Optimizing Language Model's Reasoning Abilities with Weak Supervision
2405.04086
0
0
💬
Abstract
While Large Language Models (LLMs) have demonstrated proficiency in handling complex queries, much of the past work has depended on extensively annotated datasets by human experts. However, this reliance on fully-supervised annotations poses scalability challenges, particularly as models and data requirements grow. To mitigate this, we explore the potential of enhancing LLMs' reasoning abilities with minimal human supervision. In this work, we introduce self-reinforcement, which begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. Then it iteratively improves LLMs by learning from the differences in responses from the SFT and unfinetuned models on unlabeled questions. Our approach provides an efficient approach without relying heavily on extensive human-annotated explanations. However, current reasoning benchmarks typically only include golden-reference answers or rationales. Therefore, we present textsc{PuzzleBen}, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of our dataset is the inclusion of 10,000 unannotated questions, enabling us to explore utilizing fewer supersized data to boost LLMs' inference capabilities. Our experiments underscore the significance of textsc{PuzzleBen}, as well as the effectiveness of our methodology as a promising direction in future endeavors. Our dataset and code will be published soon on texttt{Anonymity Link}.
Create account to get full access
Overview
- Large Language Models (LLMs) have demonstrated impressive capabilities in handling complex queries, but they have traditionally relied on extensively annotated datasets created by human experts.
- This reliance on fully-supervised annotations poses scalability challenges as models and data requirements grow.
- To address this, the researchers explore enhancing LLMs' reasoning abilities with minimal human supervision, introducing a self-reinforcement approach.
- They also present PuzzleBen, a weakly supervised benchmark with 25,147 complex questions, answers, and human-generated rationales across various domains.
Plain English Explanation
Large language models are incredibly powerful tools that can understand and respond to complex queries. However, these models have typically been trained using extensive datasets that have been carefully annotated by human experts. This reliance on fully-supervised data can be a significant challenge as the models and the data they require continue to grow in scale.
To address this issue, the researchers in this paper have explored a new approach called "self-reinforcement." This method starts by training the model using a small collection of annotated questions, a process known as Supervised Fine-Tuning (SFT). Then, the model is further improved by learning from the differences between its own responses and the responses of the unfinetuned model on unannotated questions.
This self-reinforcement approach allows the model to enhance its reasoning abilities without relying heavily on extensive human-provided explanations. This is an important step forward, as current reasoning benchmarks typically only include the correct answers or explanations, rather than the full range of questions and responses.
To address this, the researchers have also introduced a new dataset called PuzzleBen. This dataset includes 25,147 complex questions, answers, and human-generated rationales across a variety of domains, such as brainteasers, puzzles, riddles, and critical reasoning tasks. Importantly, the dataset also includes 10,000 unannotated questions, allowing the researchers to explore how fewer but larger datasets can be used to boost the inference capabilities of language models.
Overall, this research represents an exciting step forward in the development of more efficient and scalable language models that can reason and problem-solve with minimal human supervision.
Technical Explanation
The paper introduces a novel approach called "self-reinforcement" to enhance the reasoning abilities of Large Language Models (LLMs) with minimal human supervision. The method begins with Supervised Fine-Tuning (SFT) of the model using a small collection of annotated questions. It then iteratively improves the LLM by learning from the differences in responses between the SFT-trained model and the unfinetuned model on unlabeled questions.
This approach aims to address the scalability challenges posed by the reliance on extensively annotated datasets, which are typically required to train high-performing LLMs. By incorporating self-reinforcement, the model can learn to reason more effectively without the need for extensive human-provided explanations.
To facilitate this research, the authors also introduce PuzzleBen, a weakly supervised benchmark that comprises 25,147 complex questions, answers, and human-generated rationales across various domains, such as brainteasers, puzzles, riddles, parajumbles, and critical reasoning tasks. A unique aspect of this dataset is the inclusion of 10,000 unannotated questions, enabling the exploration of using fewer but larger datasets to boost LLMs' inference capabilities.
The experimental results presented in the paper underscore the significance of the PuzzleBen dataset and the effectiveness of the self-reinforcement methodology as a promising direction for future research in enhancing the reasoning abilities of large language models.
