Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing
2402.00658
0
0
✅
Abstract
Large Language Models (LLMs) have demonstrated significant potential in handling complex reasoning tasks through step-by-step rationale generation. However, recent studies have raised concerns regarding the hallucination and flaws in their reasoning process. Substantial efforts are being made to improve the reliability and faithfulness of the generated rationales. Some approaches model reasoning as planning, while others focus on annotating for process supervision. Nevertheless, the planning-based search process often results in high latency due to the frequent assessment of intermediate reasoning states and the extensive exploration space. Additionally, supervising the reasoning process with human annotation is costly and challenging to scale for LLM training. To address these issues, in this paper, we propose a framework to learn planning-based reasoning through Direct Preference Optimization (DPO) on collected trajectories, which are ranked according to synthesized process rewards. Our results on challenging logical reasoning benchmarks demonstrate the effectiveness of our learning framework, showing that our 7B model can surpass the strong counterparts like GPT-3.5-Turbo.
Create account to get full access
Overview
- Large language models (LLMs) have shown promise in complex reasoning tasks through step-by-step rationale generation.
- However, recent studies have raised concerns about hallucination and flaws in their reasoning process.
- Efforts are underway to improve the reliability and faithfulness of the generated rationales.
- Some approaches model reasoning as planning, while others focus on annotating for process supervision.
- Planning-based search often results in high latency due to frequent assessment of intermediate reasoning states and the large exploration space.
- Annotating the reasoning process with human feedback is costly and challenging to scale for LLM training.
Plain English Explanation
Large language models are powerful AI systems that can understand and generate human-like text. Researchers have found that these models can be used for complex reasoning tasks, where the model explains its thought process step-by-step. However, recent studies have shown that these models can sometimes produce incorrect or nonsensical reasoning, a problem known as "hallucination." [https://aimodels.fyi/papers/arxiv/llm-reasoners-new-evaluation-library-analysis-step]
To address this issue, researchers are exploring different approaches to improve the reliability and accuracy of the models' reasoning process. Some researchers are treating reasoning as a planning problem, where the model plans out a sequence of steps to arrive at the final answer. [https://aimodels.fyi/papers/arxiv/improving-language-model-reasoning-self-motivated-learning] Others are focusing on teaching the models to explain their reasoning in a more transparent and faithful way, by having humans annotate the models' thought processes. [https://aimodels.fyi/papers/arxiv/direct-preference-optimization-video-large-multimodal-models]
However, these approaches have their own challenges. The planning-based approach can be slow and computationally intensive, as the model has to constantly evaluate intermediate reasoning states. And the human annotation approach is costly and difficult to scale up for training large language models. [https://aimodels.fyi/papers/arxiv/can-only-llms-do-reasoning-potential-small]
Technical Explanation
In this paper, the researchers propose a new framework to address these issues. They use a technique called "Direct Preference Optimization" (DPO) to learn planning-based reasoning from collected trajectories, which are ranked according to synthesized process rewards. This allows the model to learn reliable reasoning without the high computational cost of the traditional planning-based approach, and without the need for expensive human annotations.
The researchers evaluated their framework on challenging logical reasoning benchmarks and found that their 7B-parameter model was able to outperform strong counterparts like the GPT-3.5-Turbo model. [https://aimodels.fyi/papers/arxiv/can-small-language-models-help-large-language]
Critical Analysis
The researchers have presented a promising approach to improving the reliability and faithfulness of large language models' reasoning process. By utilizing DPO to learn from ranked trajectories, they were able to bypass some of the key challenges of traditional planning-based and annotation-based methods.
However, the paper does not delve into the specific details of how the process rewards were synthesized, which could be an important factor in the model's performance. Additionally, the researchers only evaluated their framework on logical reasoning tasks, so it's unclear how well it would generalize to other types of complex reasoning.
Further research could explore the broader applicability of this approach, as well as investigate the sensitivity of the framework to the quality and composition of the training data. Ultimately, this work represents an important step towards more reliable and trustworthy language models for complex reasoning tasks.
Conclusion
This paper proposes a new framework for learning planning-based reasoning in large language models, using a technique called Direct Preference Optimization. By learning from ranked trajectories with synthesized process rewards, the researchers were able to improve the reliability and faithfulness of the models' reasoning process, while avoiding the high computational cost and scalability challenges of traditional approaches.
