TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
2312.16862
0
0
Abstract
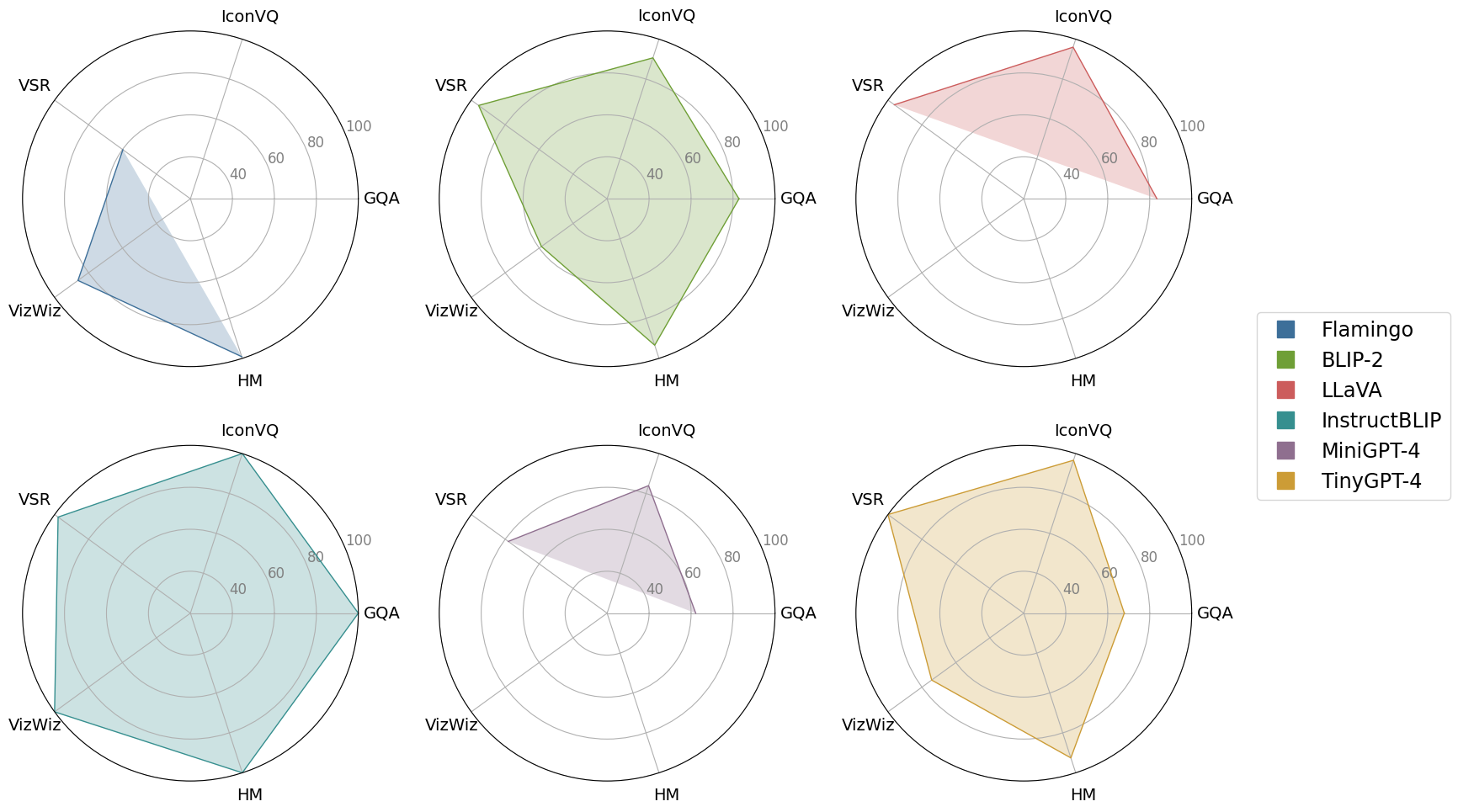
In recent years, multimodal large language models (MLLMs) such as GPT-4V have demonstrated remarkable advancements, excelling in a variety of vision-language tasks. Despite their prowess, the closed-source nature and computational demands of such models limit their accessibility and applicability. This study introduces TinyGPT-V, a novel open-source MLLM, designed for efficient training and inference across various vision-language tasks, including image captioning (IC) and visual question answering (VQA). Leveraging a compact yet powerful architecture, TinyGPT-V integrates the Phi-2 language model with pre-trained vision encoders, utilizing a unique mapping module for visual and linguistic information fusion. With a training regimen optimized for small backbones and employing a diverse dataset amalgam, TinyGPT-V requires significantly lower computational resources 24GB for training and as little as 8GB for inference without compromising on performance. Our experiments demonstrate that TinyGPT-V, with its language model 2.8 billion parameters, achieves comparable results in VQA and image inference tasks to its larger counterparts while being uniquely suited for deployment on resource-constrained devices through innovative quantization techniques. This work not only paves the way for more accessible and efficient MLLMs but also underscores the potential of smaller, optimized models in bridging the gap between high performance and computational efficiency in real-world applications. Additionally, this paper introduces a new approach to multimodal large language models using smaller backbones. Our code and training weights are available in url{https://github.com/DLYuanGod/TinyGPT-V}.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Presents TinyGPT-V, an efficient multimodal large language model with small backbones
- Demonstrates strong performance on various vision-language tasks while being more compact and efficient than previous models
- Introduces a novel training strategy and architecture design to achieve these improvements
Plain English Explanation
TinyGPT-V is a new type of large language model that can handle both text and images. Unlike most large language models that require a lot of computing power, TinyGPT-V is designed to be more efficient and compact.