Critical Analysis
The paper presents a compelling approach to improving the reasoning capabilities of LLMs with minimal human supervision. The self-reinforcement method is an innovative way to leverage unlabeled data to enhance model performance, which could lead to more scalable and efficient language models.
However, the paper does not fully address the potential limitations of this approach. For instance, the researchers acknowledge that current reasoning benchmarks, including PuzzleBen, typically only include golden-reference answers or rationales, which may not capture the full spectrum of valid responses. Additionally, the paper does not discuss the potential risks or societal implications of deploying large language models with enhanced reasoning abilities, such as the potential for biased or harmful outputs.
Furthermore, the PuzzleBen dataset, while a valuable contribution, may not be representative of all types of reasoning tasks that LLMs may encounter in real-world applications. The researchers could consider expanding the dataset to include a more diverse range of reasoning challenges, such as those found in specific domains or contexts.
Despite these caveats, the research presented in this paper represents an important step forward in the development of more capable and efficient language models. By exploring self-reinforcement and introducing a novel benchmark, the authors have laid the groundwork for further advancements in this field.
Conclusion
This paper presents a novel approach called "self-reinforcement" to enhance the reasoning abilities of Large Language Models (LLMs) with minimal human supervision. By combining Supervised Fine-Tuning (SFT) with an iterative learning process that leverages unlabeled data, the researchers have developed a promising method for improving LLM performance without relying heavily on extensive human-annotated explanations.
To support this research, the authors have also introduced PuzzleBen, a weakly supervised benchmark that includes a diverse set of complex reasoning tasks. This dataset, with its inclusion of unannotated questions, enables the exploration of using fewer but larger datasets to boost LLMs' inference capabilities.
The findings in this paper underscore the significance of the PuzzleBen dataset and the effectiveness of the self-reinforcement methodology as a promising direction for future research in enhancing the reasoning abilities of large language models. As these models continue to grow in scale and complexity, developing more efficient and scalable training approaches will be crucial for their widespread adoption and real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Improving Language Model Reasoning with Self-motivated Learning
Yunlong Feng, Yang Xu, Libo Qin, Yasheng Wang, Wanxiang Che
0
0
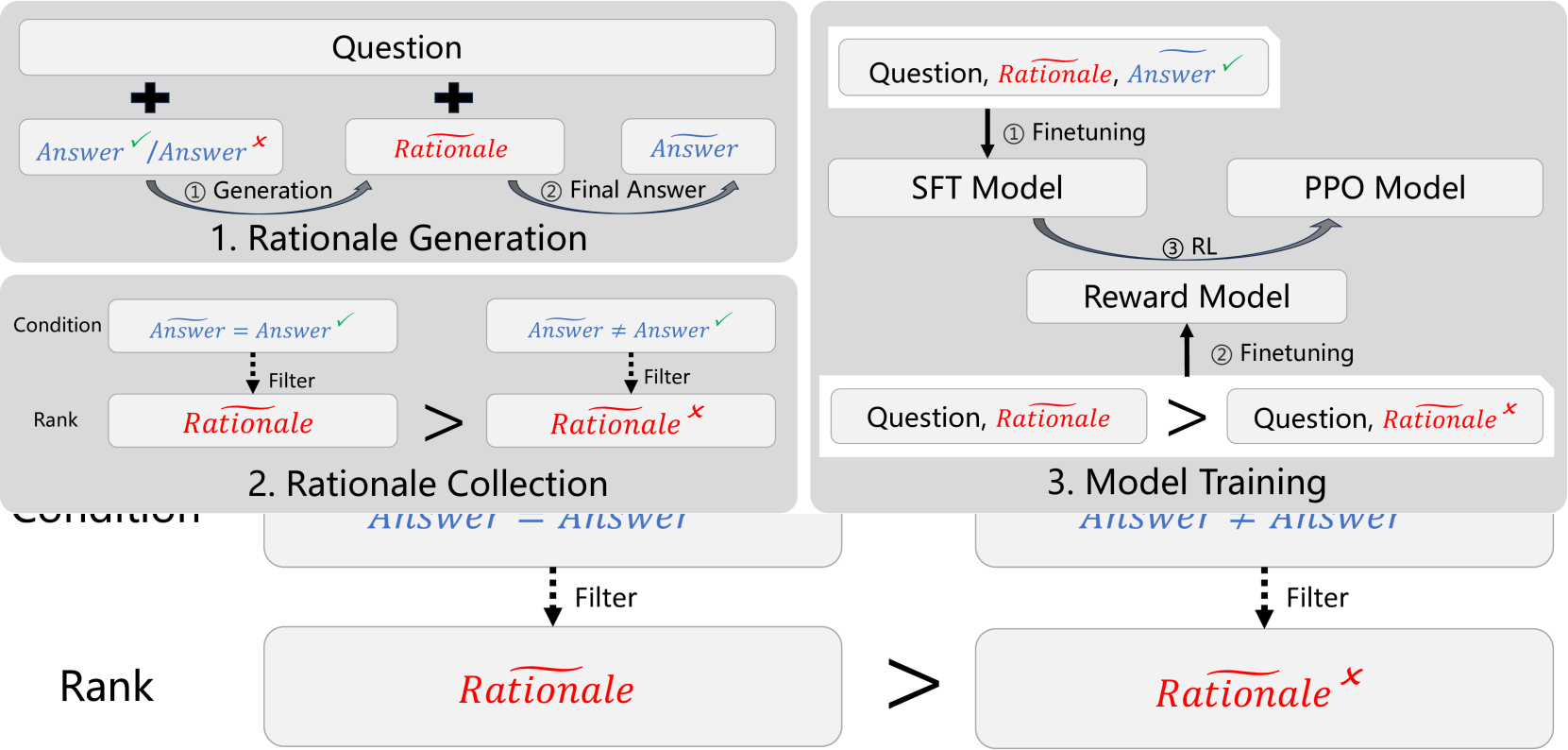
