation loss and an iterative fine-tuning process that alternates between the teacher and student models.
Plain English Explanation
The paper describes a new way to fine-tune large language models, which are AI systems trained on huge amounts of text data to understand and generate human-like language. Fine-tuning is the process of further training a model on a specific task or dataset to improve its performance.
Traditionally, fine-tuning large language models can be computationally expensive and time-consuming. The TS-Align framework proposes a solution to this problem by using a "teacher" model to guide the fine-tuning of a more efficient "student" model.
The key idea is that the teacher model, which is the original large language model, can provide valuable information to the student model during the fine-tuning process. This allows the student model to learn the task more quickly and with less computational resources, while still maintaining high performance.
The framework includes several novel techniques, such as a way to control the "temperature" of the distillation process (the transfer of knowledge from teacher to student) and an iterative fine-tuning process where the teacher and student models take turns being refined.
This approach can make fine-tuning large language models more scalable and efficient, which could have important implications for making advanced language AI systems more widely accessible and applicable.
Technical Explanation
The TS-Align framework consists of three key components:
-
Temperature-Controlled Distillation Loss: This loss function allows the student model to learn from the teacher model's output distributions, with a temperature parameter to control the "smoothness" of the distributions. This helps the student model to better capture the teacher's knowledge.
-
Iterative Fine-Tuning: The framework alternates between fine-tuning the teacher model and the student model. This allows the student model to learn from the teacher's evolving knowledge, while the teacher model also continues to improve.
-
Compute-Efficient Student Model: The student model is designed to be less computationally expensive than the original teacher model, enabling faster and more scalable fine-tuning.
The authors conduct extensive experiments on various language tasks, such as text classification and question answering. They demonstrate that the TS-Align framework can achieve comparable or better performance than directly fine-tuning the large language model, while significantly reducing the computational cost and time required.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear focus on addressing the challenge of efficiently fine-tuning large language models. The TS-Align framework offers a novel and promising approach to this problem.
One potential limitation is that the framework may be sensitive to the initial quality of the teacher model, as it relies on the teacher to guide the student's learning. If the teacher model is not sufficiently capable, the student model may struggle to learn effectively.
Additionally, the paper does not explore the long-term implications of the iterative fine-tuning process, such as how it might affect the model's robustness or adaptability over time.
Further research could investigate the applicability of the TS-Align framework to other types of large models beyond language models, as well as explore ways to make the teacher-student relationship more dynamic and adaptive during the fine-tuning process.
Conclusion
The TS-Align framework presented in this paper offers a promising approach to efficiently fine-tuning large language models, which is a crucial challenge in the field of natural language processing. By leveraging a teacher-student collaborative approach, the framework can achieve comparable performance to direct fine-tuning while significantly reducing the computational cost and time required.
This work has the potential to make advanced language AI systems more accessible and widely applicable, as the improved efficiency of the fine-tuning process could enable the deployment of these systems in a wider range of real-world scenarios. The novel techniques introduced in this paper, such as the temperature-controlled distillation loss and the iterative fine-tuning process, could also inspire further research and innovation in the field of large model fine-tuning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Aligning Large Language Models via Fine-grained Supervision
Dehong Xu, Liang Qiu, Minseok Kim, Faisal Ladhak, Jaeyoung Do
0
0
Pre-trained large-scale language models (LLMs) excel at producing coherent articles, yet their outputs may be untruthful, toxic, or fail to align with user expectations. Current approaches focus on using reinforcement learning with human feedback (RLHF) to improve model alignment, which works by transforming coarse human preferences of LLM outputs into a feedback signal that guides the model learning process. However, because this approach operates on sequence-level feedback, it lacks the precision to identify the exact parts of the output affecting user preferences. To address this gap, we propose a method to enhance LLM alignment through fine-grained token-level supervision. Specifically, we ask annotators to minimally edit less preferred responses within the standard reward modeling dataset to make them more favorable, ensuring changes are made only where necessary while retaining most of the original content. The refined dataset is used to train a token-level reward model, which is then used for training our fine-grained Proximal Policy Optimization (PPO) model. Our experiment results demonstrate that this approach can achieve up to an absolute improvement of $5.1%$ in LLM performance, in terms of win rate against the reference model, compared with the traditional PPO model.