The key innovations in TinyGPT-V are a novel training strategy and architectural design that allow it to achieve strong performance on a variety of vision-language tasks, such as image captioning and visual question answering, while being much smaller and more efficient than previous models. This makes TinyGPT-V more practical to deploy and use, especially on devices with limited computing resources.
The researchers behind TinyGPT-V wanted to show that it's possible to build powerful multimodal language models without needing massive amounts of computing power. This could open up new applications and make advanced AI technologies more accessible.
Technical Explanation
The researchers introduce a new model called TinyGPT-V that is designed to be more efficient and compact than previous multimodal large language models, while still maintaining strong performance.
The key innovations in TinyGPT-V include:
-
Novel Training Strategy: The researchers used a two-stage training process, first pretraining on text-only data to learn general language understanding, and then finetuning on multimodal (text+image) data. This allows the model to leverage large amounts of text-only data to build a strong language foundation, before specializing in the multimodal task.
-
Compact Architecture Design: TinyGPT-V uses a small "backbone" network for both the text and vision encoders, unlike previous models that used larger, more complex backbones. This reduces the overall model size and computational requirements.
-
Parameter Sharing: The text and vision encoders in TinyGPT-V share many of the same parameters, further reducing the model size. This is enabled by the two-stage training process, which allows the shared parameters to specialize for both modalities.
The researchers evaluate TinyGPT-V on a range of vision-language tasks, including image captioning, visual question answering, and zero-shot classification. They show that TinyGPT-V achieves strong performance on these tasks, often matching or exceeding the results of larger, more complex multimodal models, while being significantly more compact and efficient.
Critical Analysis
The researchers acknowledge that TinyGPT-V, while more efficient than previous models, still requires significant computing resources to train and deploy. They suggest that further research is needed to explore even more compact and efficient multimodal language models, potentially by incorporating techniques like model distillation or neural architecture search.
Additionally, the researchers only evaluate TinyGPT-V on a limited set of vision-language tasks. It would be valuable to see how the model performs on a wider range of multimodal benchmarks, including more open-ended tasks that require deeper language understanding and reasoning.
Finally, while the researchers highlight the potential benefits of TinyGPT-V in terms of deployability and accessibility, they do not discuss any potential societal or ethical implications of such efficient multimodal models. As these technologies become more advanced and widely used, it will be important to consider issues like bias, privacy, and the impact on various communities.
Conclusion
The TinyGPT-V model presented in this paper represents an important step towards more efficient and accessible multimodal large language models. By introducing novel training strategies and architectural designs, the researchers have shown that it is possible to build powerful vision-language models that are significantly more compact and computationally efficient than previous approaches.
This work could have important implications for the deployment of advanced AI technologies, particularly in resource-constrained environments or on edge devices. However, further research is needed to explore even more efficient models and to consider the broader societal implications of such efficient multimodal language models.
Overall, the TinyGPT-V paper demonstrates the potential for continued innovation in the field of multimodal AI, and highlights the importance of developing models that balance performance, efficiency, and accessibility.
