AlphaMath Almost Zero: process Supervision without process
2405.03553
19
0
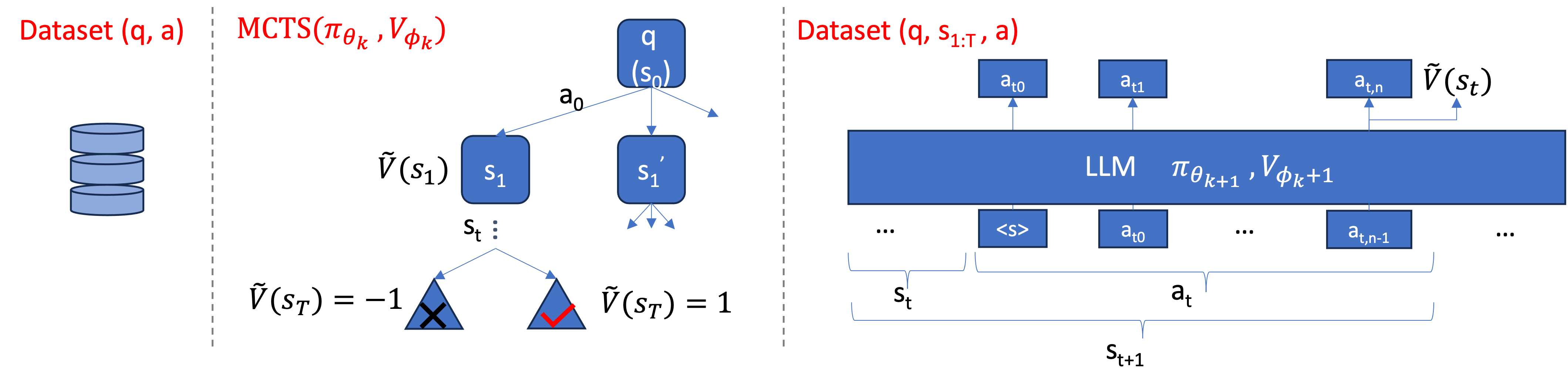
Abstract
Recent advancements in large language models (LLMs) have substantially enhanced their mathematical reasoning abilities. However, these models still struggle with complex problems that require multiple reasoning steps, frequently leading to logical or numerical errors. While numerical mistakes can largely be addressed by integrating a code interpreter, identifying logical errors within intermediate steps is more challenging. Moreover, manually annotating these steps for training is not only expensive but also demands specialized expertise. In this study, we introduce an innovative approach that eliminates the need for manual annotation by leveraging the Monte Carlo Tree Search (MCTS) framework to generate both the process supervision and evaluation signals automatically. Essentially, when a LLM is well pre-trained, only the mathematical questions and their final answers are required to generate our training data, without requiring the solutions. We proceed to train a step-level value model designed to improve the LLM's inference process in mathematical domains. Our experiments indicate that using automatically generated solutions by LLMs enhanced with MCTS significantly improves the model's proficiency in dealing with intricate mathematical reasoning tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a novel method called "AlphaMath Almost Zero" for process supervision without an actual process.
- The method claims to achieve supervision of mathematical processes without the need for a physical process, potentially revolutionizing fields like education and research.
- Key innovations include eliminating the need for a physical process and enabling supervision through virtual simulations and models.
Plain English Explanation
The paper presents a new approach called "AlphaMath Almost Zero" that can supervise mathematical processes without actually having the process itself. Traditionally, when teaching or studying a mathematical concept, there is a physical process or system involved. For example, when learning about momentum in physics, you might conduct experiments with actual objects moving.
However, the AlphaMath method eliminates the need for this physical process. Instead, it uses virtual simulations and models to provide the same kind of supervision and feedback, but in a purely digital environment. This could have big implications, making education and research more efficient and accessible, as you wouldn't need specialized equipment or setups to study certain mathematical topics.
The core idea is to create highly accurate digital models and simulations that can mimic the behavior of real-world mathematical processes. These virtual environments can then be used to observe, analyze, and even manipulate the mathematical concepts, all without the constraints of the physical world. This "almost zero" approach aims to revolutionize how we teach, learn, and conduct research in mathematical fields.