6/6/2024
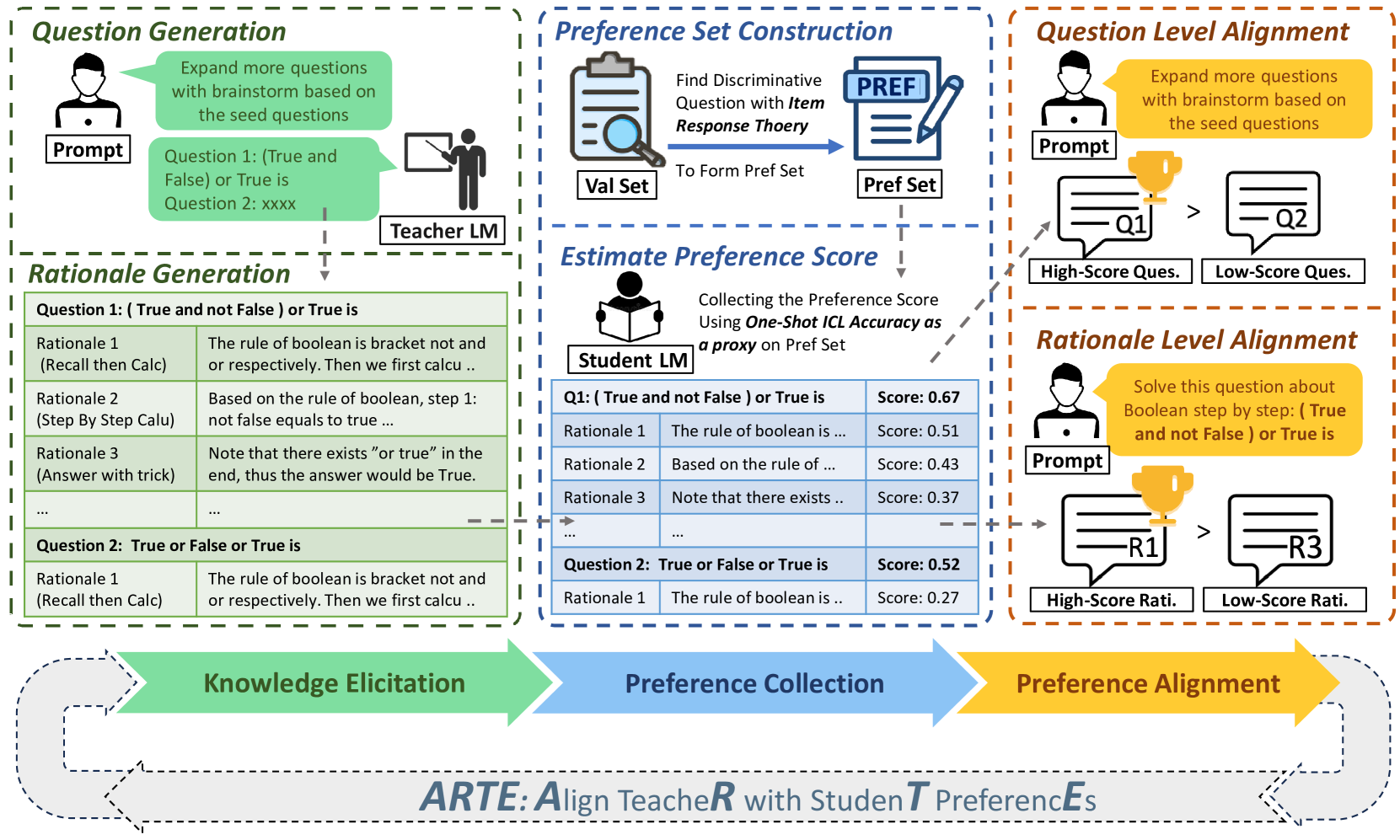
Aligning Teacher with Student Preferences for Tailored Training Data Generation
Yantao Liu, Zhao Zhang, Zijun Yao, Shulin Cao, Lei Hou, Juanzi Li
0
0
Large Language Models (LLMs) have shown significant promise as copilots in various tasks. Local deployment of LLMs on edge devices is necessary when handling privacy-sensitive data or latency-sensitive tasks. The computational constraints of such devices make direct deployment of powerful large-scale LLMs impractical, necessitating the Knowledge Distillation from large-scale models to lightweight models. Lots of work has been done to elicit diversity and quality training examples from LLMs, but little attention has been paid to aligning teacher instructional content based on student preferences, akin to responsive teaching in pedagogy. Thus, we propose ARTE, dubbed Aligning TeacheR with StudenT PreferencEs, a framework that aligns the teacher model with student preferences to generate tailored training examples for Knowledge Distillation. Specifically, we elicit draft questions and rationales from the teacher model, then collect student preferences on these questions and rationales using students' performance with in-context learning as a proxy, and finally align the teacher model with student preferences. In the end, we repeat the first step with the aligned teacher model to elicit tailored training examples for the student model on the target task. Extensive experiments on academic benchmarks demonstrate the superiority of ARTE over existing instruction-tuning datasets distilled from powerful LLMs. Moreover, we thoroughly investigate the generalization of ARTE, including the generalization of fine-tuned student models in reasoning ability and the generalization of aligned teacher models to generate tailored training data across tasks and students. In summary, our contributions lie in proposing a novel framework for tailored training example generation, demonstrating its efficacy in experiments, and investigating the generalization of both student & aligned teacher models in ARTE.
6/28/2024
🖼️
Aligners: Decoupling LLMs and Alignment
Lilian Ngweta, Mayank Agarwal, Subha Maity, Alex Gittens, Yuekai Sun, Mikhail Yurochkin
0
0