Related Papers
MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
Kirolos Ataallah, Xiaoqian Shen, Eslam Abdelrahman, Essam Sleiman, Deyao Zhu, Jian Ding, Mohamed Elhoseiny
0
0
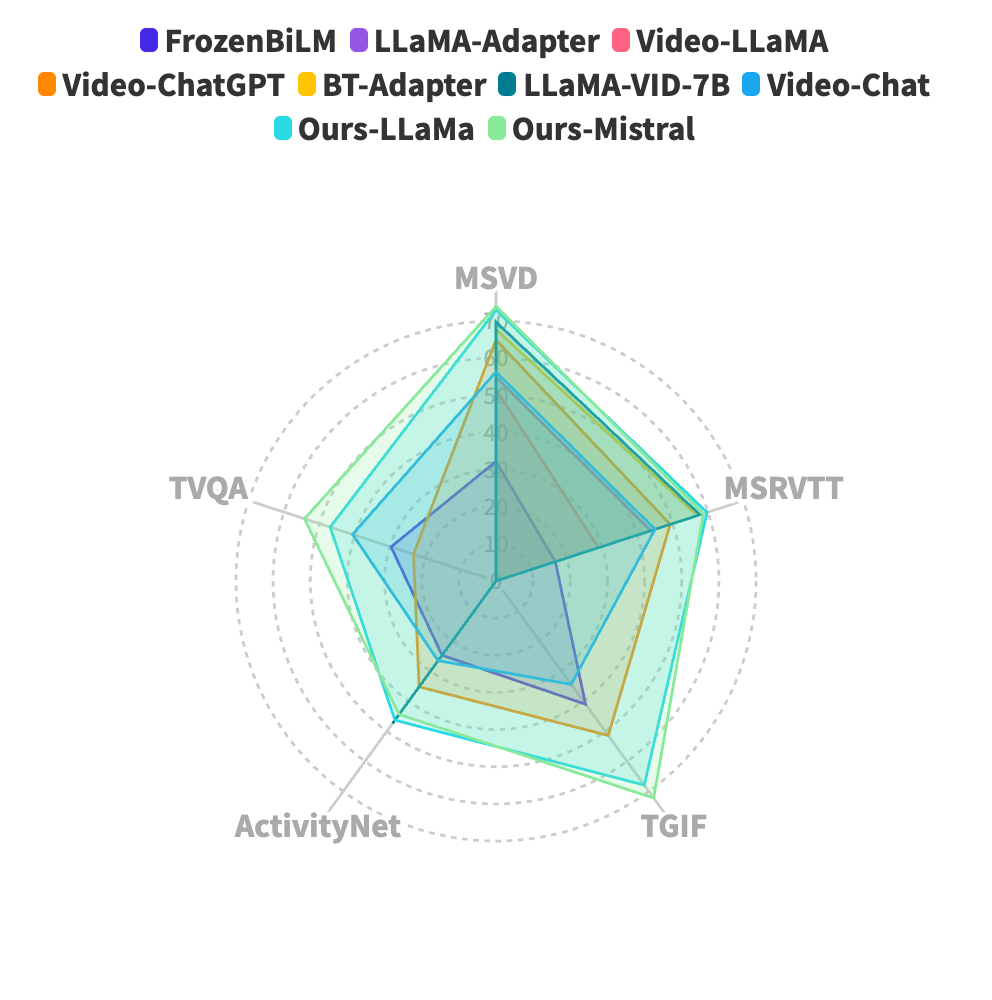
This paper introduces MiniGPT4-Video, a multimodal Large Language Model (LLM) designed specifically for video understanding. The model is capable of processing both temporal visual and textual data, making it adept at understanding the complexities of videos. Building upon the success of MiniGPT-v2, which excelled in translating visual features into the LLM space for single images and achieved impressive results on various image-text benchmarks, this paper extends the model's capabilities to process a sequence of frames, enabling it to comprehend videos. MiniGPT4-video does not only consider visual content but also incorporates textual conversations, allowing the model to effectively answer queries involving both visual and text components. The proposed model outperforms existing state-of-the-art methods, registering gains of 4.22%, 1.13%, 20.82%, and 13.1% on the MSVD, MSRVTT, TGIF, and TVQA benchmarks respectively. Our models and code have been made publicly available here https://vision-cair.github.io/MiniGPT4-video/
4/5/2024
TinyVQA: Compact Multimodal Deep Neural Network for Visual Question Answering on Resource-Constrained Devices
Hasib-Al Rashid, Argho Sarkar, Aryya Gangopadhyay, Maryam Rahnemoonfar, Tinoosh Mohsenin
0
0
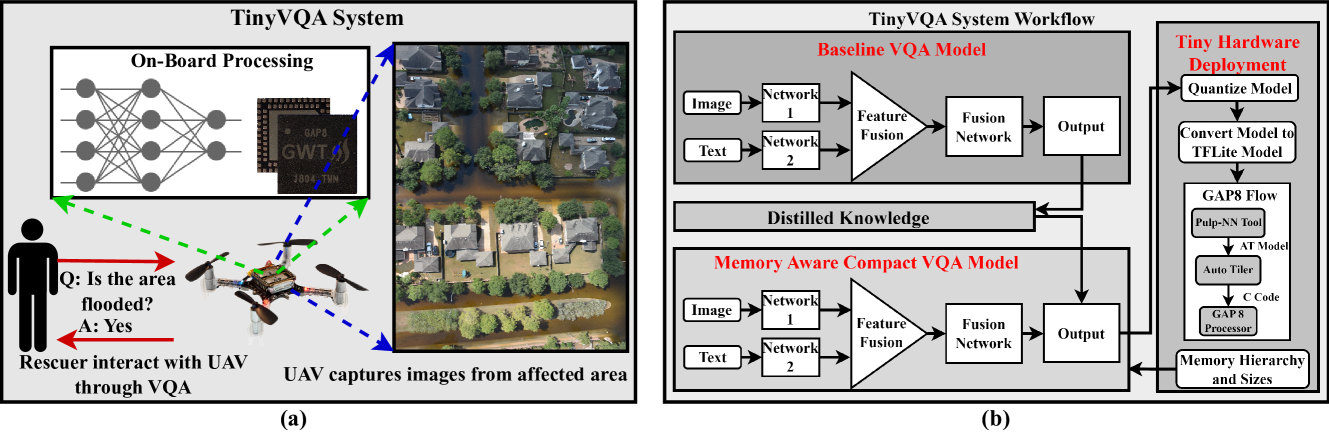
Traditional machine learning models often require powerful hardware, making them unsuitable for deployment on resource-limited devices. Tiny Machine Learning (tinyML) has emerged as a promising approach for running machine learning models on these devices, but integrating multiple data modalities into tinyML models still remains a challenge due to increased complexity, latency, and power consumption. This paper proposes TinyVQA, a novel multimodal deep