ALLaVA: Harnessing GPT4V-Synthesized Data for Lite Vision-Language Models
2402.11684
0
0
📊
Abstract
Large vision-language models (LVLMs) have shown premise in a broad range of vision-language tasks with their strong reasoning and generalization capabilities. However, they require considerable computational resources for training and deployment. This study aims to bridge the performance gap between traditional-scale LVLMs and resource-friendly lite versions by adopting high-quality training data. To this end, we propose a comprehensive pipeline for generating a synthetic dataset. The key idea is to leverage strong proprietary models to generate (i) fine-grained image annotations for vision-language alignment and (ii) complex reasoning visual question-answering pairs for visual instruction fine-tuning, yielding 1.3M samples in total. We train a series of lite VLMs on the synthetic dataset and experimental results demonstrate the effectiveness of the proposed scheme, where they achieve competitive performance on 17 benchmarks among 4B LVLMs, and even perform on par with 7B/13B-scale models on various benchmarks. This work highlights the feasibility of adopting high-quality data in crafting more efficient LVLMs. We name our dataset textit{ALLaVA}, and open-source it to research community for developing better resource-efficient LVLMs for wider usage.
Create account to get full access
Overview
- Large vision-language models (LVLMs) have shown impressive performance on a wide range of vision-language tasks, but they require significant computational resources to train and deploy.
- This study aims to bridge the performance gap between traditional-scale LVLMs and more resource-friendly "lite" versions by leveraging high-quality training data.
- The researchers propose a comprehensive pipeline for generating a synthetic dataset, using strong proprietary models to create fine-grained image annotations and complex reasoning visual question-answering pairs.
- The resulting dataset, called ALLaVA, is used to train a series of lite VLMs, which achieve competitive performance on 17 benchmarks compared to much larger 4B LVLMs, and even on par with 7B/13B-scale models on various tasks.
Plain English Explanation
Large vision-language models (LVLMs) are powerful AI systems that can handle a broad range of tasks involving both images and text. They have demonstrated impressive capabilities, but training and running these models requires a lot of computing power, which can be a barrier to their wider adoption.
To make these models more accessible, the researchers in this study wanted to find a way to create "lite" versions that perform almost as well as the larger LVLMs, but with much less computational resources. The key insight was to use high-quality synthetic data to train the lite models.
The researchers developed a process to generate a large dataset of annotated images and visual question-answering pairs. They leveraged powerful AI models to automatically create these training samples, rather than relying on human labelers. This allowed them to build a very extensive and high-quality dataset called ALLaVA.
When the researchers trained their lite VLMs on this synthetic dataset, the models were able to achieve performance on par with much larger LVLMs on a wide range of benchmarks. This shows that the quality of the training data can be just as important as the model size, and that it's possible to create efficient, resource-friendly vision-language models by harnessing the power of synthetic data generation.
Technical Explanation
The researchers propose a comprehensive pipeline for generating a large-scale synthetic dataset, called ALLaVA, to train efficient lite versions of vision-language models (VLMs). The key components of their approach are:
-
Fine-grained image annotations: The researchers leverage strong proprietary models to automatically annotate images with detailed, high-quality labels for vision-language alignment tasks.
-
Complex reasoning visual question-answering pairs: The same powerful models are used to generate challenging visual question-answering examples that require complex reasoning, for fine-tuning the VLMs.
-
Efficient VLM training: The researchers train a series of lite VLMs on the synthetic ALLaVA dataset and evaluate their performance on 17 benchmarks. Remarkably, these lite models achieve competitive results compared to much larger 4B LVLMs, and even match the performance of 7B/13B-scale models on various tasks.
This work demonstrates the feasibility of using high-quality synthetic data to craft more resource-efficient LVLMs, as an alternative to scaling up model size and capacity. By harnessing the power of advanced data generation techniques, the researchers were able to bridge the performance gap between traditional-scale LVLMs and their lite counterparts.
Critical Analysis
The researchers acknowledge some limitations of their approach. For example, the synthetic data may not capture all the nuances and diversity of real-world vision-language examples. There is also a question of how well the models trained on synthetic data would generalize to real-world applications.
Additionally, the study relies on proprietary models to generate the synthetic dataset, which may limit the reproducibility and accessibility of the research. It would be interesting to see if similar results can be achieved using open-source models or a more transparent data generation process.
Furthermore, the paper does not provide a detailed analysis of the types of errors or biases that may be introduced by the synthetic data. A more in-depth investigation of these issues could help identify potential pitfalls and guide future research in this direction.
