LayerMatch: Do Pseudo-labels Benefit All Layers?
2406.14207
0
0

Abstract
Deep neural networks have achieved remarkable performance across various tasks when supplied with large-scale labeled data. However, the collection of labeled data can be time-consuming and labor-intensive. Semi-supervised learning (SSL), particularly through pseudo-labeling algorithms that iteratively assign pseudo-labels for self-training, offers a promising solution to mitigate the dependency of labeled data. Previous research generally applies a uniform pseudo-labeling strategy across all model layers, assuming that pseudo-labels exert uniform influence throughout. Contrasting this, our theoretical analysis and empirical experiment demonstrate feature extraction layer and linear classification layer have distinct learning behaviors in response to pseudo-labels. Based on these insights, we develop two layer-specific pseudo-label strategies, termed Grad-ReLU and Avg-Clustering. Grad-ReLU mitigates the impact of noisy pseudo-labels by removing the gradient detrimental effects of pseudo-labels in the linear classification layer. Avg-Clustering accelerates the convergence of feature extraction layer towards stable clustering centers by integrating consistent outputs. Our approach, LayerMatch, which integrates these two strategies, can avoid the severe interference of noisy pseudo-labels in the linear classification layer while accelerating the clustering capability of the feature extraction layer. Through extensive experimentation, our approach consistently demonstrates exceptional performance on standard semi-supervised learning benchmarks, achieving a significant improvement of 10.38% over baseline method and a 2.44% increase compared to state-of-the-art methods.
Create account to get full access
Overview
- This paper explores the effectiveness of using pseudo-labels to train different layers of a neural network model.
- Pseudo-labeling is a semi-supervised learning technique that uses model predictions on unlabeled data as targets for training.
- The authors investigate whether pseudo-labels benefit all layers of a model or if certain layers gain more from this approach.
Plain English Explanation
The paper looks at a machine learning technique called "pseudo-labeling". This involves taking a model, using it to make predictions on unlabeled data, and then using those predictions as "fake" labels to further train the model.
The key question the researchers set out to answer is: Do all the different layers (or parts) of the model benefit equally from this pseudo-labeling approach, or are some layers helped more than others?
To investigate this, they trained models using pseudo-labeling and analyzed how the performance of each individual layer changed compared to a model trained without pseudo-labels.
The results provide insight into how pseudo-labeling impacts different parts of a neural network model. This can help researchers and engineers make more informed decisions about when and how to apply pseudo-labeling techniques.
Technical Explanation
The paper explores the performance of pseudo-labeling across different layers of a neural network model. Pseudo-labeling is a semi-supervised learning technique where the model's own predictions on unlabeled data are used as targets for further training.
The authors train models both with and without pseudo-labeling, and then analyze the performance of each individual layer. This allows them to see whether pseudo-labels consistently benefit all layers, or if certain layers gain more from this approach.
Their experiments are conducted on image classification tasks using standard benchmark datasets. They evaluate a range of model architectures, including convolutional neural networks and transformers.
The key finding is that the impact of pseudo-labeling is not uniform across all layers. Some layers, particularly earlier ones, see larger performance gains when pseudo-labels are used. Later layers may actually perform worse with pseudo-labeling in certain cases.
This suggests that a "one-size-fits-all" pseudo-labeling strategy may not be optimal. The authors propose that selectively applying pseudo-labeling to certain layers could lead to better overall model performance.
Critical Analysis
The paper provides a nuanced look at how pseudo-labeling impacts different components of a neural network model. This is an important contribution, as much of the prior work on pseudo-labeling has treated it as a monolithic technique.
One limitation of the study is that it only explores a handful of model architectures and datasets. The generalizability of the findings to other domains and model types is not fully established. Further research would be needed to validate the conclusions across a broader range of settings.
Additionally, the paper does not delve into the potential reasons why pseudo-labeling has varying effects on different layers. Gaining a deeper understanding of the underlying mechanisms could lead to more principled ways of applying the technique.
That said, the paper successfully challenges the common assumption that pseudo-labeling uniformly benefits all aspects of a model. This calls for a more targeted and layer-specific approach to leveraging this semi-supervised learning strategy.
Conclusion
This paper provides valuable insights into the layer-wise effects of pseudo-labeling in neural networks. The key finding is that pseudo-labels do not benefit all layers equally - some layers see larger performance gains than others.
These results suggest that a more nuanced application of pseudo-labeling, rather than a blanket approach, could lead to better overall model performance. The work also highlights the importance of analyzing the inner workings of neural networks rather than treating them as black boxes.