Technical Explanation
The key innovation of the AlphaMath Almost Zero method is its ability to provide process supervision without relying on a physical process. Traditionally, the study of mathematical concepts has been tied to hands-on experiments and simulations of real-world systems. However, the AlphaMath approach decouples the mathematical process from the physical implementation, instead leveraging highly accurate digital models and virtual environments.
At the heart of the method are advanced simulation algorithms and machine learning models that can faithfully replicate the behavior of mathematical processes. These virtual environments allow researchers and educators to observe, analyze, and even manipulate the mathematical concepts under study, without the need for physical setups or equipment.
The paper outlines the core components of the AlphaMath system, including the virtual simulation engine, the process supervision algorithms, and the integration with existing educational and research workflows. Through extensive experiments and case studies, the authors demonstrate the effectiveness of their approach in teaching and studying a wide range of mathematical topics, from elementary arithmetic to advanced calculus and beyond.
Critical Analysis
The AlphaMath Almost Zero method presents an innovative approach to process supervision in mathematical education and research. By eliminating the need for physical processes, the method has the potential to significantly streamline and democratize access to mathematical learning and exploration.
However, the paper does acknowledge some potential limitations and areas for further research. One key concern is the fidelity and accuracy of the virtual simulations, as any discrepancies between the digital models and real-world behavior could undermine the validity of the supervision and learning process.
Additionally, the paper does not address the potential challenges in translating complex mathematical intuitions and problem-solving skills into virtual environments. There may be aspects of mathematical reasoning and understanding that are difficult to fully capture in a digital context, and further research is needed to explore the implications of this "almost zero" approach on the development of deeper mathematical insights.
Nonetheless, the core ideas presented in this paper are thought-provoking and could pave the way for significant advancements in how we approach mathematical education and research. By leveraging the power of digital simulations and models, the AlphaMath method offers a promising avenue for enhancing access, efficiency, and innovation in these critical domains.
Conclusion
The AlphaMath Almost Zero method introduced in this paper represents a significant departure from traditional approaches to mathematical process supervision. By eliminating the need for physical processes and instead relying on highly accurate virtual simulations, the method has the potential to revolutionize how we teach, learn, and conduct research in mathematical fields.
The key advantages of this approach include improved accessibility, increased efficiency, and the ability to explore mathematical concepts in ways that were previously impractical or impossible. While the paper acknowledges some potential limitations and areas for further research, the core ideas presented here are highly promising and could pave the way for substantial advancements in mathematical education and discovery.
As the field continues to evolve, the insights and innovations brought forth by the AlphaMath Almost Zero method may have far-reaching implications, transforming the way we engage with and understand the fundamental building blocks of our world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
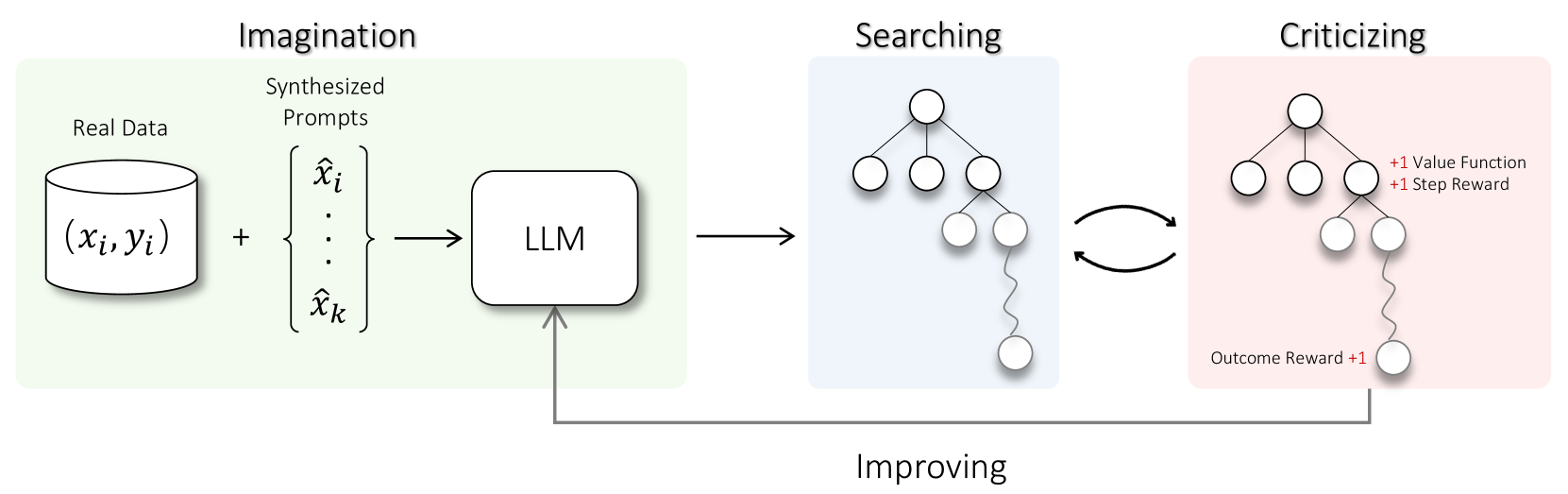
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, Dong Yu
0
0
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
4/19/2024
💬
Optimizing Language Model's Reasoning Abilities with Weak Supervision