Despite these caveats, the study presents a promising approach to building efficient vision-language models by leveraging high-quality synthetic data. As the field of vision-language modeling continues to evolve, this work highlights the importance of data quality and the potential benefits of synthetic data generation techniques.
Conclusion
This study demonstrates a novel approach to bridging the performance gap between large-scale vision-language models (LVLMs) and their more resource-friendly "lite" counterparts. By leveraging a comprehensive pipeline for generating a high-quality synthetic dataset, the researchers were able to train lite VLMs that achieved competitive results on a wide range of benchmarks, sometimes even matching the performance of much larger models.
The success of this approach highlights the crucial role of training data quality in developing efficient and effective vision-language models. It also underscores the potential of synthetic data generation techniques to unlock new possibilities in the field of multimodal AI, where computational resources are often a limiting factor.
As the demand for accessible and deployable vision-language models continues to grow, this work provides a promising direction for the research community to explore, paving the way for more resource-efficient, yet high-performing, large-scale AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Harnessing the Power of Large Vision Language Models for Synthetic Image Detection
Mamadou Keita, Wassim Hamidouche, Hassen Bougueffa, Abdenour Hadid, Abdelmalik Taleb-Ahmed
0
0
In recent years, the emergence of models capable of generating images from text has attracted considerable interest, offering the possibility of creating realistic images from text descriptions. Yet these advances have also raised concerns about the potential misuse of these images, including the creation of misleading content such as fake news and propaganda. This study investigates the effectiveness of using advanced vision-language models (VLMs) for synthetic image identification. Specifically, the focus is on tuning state-of-the-art image captioning models for synthetic image detection. By harnessing the robust understanding capabilities of large VLMs, the aim is to distinguish authentic images from synthetic images produced by diffusion-based models. This study contributes to the advancement of synthetic image detection by exploiting the capabilities of visual language models such as BLIP-2 and ViTGPT2. By tailoring image captioning models, we address the challenges associated with the potential misuse of synthetic images in real-world applications. Results described in this paper highlight the promising role of VLMs in the field of synthetic image detection, outperforming conventional image-based detection techniques. Code and models can be found at https://github.com/Mamadou-Keita/VLM-DETECT.
4/4/2024
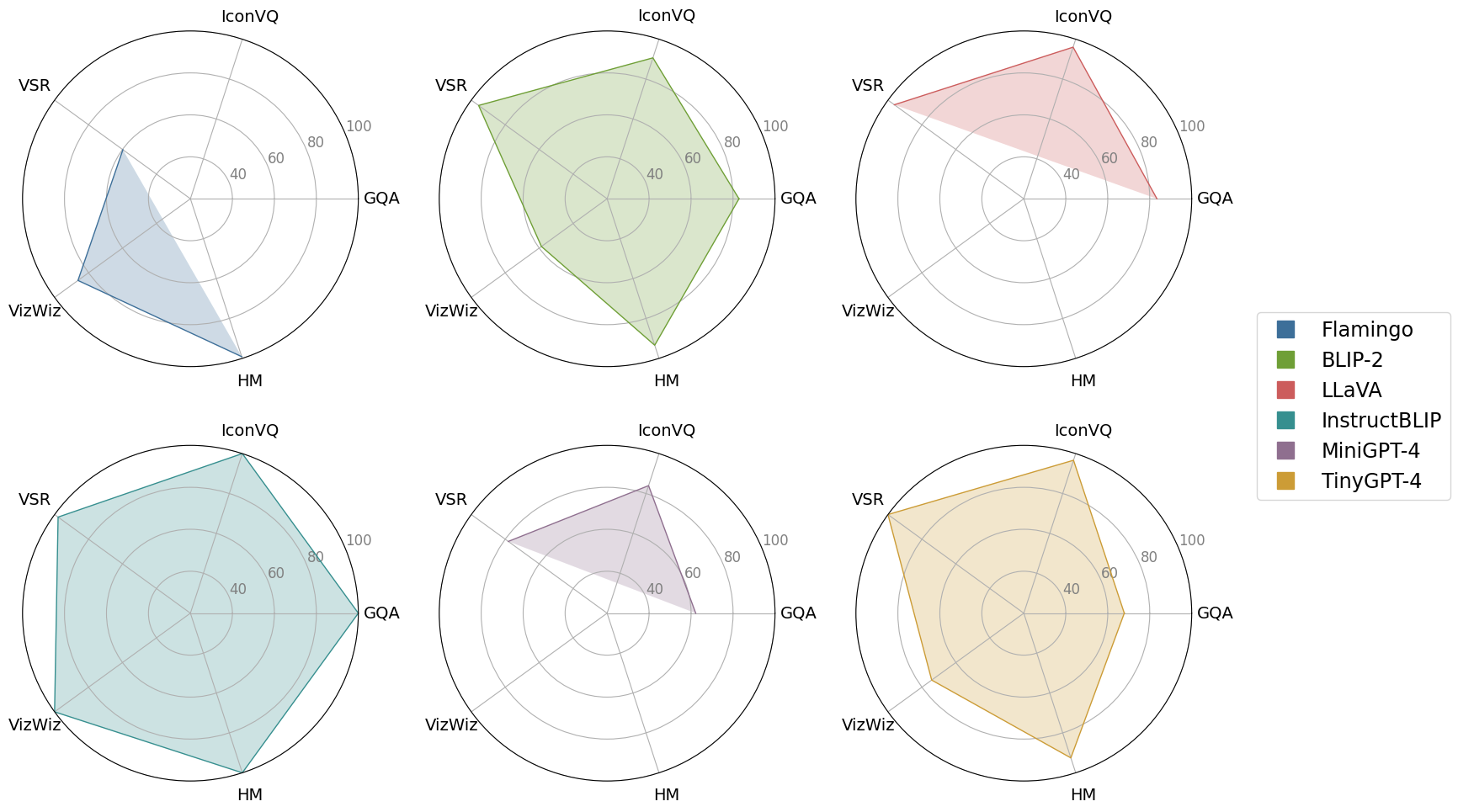
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
Zhengqing Yuan, Zhaoxu Li, Weiran Huang, Yanfang Ye, Lichao Sun
0
0
