AMD: Automatic Multi-step Distillation of Large-scale Vision Models

0

Sign in to get full access
Overview
- This paper introduces AMD, an automatic multi-step distillation method for compressing large-scale vision models.
- AMD progressively distills the original model into smaller and more efficient models by leveraging multiple distillation stages.
- The approach aims to strike a balance between model performance and computational efficiency.
Plain English Explanation
Knowledge distillation is a technique used to compress large, complex machine learning models into smaller, more efficient ones. The idea is to transfer the knowledge from a larger "teacher" model to a smaller "student" model, allowing the student to achieve similar performance with reduced computational requirements.
The authors of this paper present AMD, an automatic multi-step distillation approach that takes this concept further. Instead of a single distillation step, AMD progressively distills the original large model into a series of smaller and more efficient models. This allows for a more fine-tuned balance between model performance and computational efficiency, depending on the specific needs of the application.
The key innovation of AMD is its ability to automatically determine the optimal number of distillation steps and the appropriate model sizes at each step, without requiring manual tuning. This makes the process more scalable and accessible to a wider range of users and use cases.
Technical Explanation
The AMD framework consists of three main components: a teacher model, a student model, and a multi-step distillation process. The teacher model is the original large-scale vision model, and the student model is the compressed version that will be output by the framework.
The multi-step distillation process is the core of the AMD approach. It involves iteratively distilling the teacher model into smaller student models, with each step producing a more compact model while maintaining high performance. The authors use a network pruning technique to gradually reduce the size of the student model, coupled with knowledge distillation to transfer the necessary information from the teacher.
The automatic aspect of AMD comes from its ability to determine the optimal number of distillation steps and the appropriate model sizes at each step. This is achieved through a multi-objective optimization process that considers factors like model performance, computational cost, and memory usage.
The authors evaluate AMD on several large-scale vision tasks, including image classification, object detection, and instance segmentation. The results demonstrate that AMD can effectively compress large models while maintaining high accuracy, outperforming single-step distillation approaches.
Critical Analysis
The paper provides a thorough technical explanation of the AMD framework and its key components. The authors have addressed important considerations, such as the need for a balance between model performance and computational efficiency, as well as the challenges of automating the distillation process.
One potential limitation of the approach is that it may not be suitable for all types of vision models or tasks. The authors mention that the performance of the distilled models can vary depending on the specific characteristics of the original teacher model and the target task. Further research may be needed to explore the generalizability of AMD across a wider range of computer vision applications.
Additionally, the paper does not provide much insight into the real-world implications or potential use cases of the AMD framework. It would be valuable to see more discussion on how this technology could be applied in practical scenarios, such as deploying efficient models on edge devices or enabling faster inference for time-critical applications.
Conclusion
The AMD framework presented in this paper offers a novel and promising approach to compressing large-scale vision models. By automating the multi-step distillation process, the authors have created a scalable solution that can help bridge the gap between model performance and computational efficiency.
The technical details and experimental results suggest that AMD could be a valuable tool for researchers and practitioners working on deploying high-performing yet resource-constrained computer vision systems. While there are some potential limitations to consider, the core ideas behind AMD demonstrate the continued progress in model compression and knowledge distillation techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AMD: Automatic Multi-step Distillation of Large-scale Vision Models
Cheng Han, Qifan Wang, Sohail A. Dianat, Majid Rabbani, Raghuveer M. Rao, Yi Fang, Qiang Guan, Lifu Huang, Dongfang Liu
Transformer-based architectures have become the de-facto standard models for diverse vision tasks owing to their superior performance. As the size of the models continues to scale up, model distillation becomes extremely important in various real applications, particularly on devices limited by computational resources. However, prevailing knowledge distillation methods exhibit diminished efficacy when confronted with a large capacity gap between the teacher and the student, e.g, 10x compression rate. In this paper, we present a novel approach named Automatic Multi-step Distillation (AMD) for large-scale vision model compression. In particular, our distillation process unfolds across multiple steps. Initially, the teacher undergoes distillation to form an intermediate teacher-assistant model, which is subsequently distilled further to the student. An efficient and effective optimization framework is introduced to automatically identify the optimal teacher-assistant that leads to the maximal student performance. We conduct extensive experiments on multiple image classification datasets, including CIFAR-10, CIFAR-100, and ImageNet. The findings consistently reveal that our approach outperforms several established baselines, paving a path for future knowledge distillation methods on large-scale vision models.
Read more7/8/2024
👀
0
A Comprehensive Review of Knowledge Distillation in Computer Vision
Gousia Habib, Tausifa jan Saleem, Sheikh Musa Kaleem, Tufail Rouf, Brejesh Lall
Deep learning techniques have been demonstrated to surpass preceding cutting-edge machine learning techniques in recent years, with computer vision being one of the most prominent examples. However, deep learning models suffer from significant drawbacks when deployed in resource-constrained environments due to their large model size and high complexity. Knowledge Distillation is one of the prominent solutions to overcome this challenge. This review paper examines the current state of research on knowledge distillation, a technique for compressing complex models into smaller and simpler ones. The paper provides an overview of the major principles and techniques associated with knowledge distillation and reviews the applications of knowledge distillation in the domain of computer vision. The review focuses on the benefits of knowledge distillation, as well as the problems that must be overcome to improve its effectiveness.