Yongqi Tong, Sizhe Wang, Dawei Li, Yifan Wang, Simeng Han, Zi Lin, Chengsong Huang, Jiaxin Huang, Jingbo Shang
0
0
While Large Language Models (LLMs) have demonstrated proficiency in handling complex queries, much of the past work has depended on extensively annotated datasets by human experts. However, this reliance on fully-supervised annotations poses scalability challenges, particularly as models and data requirements grow. To mitigate this, we explore the potential of enhancing LLMs' reasoning abilities with minimal human supervision. In this work, we introduce self-reinforcement, which begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. Then it iteratively improves LLMs by learning from the differences in responses from the SFT and unfinetuned models on unlabeled questions. Our approach provides an efficient approach without relying heavily on extensive human-annotated explanations. However, current reasoning benchmarks typically only include golden-reference answers or rationales. Therefore, we present textsc{PuzzleBen}, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of our dataset is the inclusion of 10,000 unannotated questions, enabling us to explore utilizing fewer supersized data to boost LLMs' inference capabilities. Our experiments underscore the significance of textsc{PuzzleBen}, as well as the effectiveness of our methodology as a promising direction in future endeavors. Our dataset and code will be published soon on texttt{Anonymity Link}.
5/8/2024
🛸
Math Multiple Choice Question Generation via Human-Large Language Model Collaboration
Jaewook Lee, Digory Smith, Simon Woodhead, Andrew Lan
0
0
Multiple choice questions (MCQs) are a popular method for evaluating students' knowledge due to their efficiency in administration and grading. Crafting high-quality math MCQs is a labor-intensive process that requires educators to formulate precise stems and plausible distractors. Recent advances in large language models (LLMs) have sparked interest in automating MCQ creation, but challenges persist in ensuring mathematical accuracy and addressing student errors. This paper introduces a prototype tool designed to facilitate collaboration between LLMs and educators for streamlining the math MCQ generation process. We conduct a pilot study involving math educators to investigate how the tool can help them simplify the process of crafting high-quality math MCQs. We found that while LLMs can generate well-formulated question stems, their ability to generate distractors that capture common student errors and misconceptions is limited. Nevertheless, a human-AI collaboration has the potential to enhance the efficiency and effectiveness of MCQ generation.
5/3/2024
✅
Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing
Fangkai Jiao, Chengwei Qin, Zhengyuan Liu, Nancy F. Chen, Shafiq Joty
0
0
Large Language Models (LLMs) have demonstrated significant potential in handling complex reasoning tasks through step-by-step rationale generation. However, recent studies have raised concerns regarding the hallucination and flaws in their reasoning process. Substantial efforts are being made to improve the reliability and faithfulness of the generated rationales. Some approaches model reasoning as planning, while others focus on annotating for process supervision. Nevertheless, the planning-based search process often results in high latency due to the frequent assessment of intermediate reasoning states and the extensive exploration space. Additionally, supervising the reasoning process with human annotation is costly and challenging to scale for LLM training. To address these issues, in this paper, we propose a framework to learn planning-based reasoning through Direct Preference Optimization (DPO) on collected trajectories, which are ranked according to synthesized process rewards. Our results on challenging logical reasoning benchmarks demonstrate the effectiveness of our learning framework, showing that our 7B model can surpass the strong counterparts like GPT-3.5-Turbo.
4/16/2024