Weight Copy and Low-Rank Adaptation for Few-Shot Distillation of Vision Transformers
2404.09326
0
0
Abstract
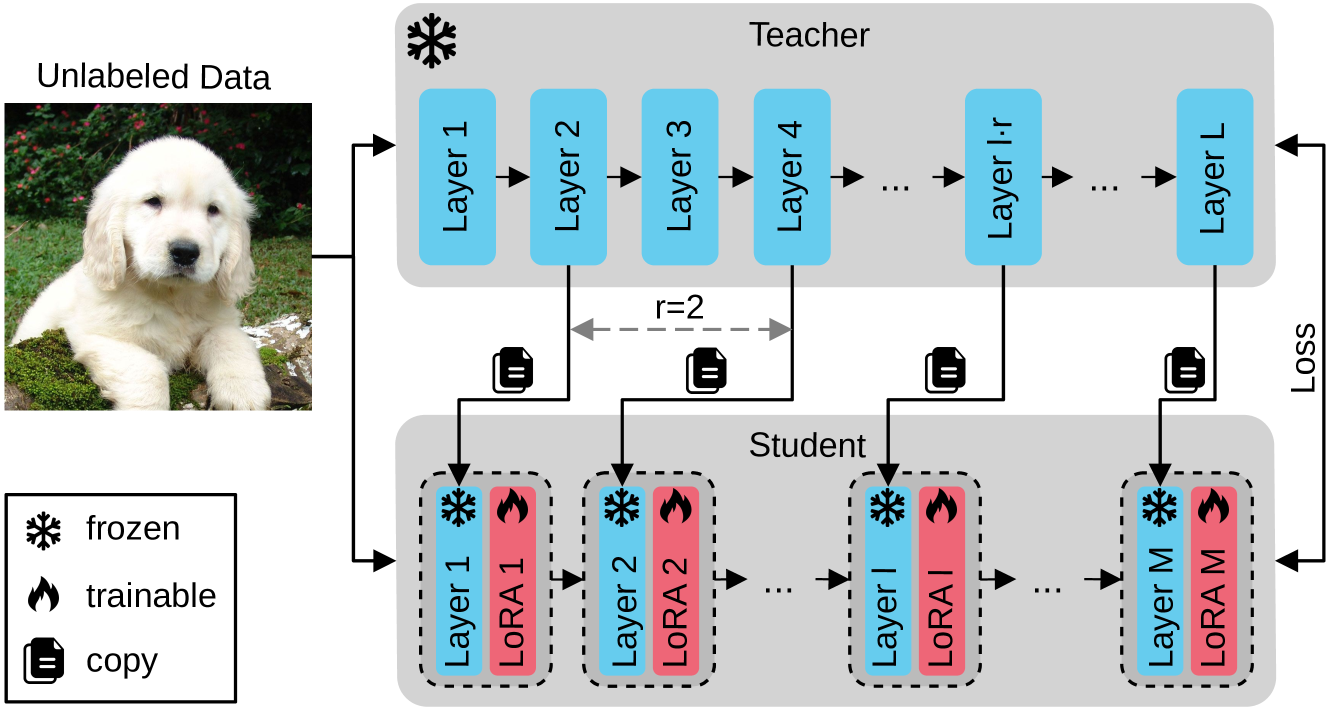
Few-shot knowledge distillation recently emerged as a viable approach to harness the knowledge of large-scale pre-trained models, using limited data and computational resources. In this paper, we propose a novel few-shot feature distillation approach for vision transformers. Our approach is based on two key steps. Leveraging the fact that vision transformers have a consistent depth-wise structure, we first copy the weights from intermittent layers of existing pre-trained vision transformers (teachers) into shallower architectures (students), where the intermittence factor controls the complexity of the student transformer with respect to its teacher. Next, we employ an enhanced version of Low-Rank Adaptation (LoRA) to distill knowledge into the student in a few-shot scenario, aiming to recover the information processing carried out by the skipped teacher layers. We present comprehensive experiments with supervised and self-supervised transformers as teachers, on five data sets from various domains, including natural, medical and satellite images. The empirical results confirm the superiority of our approach over competitive baselines. Moreover, the ablation results demonstrate the usefulness of each component of the proposed pipeline.
Create account to get full access
Overview
- This paper introduces a new method for few-shot distillation of vision transformers, which can efficiently transfer knowledge from a large, pre-trained model to a smaller, more efficient model.
- The key ideas are "weight copy" and "low-rank adaptation", which allow the smaller model to quickly learn from the larger model with minimal fine-tuning.
- The proposed method is evaluated on several benchmark datasets and shown to outperform existing knowledge distillation techniques, particularly in few-shot settings.