In recent years, multimodal large language models (MLLMs) such as GPT-4V have demonstrated remarkable advancements, excelling in a variety of vision-language tasks. Despite their prowess, the closed-source nature and computational demands of such models limit their accessibility and applicability. This study introduces TinyGPT-V, a novel open-source MLLM, designed for efficient training and inference across various vision-language tasks, including image captioning (IC) and visual question answering (VQA). Leveraging a compact yet powerful architecture, TinyGPT-V integrates the Phi-2 language model with pre-trained vision encoders, utilizing a unique mapping module for visual and linguistic information fusion. With a training regimen optimized for small backbones and employing a diverse dataset amalgam, TinyGPT-V requires significantly lower computational resources 24GB for training and as little as 8GB for inference without compromising on performance. Our experiments demonstrate that TinyGPT-V, with its language model 2.8 billion parameters, achieves comparable results in VQA and image inference tasks to its larger counterparts while being uniquely suited for deployment on resource-constrained devices through innovative quantization techniques. This work not only paves the way for more accessible and efficient MLLMs but also underscores the potential of smaller, optimized models in bridging the gap between high performance and computational efficiency in real-world applications. Additionally, this paper introduces a new approach to multimodal large language models using smaller backbones. Our code and training weights are available in the supplementary material.
6/24/2024
👀
Constructing Multilingual Visual-Text Datasets Revealing Visual Multilingual Ability of Vision Language Models
Jesse Atuhurra, Iqra Ali, Tatsuya Hiraoka, Hidetaka Kamigaito, Tomoya Iwakura, Taro Watanabe
0
0
Large language models (LLMs) have increased interest in vision language models (VLMs), which process image-text pairs as input. Studies investigating the visual understanding ability of VLMs have been proposed, but such studies are still preliminary because existing datasets do not permit a comprehensive evaluation of the fine-grained visual linguistic abilities of VLMs across multiple languages. To further explore the strengths of VLMs, such as GPT-4V cite{openai2023GPT4}, we developed new datasets for the systematic and qualitative analysis of VLMs. Our contribution is four-fold: 1) we introduced nine vision-and-language (VL) tasks (including object recognition, image-text matching, and more) and constructed multilingual visual-text datasets in four languages: English, Japanese, Swahili, and Urdu through utilizing templates containing textit{questions} and prompting GPT4-V to generate the textit{answers} and the textit{rationales}, 2) introduced a new VL task named textit{unrelatedness}, 3) introduced rationales to enable human understanding of the VLM reasoning process, and 4) employed human evaluation to measure the suitability of proposed datasets for VL tasks. We show that VLMs can be fine-tuned on our datasets. Our work is the first to conduct such analyses in Swahili and Urdu. Also, it introduces textit{rationales} in VL analysis, which played a vital role in the evaluation.