The results on logical reasoning benchmarks are promising, showing that the researchers' 7B-parameter model can outperform strong counterparts. This work represents an important advancement in the field of large language models and their application to complex reasoning tasks, with potential implications for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh
0
0
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and ARC-C, with substantial increases in accuracy to $81.8%$ (+$5.9%$), $34.7%$ (+$5.8%$), and $76.4%$ (+$15.8%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains. Our code is publicly available at https://github.com/YuxiXie/MCTS-DPO.
6/19/2024
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, Abhinav Rastogi
0
0
Complex multi-step reasoning tasks, such as solving mathematical problems or generating code, remain a significant hurdle for even the most advanced large language models (LLMs). Verifying LLM outputs with an Outcome Reward Model (ORM) is a standard inference-time technique aimed at enhancing the reasoning performance of LLMs. However, this still proves insufficient for reasoning tasks with a lengthy or multi-hop reasoning chain, where the intermediate outcomes are neither properly rewarded nor penalized. Process supervision addresses this limitation by assigning intermediate rewards during the reasoning process. To date, the methods used to collect process supervision data have relied on either human annotation or per-step Monte Carlo estimation, both prohibitively expensive to scale, thus hindering the broad application of this technique. In response to this challenge, we propose a novel divide-and-conquer style Monte Carlo Tree Search (MCTS) algorithm named textit{OmegaPRM} for the efficient collection of high-quality process supervision data. This algorithm swiftly identifies the first error in the Chain of Thought (CoT) with binary search and balances the positive and negative examples, thereby ensuring both efficiency and quality. As a result, we are able to collect over 1.5 million process supervision annotations to train a Process Reward Model (PRM). Utilizing this fully automated process supervision alongside the weighted self-consistency algorithm, we have enhanced the instruction tuned Gemini Pro model's math reasoning performance, achieving a 69.4% success rate on the MATH benchmark, a 36% relative improvement from the 51% base model performance. Additionally, the entire process operates without any human intervention, making our method both financially and computationally cost-effective compared to existing methods.
6/12/2024
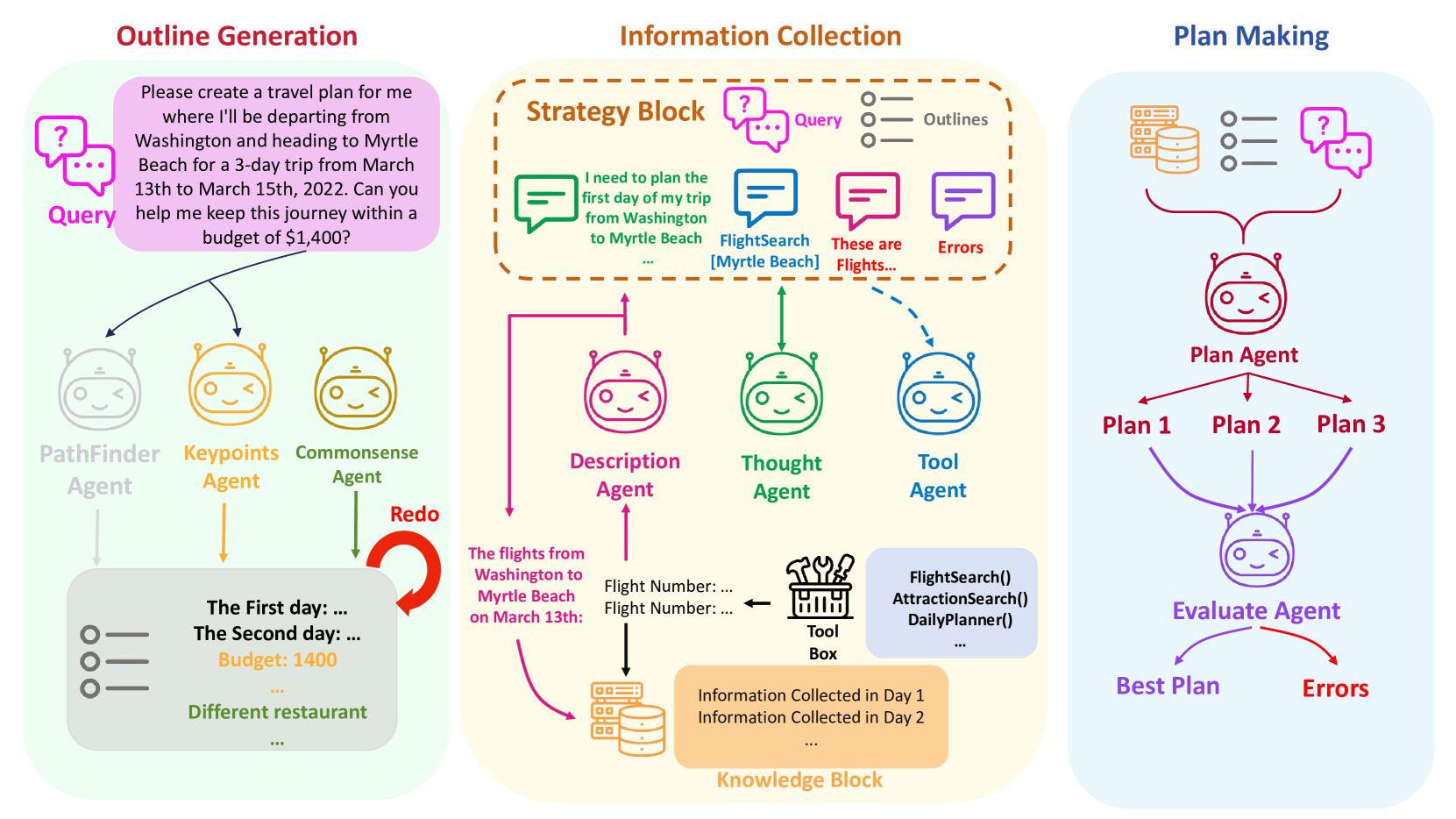
A Human-Like Reasoning Framework for Multi-Phases Planning Task with Large Language Models
Chengxing Xie, Difan Zou
0
0