Read more7/24/2024
🏅
0
On Good Practices for Task-Specific Distillation of Large Pretrained Visual Models
Juliette Marrie, Michael Arbel, Julien Mairal, Diane Larlus
Large pretrained visual models exhibit remarkable generalization across diverse recognition tasks. Yet, real-world applications often demand compact models tailored to specific problems. Variants of knowledge distillation have been devised for such a purpose, enabling task-specific compact models (the students) to learn from a generic large pretrained one (the teacher). In this paper, we show that the excellent robustness and versatility of recent pretrained models challenge common practices established in the literature, calling for a new set of optimal guidelines for task-specific distillation. To address the lack of samples in downstream tasks, we also show that a variant of Mixup based on stable diffusion complements standard data augmentation. This strategy eliminates the need for engineered text prompts and improves distillation of generic models into streamlined specialized networks.
Read more5/8/2024
0
Weight Copy and Low-Rank Adaptation for Few-Shot Distillation of Vision Transformers
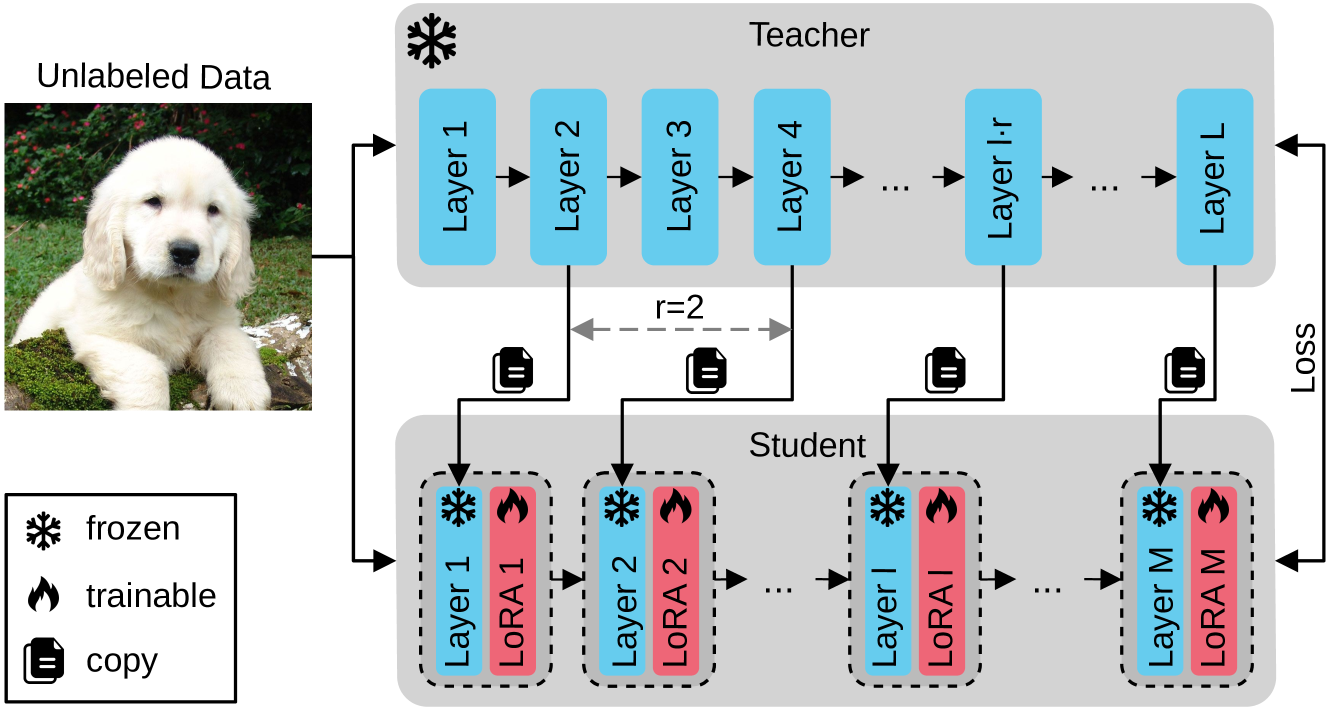
Diana-Nicoleta Grigore, Mariana-Iuliana Georgescu, Jon Alvarez Justo, Tor Johansen, Andreea Iuliana Ionescu, Radu Tudor Ionescu
Few-shot knowledge distillation recently emerged as a viable approach to harness the knowledge of large-scale pre-trained models, using limited data and computational resources. In this paper, we propose a novel few-shot feature distillation approach for vision transformers. Our approach is based on two key steps. Leveraging the fact that vision transformers have a consistent depth-wise structure, we first copy the weights from intermittent layers of existing pre-trained vision transformers (teachers) into shallower architectures (students), where the intermittence factor controls the complexity of the student transformer with respect to its teacher. Next, we employ an enhanced version of Low-Rank Adaptation (LoRA) to distill knowledge into the student in a few-shot scenario, aiming to recover the information processing carried out by the skipped teacher layers. We present comprehensive experiments with supervised and self-supervised transformers as teachers, on five data sets from various domains, including natural, medical and satellite images. The empirical results confirm the superiority of our approach over competitive baselines. Moreover, the ablation results demonstrate the usefulness of each component of the proposed pipeline.
Read more4/16/2024