neural network for visual question answering tasks that can be deployed on resource-constrained tinyML hardware. TinyVQA leverages a supervised attention-based model to learn how to answer questions about images using both vision and language modalities. Distilled knowledge from the supervised attention-based VQA model trains the memory aware compact TinyVQA model and low bit-width quantization technique is employed to further compress the model for deployment on tinyML devices. The TinyVQA model was evaluated on the FloodNet dataset, which is used for post-disaster damage assessment. The compact model achieved an accuracy of 79.5%, demonstrating the effectiveness of TinyVQA for real-world applications. Additionally, the model was deployed on a Crazyflie 2.0 drone, equipped with an AI deck and GAP8 microprocessor. The TinyVQA model achieved low latencies of 56 ms and consumes 693 mW power while deployed on the tiny drone, showcasing its suitability for resource-constrained embedded systems.
4/5/2024
💬
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, Ji Ma, Jiaqi Wang, Xiaoyi Dong, Hang Yan, Hewei Guo, Conghui He, Botian Shi, Zhenjiang Jin, Chao Xu, Bin Wang, Xingjian Wei, Wei Li, Wenjian Zhang, Bo Zhang, Pinlong Cai, Licheng Wen, Xiangchao Yan, Min Dou, Lewei Lu, Xizhou Zhu, Tong Lu, Dahua Lin, Yu Qiao, Jifeng Dai, Wenhai Wang
0
0
In this report, we introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple improvements: (1) Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model -- InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs. (2) Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448$times$448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input. (3) High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks. We evaluate InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 shows competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks. Code has been released at https://github.com/OpenGVLab/InternVL.