Recent studies have highlighted their proficiency in some simple tasks like writing and coding through various reasoning strategies. However, LLM agents still struggle with tasks that require comprehensive planning, a process that challenges current models and remains a critical research issue. In this study, we concentrate on travel planning, a Multi-Phases planning problem, that involves multiple interconnected stages, such as outlining, information gathering, and planning, often characterized by the need to manage various constraints and uncertainties. Existing reasoning approaches have struggled to effectively address this complex task. Our research aims to address this challenge by developing a human-like planning framework for LLM agents, i.e., guiding the LLM agent to simulate various steps that humans take when solving Multi-Phases problems. Specifically, we implement several strategies to enable LLM agents to generate a coherent outline for each travel query, mirroring human planning patterns. Additionally, we integrate Strategy Block and Knowledge Block into our framework: Strategy Block facilitates information collection, while Knowledge Block provides essential information for detailed planning. Through our extensive experiments, we demonstrate that our framework significantly improves the planning capabilities of LLM agents, enabling them to tackle the travel planning task with improved efficiency and effectiveness. Our experimental results showcase the exceptional performance of the proposed framework; when combined with GPT-4-Turbo, it attains $10times$ the performance gains in comparison to the baseline framework deployed on GPT-4-Turbo.
5/29/2024

Distributional reasoning in LLMs: Parallel reasoning processes in multi-hop reasoning
Yuval Shalev, Amir Feder, Ariel Goldstein
0
0
Large language models (LLMs) have shown an impressive ability to perform tasks believed to require thought processes. When the model does not document an explicit thought process, it becomes difficult to understand the processes occurring within its hidden layers and to determine if these processes can be referred to as reasoning. We introduce a novel and interpretable analysis of internal multi-hop reasoning processes in LLMs. We demonstrate that the prediction process for compositional reasoning questions can be modeled using a simple linear transformation between two semantic category spaces. We show that during inference, the middle layers of the network generate highly interpretable embeddings that represent a set of potential intermediate answers for the multi-hop question. We use statistical analyses to show that a corresponding subset of tokens is activated in the model's output, implying the existence of parallel reasoning paths. These observations hold true even when the model lacks the necessary knowledge to solve the task. Our findings can help uncover the strategies that LLMs use to solve reasoning tasks, offering insights into the types of thought processes that can emerge from artificial intelligence. Finally, we also discuss the implication of cognitive modeling of these results.
6/21/2024