Large-scale high-quality training data is important for improving the performance of models. After trained with data that has rationales (reasoning steps), models gain reasoning capability. However, the dataset with high-quality rationales is relatively scarce due to the high annotation cost. To address this issue, we propose textit{Self-motivated Learning} framework. The framework motivates the model itself to automatically generate rationales on existing datasets. Based on the inherent rank from correctness across multiple rationales, the model learns to generate better rationales, leading to higher reasoning capability. Specifically, we train a reward model with the rank to evaluate the quality of rationales, and improve the performance of reasoning through reinforcement learning. Experiment results of Llama2 7B on multiple reasoning datasets show that our method significantly improves the reasoning ability of models, even outperforming text-davinci-002 in some datasets.
5/1/2024
🌀
New!ReFT: Reasoning with Reinforced Fine-Tuning
Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, Hang Li
0
0
One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question. To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs on-line reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question and the rewards are naturally derived from the ground-truth answers. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
6/28/2024
💬
Leveraging Large Language Models for Knowledge-free Weak Supervision in Clinical Natural Language Processing
Enshuo Hsu, Kirk Roberts
0
0
The performance of deep learning-based natural language processing systems is based on large amounts of labeled training data which, in the clinical domain, are not easily available or affordable. Weak supervision and in-context learning offer partial solutions to this issue, particularly using large language models (LLMs), but their performance still trails traditional supervised methods with moderate amounts of gold-standard data. In particular, inferencing with LLMs is computationally heavy. We propose an approach leveraging fine-tuning LLMs and weak supervision with virtually no domain knowledge that still achieves consistently dominant performance. Using a prompt-based approach, the LLM is used to generate weakly-labeled data for training a downstream BERT model. The weakly supervised model is then further fine-tuned on small amounts of gold standard data. We evaluate this approach using Llama2 on three different n2c2 datasets. With no more than 10 gold standard notes, our final BERT models weakly supervised by fine-tuned Llama2-13B consistently outperformed out-of-the-box PubMedBERT by 4.7% to 47.9% in F1 scores. With only 50 gold standard notes, our models achieved close performance to fully fine-tuned systems.