Large Language Models (LLMs) need to be aligned with human expectations to ensure their safety and utility in most applications. Alignment is challenging, costly, and needs to be repeated for every LLM and alignment criterion. We propose to decouple LLMs and alignment by training aligner models that can be used to align any LLM for a given criteria on an as-needed basis, thus also reducing the potential negative impacts of alignment on performance. Our recipe for training the aligner models solely relies on synthetic data generated with a (prompted) LLM and can be easily adjusted for a variety of alignment criteria. We use the same synthetic data to train inspectors, binary miss-alignment classification models to guide a squad of multiple aligners. Our empirical results demonstrate consistent improvements when applying aligner squad to various LLMs, including chat-aligned models, across several instruction-following and red-teaming datasets.
6/18/2024
⚙️
Aligner: Efficient Alignment by Learning to Correct
Jiaming Ji, Boyuan Chen, Hantao Lou, Donghai Hong, Borong Zhang, Xuehai Pan, Juntao Dai, Tianyi Qiu, Yaodong Yang
0
0
With the rapid development of large language models (LLMs) and ever-evolving practical requirements, finding an efficient and effective alignment method has never been more critical. However, the tension between the complexity of current alignment methods and the need for rapid iteration in deployment scenarios necessitates the development of a model-agnostic alignment approach that can operate under these constraints. In this paper, we introduce Aligner, a novel and simple alignment paradigm that learns the correctional residuals between preferred and dispreferred answers using a small model. Designed as a model-agnostic, plug-and-play module, Aligner can be directly applied to various open-source and API-based models with only one-off training, making it suitable for rapid iteration. Notably, Aligner can be applied to any powerful, large-scale upstream models. Moreover, it can even iteratively bootstrap the upstream models using corrected responses as synthetic human preference data, breaking through the model's performance ceiling. Our experiments demonstrate performance improvements by deploying the same Aligner model across 11 different LLMs, evaluated on the 3H dimensions (helpfulness, harmlessness, and honesty). Specifically, Aligner-7B has achieved an average improvement of 68.9% in helpfulness and 23.8% in harmlessness across the tested LLMs while also effectively reducing hallucination. In the Alpaca-Eval leaderboard, stacking Aligner-2B on GPT-4 Turbo improved its LC Win Rate from 55.0% to 58.3%, surpassing GPT-4 Omni's 57.5% Win Rate (community report).
6/4/2024