While further research is needed to fully generalize the findings, this paper represents an important step forward in understanding the complex dynamics of semi-supervised learning techniques like pseudo-labeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Smooth Pseudo-Labeling
Nikolaos Karaliolios, Herv'e Le Borgne, Florian Chabot
0
0
Semi-Supervised Learning (SSL) seeks to leverage large amounts of non-annotated data along with the smallest amount possible of annotated data in order to achieve the same level of performance as if all data were annotated. A fruitful method in SSL is Pseudo-Labeling (PL), which, however, suffers from the important drawback that the associated loss function has discontinuities in its derivatives, which cause instabilities in performance when labels are very scarce. In the present work, we address this drawback with the introduction of a Smooth Pseudo-Labeling (SP L) loss function. It consists in adding a multiplicative factor in the loss function that smooths out the discontinuities in the derivative due to thresholding. In our experiments, we test our improvements on FixMatch and show that it significantly improves the performance in the regime of scarce labels, without addition of any modules, hyperparameters, or computational overhead. In the more stable regime of abundant labels, performance remains at the same level. Robustness with respect to variation of hyperparameters and training parameters is also significantly improved. Moreover, we introduce a new benchmark, where labeled images are selected randomly from the whole dataset, without imposing representation of each class proportional to its frequency in the dataset. We see that the smooth version of FixMatch does appear to perform better than the original, non-smooth implementation. However, more importantly, we notice that both implementations do not necessarily see their performance improve when labeled images are added, an important issue in the design of SSL algorithms that should be addressed so that Active Learning algorithms become more reliable and explainable.
5/24/2024
AllMatch: Exploiting All Unlabeled Data for Semi-Supervised Learning
Zhiyu Wu, Jinshi Cui
0
0
Existing semi-supervised learning algorithms adopt pseudo-labeling and consistency regulation techniques to introduce supervision signals for unlabeled samples. To overcome the inherent limitation of threshold-based pseudo-labeling, prior studies have attempted to align the confidence threshold with the evolving learning status of the model, which is estimated through the predictions made on the unlabeled data. In this paper, we further reveal that classifier weights can reflect the differentiated learning status across categories and consequently propose a class-specific adaptive threshold mechanism. Additionally, considering that even the optimal threshold scheme cannot resolve the problem of discarding unlabeled samples, a binary classification consistency regulation approach is designed to distinguish candidate classes from negative options for all unlabeled samples. By combining the above strategies, we present a novel SSL algorithm named AllMatch, which achieves improved pseudo-label accuracy and a 100% utilization ratio for the unlabeled data. We extensively evaluate our approach on multiple benchmarks, encompassing both balanced and imbalanced settings. The results demonstrate that AllMatch consistently outperforms existing state-of-the-art methods.
6/26/2024
🌐
Prompt-based Pseudo-labeling Strategy for Sample-Efficient Semi-Supervised Extractive Summarization
Gaurav Sahu, Olga Vechtomova, Issam H. Laradji
0
0
Semi-supervised learning (SSL) is a widely used technique in scenarios where labeled data is scarce and unlabeled data is abundant. While SSL is popular for image and text classification, it is relatively underexplored for the task of extractive text summarization. Standard SSL methods follow a teacher-student paradigm to first train a classification model and then use the classifier's confidence values to select pseudo-labels for the subsequent training cycle; however, such classifiers are not suitable to measure the accuracy of pseudo-labels as they lack specific tuning for evaluation, which leads to confidence values that fail to capture the semantics and correctness of the generated summary. To address this problem, we propose a prompt-based pseudo-labeling strategy with LLMs that picks unlabeled examples with more accurate pseudo-labels than using just the classifier's probability outputs. Our approach also includes a relabeling mechanism that improves the quality of pseudo-labels. We evaluate our method on three text summarization datasets: TweetSumm, WikiHow, and ArXiv/PubMed. We empirically show that a prompting-based LLM that scores and generates pseudo-labels outperforms existing SSL methods on ROUGE-1, ROUGE-2, and ROUGE-L scores on all the datasets. Furthermore, our method achieves competitive G-Eval scores (evaluation with GPT-4) as a fully supervised method that uses 100% of the labeled data with only 16.67% of the labeled data.