6/12/2024
Self-Explore to Avoid the Pit: Improving the Reasoning Capabilities of Language Models with Fine-grained Rewards
Hyeonbin Hwang, Doyoung Kim, Seungone Kim, Seonghyeon Ye, Minjoon Seo
0
0
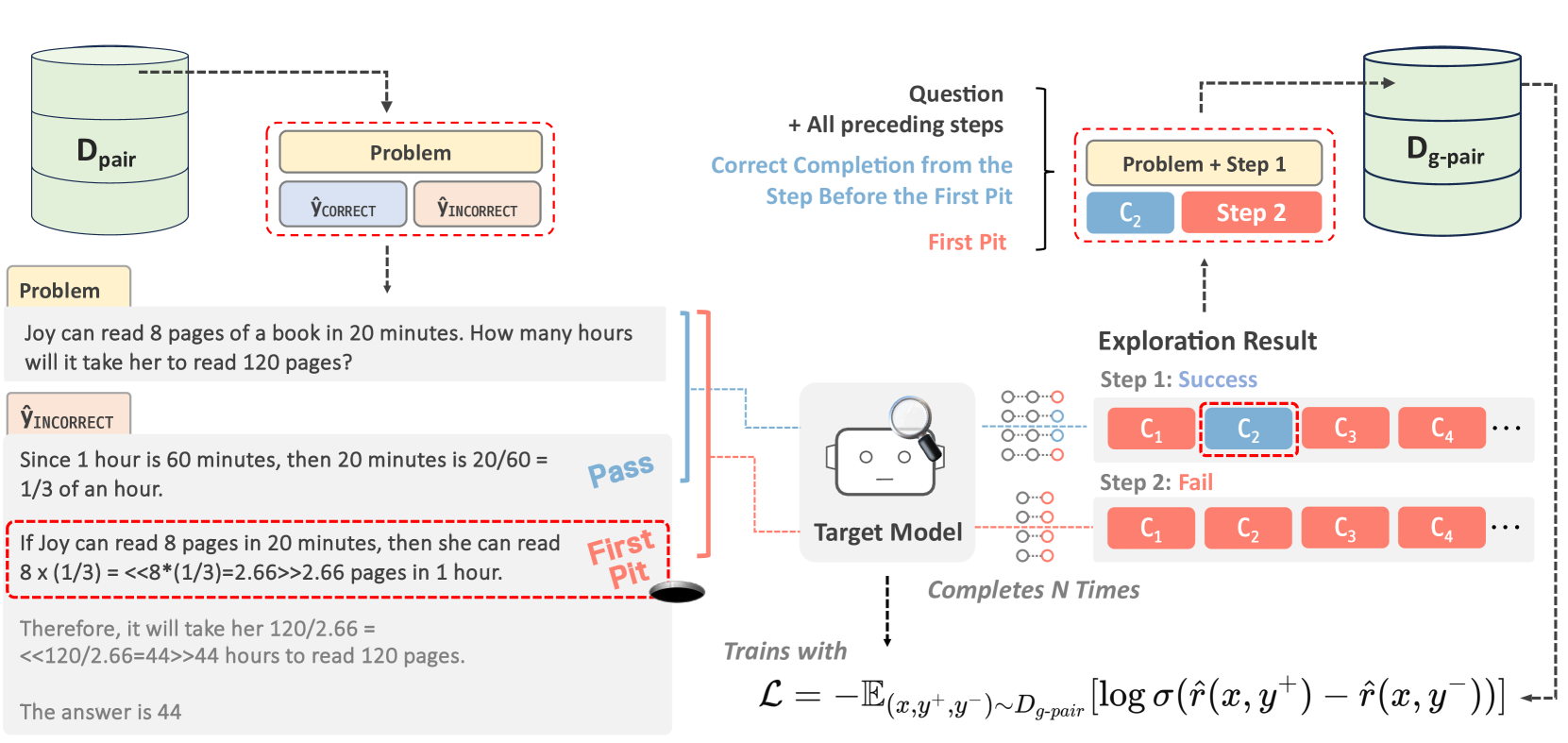
Training on large amounts of rationales (i.e., CoT Fine-tuning) is effective at improving the reasoning capabilities of large language models (LLMs). However, acquiring human-authored rationales or augmenting rationales from proprietary models is costly and not scalable. In this paper, we study the problem of whether LLMs could self-improve their reasoning capabilities. To this end, we propose Self-Explore, where the LLM is tasked to explore the first wrong step (i.e., the first pit) within the rationale and use such signals as fine-grained rewards for further improvement. On the GSM8K and MATH test set, Self-Explore achieves 11.57% and 2.89% improvement on average across three LLMs compared to supervised fine-tuning (SFT). Our code is available at https://github.com/hbin0701/Self-Explore.
5/17/2024