6/26/2024
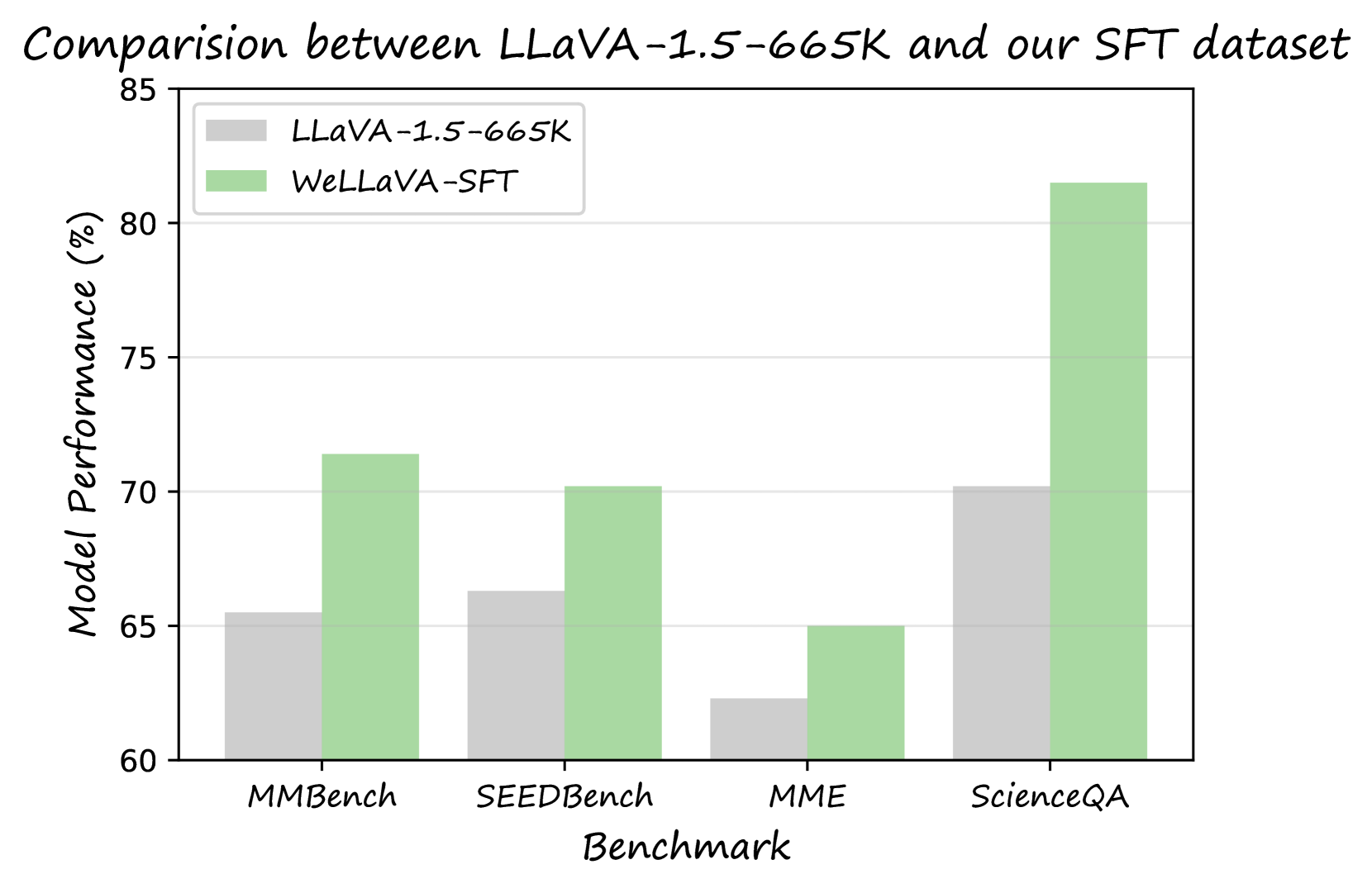
Rethinking Overlooked Aspects in Vision-Language Models
Yuan Liu, Le Tian, Xiao Zhou, Jie Zhou
0
0
Recent advancements in large vision-language models (LVLMs), such as GPT4-V and LLaVA, have been substantial. LLaVA's modular architecture, in particular, offers a blend of simplicity and efficiency. Recent works mainly focus on introducing more pre-training and instruction tuning data to improve model's performance. This paper delves into the often-neglected aspects of data efficiency during pre-training and the selection process for instruction tuning datasets. Our research indicates that merely increasing the size of pre-training data does not guarantee improved performance and may, in fact, lead to its degradation. Furthermore, we have established a pipeline to pinpoint the most efficient instruction tuning (SFT) dataset, implying that not all SFT data utilized in existing studies are necessary. The primary objective of this paper is not to introduce a state-of-the-art model, but rather to serve as a roadmap for future research, aiming to optimize data usage during pre-training and fine-tuning processes to enhance the performance of vision-language models.
5/21/2024