4/8/2024
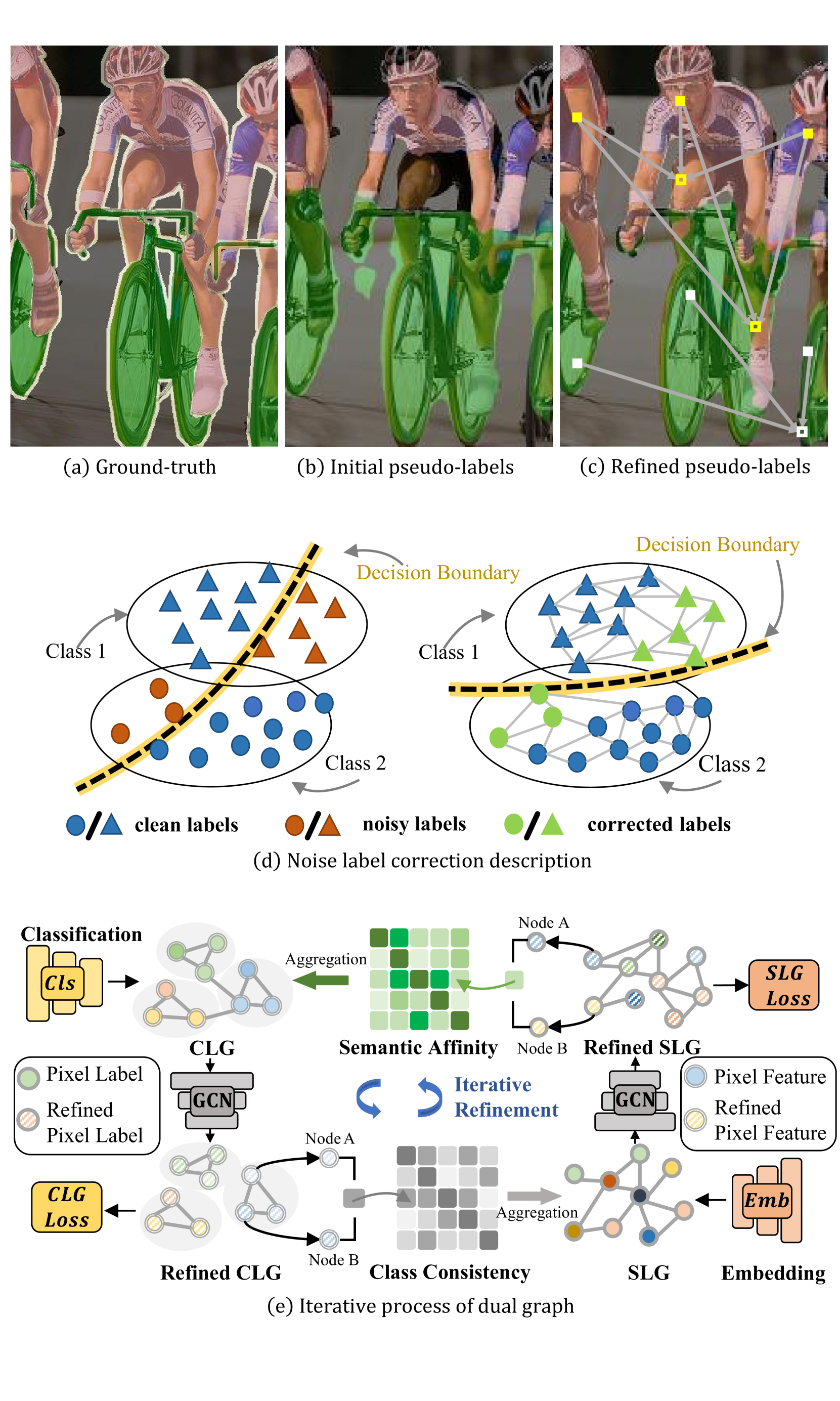
Multi-Level Label Correction by Distilling Proximate Patterns for Semi-supervised Semantic Segmentation
Hui Xiao, Yuting Hong, Li Dong, Diqun Yan, Jiayan Zhuang, Junjie Xiong, Dongtai Liang, Chengbin Peng
0
0
Semi-supervised semantic segmentation relieves the reliance on large-scale labeled data by leveraging unlabeled data. Recent semi-supervised semantic segmentation approaches mainly resort to pseudo-labeling methods to exploit unlabeled data. However, unreliable pseudo-labeling can undermine the semi-supervision processes. In this paper, we propose an algorithm called Multi-Level Label Correction (MLLC), which aims to use graph neural networks to capture structural relationships in Semantic-Level Graphs (SLGs) and Class-Level Graphs (CLGs) to rectify erroneous pseudo-labels. Specifically, SLGs represent semantic affinities between pairs of pixel features, and CLGs describe classification consistencies between pairs of pixel labels. With the support of proximate pattern information from graphs, MLLC can rectify incorrectly predicted pseudo-labels and can facilitate discriminative feature representations. We design an end-to-end network to train and perform this effective label corrections mechanism. Experiments demonstrate that MLLC can significantly improve supervised baselines and outperforms state-of-the-art approaches in different scenarios on Cityscapes and PASCAL VOC 2012 datasets. Specifically, MLLC improves the supervised baseline by at least 5% and 2% with DeepLabV2 and DeepLabV3+ respectively under different partition protocols.
4/11/2024