5/1/2024
PeFoMed: Parameter Efficient Fine-tuning of Multimodal Large Language Models for Medical Imaging
Gang Liu, Jinlong He, Pengfei Li, Genrong He, Zhaolin Chen, Shenjun Zhong
0
0
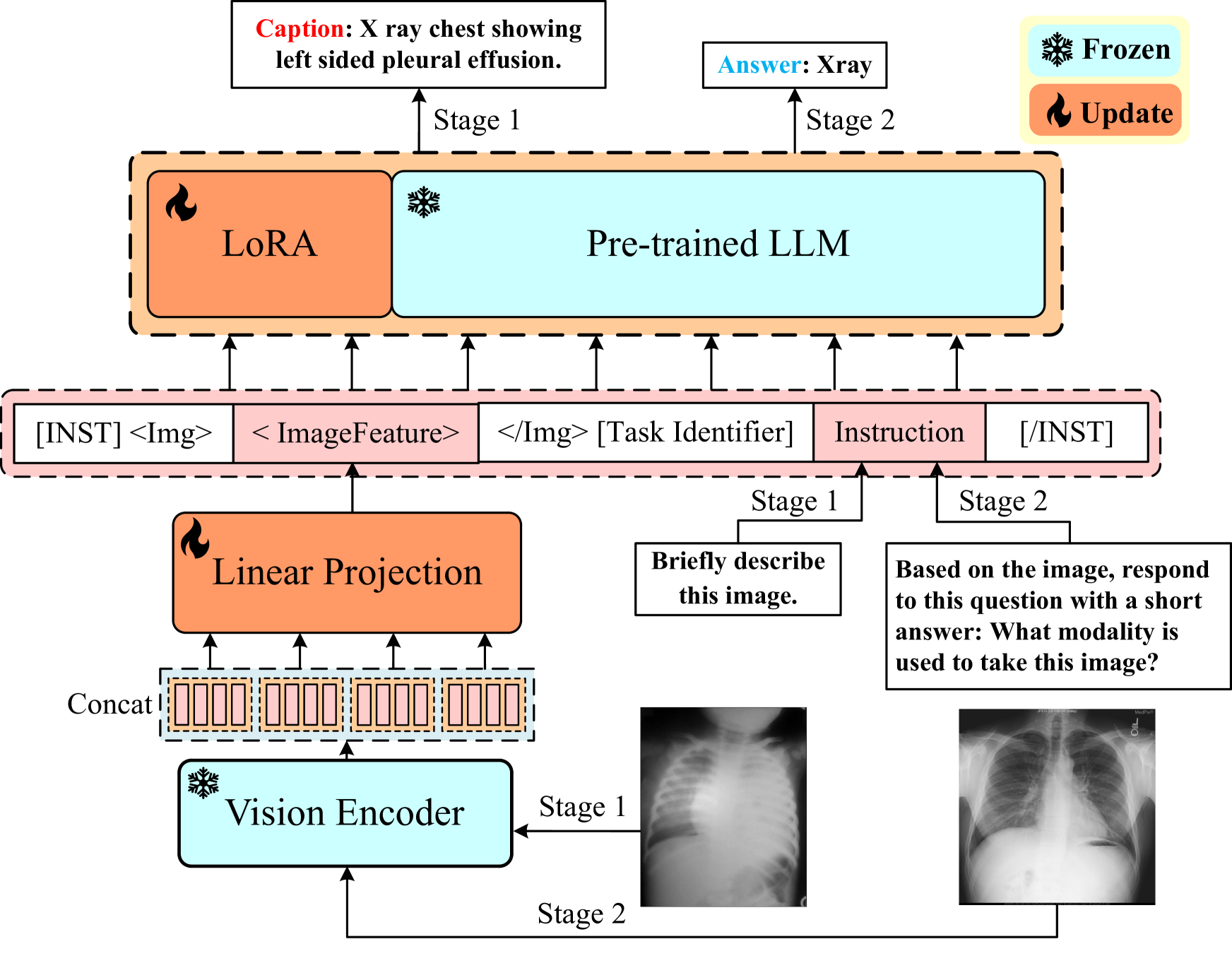
Multimodal large language models (MLLMs) represent an evolutionary expansion in the capabilities of traditional large language models, enabling them to tackle challenges that surpass the scope of purely text-based applications. It leverages the knowledge previously encoded within these language models, thereby enhancing their applicability and functionality in the reign of multimodal contexts. Recent works investigate the adaptation of MLLMs as a universal solution to address medical multi-modal problems as a generative task. In this paper, we propose a parameter efficient framework for fine-tuning MLLMs, specifically validated on medical visual question answering (Med-VQA) and medical report generation (MRG) tasks, using public benchmark datasets. We also introduce an evaluation metric using the 5-point Likert scale and its weighted average value to measure the quality of the generated reports for MRG tasks, where the scale ratings are labelled by both humans manually and the GPT-4 model. We further assess the consistency of performance metrics across traditional measures, GPT-4, and human ratings for both VQA and MRG tasks. The results indicate that semantic similarity assessments using GPT-4 align closely with human annotators and provide greater stability, yet they reveal a discrepancy when compared to conventional lexical similarity measurements. This questions the reliability of lexical similarity metrics for evaluating the performance of generative models in Med-VQA and report generation tasks. Besides, our fine-tuned model significantly outperforms GPT-4v. This indicates that without additional fine-tuning, multi-modal models like GPT-4v do not perform effectively on medical imaging tasks. The code will be available here: https://github.com/jinlHe/PeFoMed.
4/17/2024