Plain English Explanation
In the world of artificial intelligence, there is often a trade-off between the accuracy and efficiency of machine learning models. Large, complex models can achieve state-of-the-art performance, but they can be slow and resource-intensive to deploy. On the other hand, smaller, more efficient models may sacrifice some accuracy.
Knowledge distillation is a technique that aims to bridge this gap by transferring the knowledge from a large, accurate model to a smaller, more efficient one. This paper presents a new approach to knowledge distillation for a specific type of model called a "vision transformer".
Vision transformers are a type of neural network that has shown impressive performance on various computer vision tasks, such as image classification. However, these models can be large and computationally expensive, making them difficult to deploy in real-world applications.
The key ideas in this paper are "weight copy" and "low-rank adaptation". The weight copy approach allows the smaller model to quickly learn the general structure of the larger model, while the low-rank adaptation fine-tunes the smaller model to the specific task at hand. This combination of techniques enables the smaller model to achieve high performance with only a small amount of fine-tuning, making it much more efficient than training the smaller model from scratch.
The researchers evaluate their method on several benchmark datasets and show that it outperforms existing knowledge distillation techniques, particularly in "few-shot" settings, where the smaller model is only trained on a small amount of data. This is an important result, as it means the smaller model can be quickly and efficiently deployed in real-world applications without sacrificing too much accuracy.
Technical Explanation
The paper introduces a new method for few-shot distillation of vision transformers, which aims to efficiently transfer knowledge from a large, pre-trained model to a smaller, more efficient model. The key components of the proposed method are:
-
Weight Copy: The researchers initialize the smaller model's parameters by copying the weights of the larger model's corresponding layers. This allows the smaller model to quickly learn the general structure and representations of the larger model, providing a strong starting point for further optimization.
-
Low-Rank Adaptation: After the weight copy, the researchers adapt the smaller model's parameters using a low-rank matrix factorization approach. This fine-tunes the smaller model to the specific task at hand, allowing it to capture the nuances of the dataset and achieve high performance.
The combination of weight copy and low-rank adaptation enables the smaller model to achieve strong performance with only a small amount of fine-tuning, making it much more efficient than training the smaller model from scratch.
The researchers evaluate their method on several benchmark datasets, including ImageNet, CIFAR-100, and Pascal VOC. They compare their approach to various existing knowledge distillation techniques and show that it outperforms them, particularly in few-shot settings.
Critical Analysis
The paper presents a novel and promising approach to few-shot distillation of vision transformers. The researchers have demonstrated the effectiveness of their method on several benchmark datasets, which is a strength of the work.
However, the paper does not address some potential limitations or areas for further research. For example, it would be interesting to see how the method performs on more diverse or challenging datasets, or how it compares to other state-of-the-art few-shot learning techniques beyond knowledge distillation.
Additionally, the paper does not provide a detailed analysis of the computational efficiency of the smaller models produced by the weight copy and low-rank adaptation approach. While the researchers claim that their method is more efficient than training the smaller model from scratch, a more thorough evaluation of the model size, inference time, and energy consumption would be valuable for understanding the practical implications of the technique.
Mixture of Low-Rank Experts is another related approach that could be interesting to compare against or potentially combine with the techniques presented in this paper.
Overall, the paper makes a significant contribution to the field of few-shot learning and knowledge distillation for vision transformers. The proposed method shows promise, but further research and analysis could help to fully understand its strengths, limitations, and potential for real-world applications.
Conclusion
This paper introduces a novel method for few-shot distillation of vision transformers, leveraging the key ideas of "weight copy" and "low-rank adaptation" to efficiently transfer knowledge from a large, pre-trained model to a smaller, more efficient model.
The experimental results demonstrate the effectiveness of the proposed approach, which outperforms existing knowledge distillation techniques, particularly in few-shot settings. This is an important breakthrough, as it paves the way for deploying high-performing computer vision models in resource-constrained environments, such as edge devices and mobile applications.
While the paper presents a promising solution, further research is needed to fully understand the method's limitations and explore potential extensions or combinations with other state-of-the-art few-shot learning techniques. Nonetheless, this work represents a significant contribution to the field and has the potential to drive important advances in the deployment of efficient and accurate AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Few-Shot Class Incremental Learning via Robust Transformer Approach
Naeem Paeedeh, Mahardhika Pratama, Sunu Wibirama, Wolfgang Mayer, Zehong Cao, Ryszard Kowalczyk
0
0
Few-Shot Class-Incremental Learning presents an extension of the Class Incremental Learning problem where a model is faced with the problem of data scarcity while addressing the catastrophic forgetting problem. This problem remains an open problem because all recent works are built upon the convolutional neural networks performing sub-optimally compared to the transformer approaches. Our paper presents Robust Transformer Approach built upon the Compact Convolution Transformer. The issue of overfitting due to few samples is overcome with the notion of the stochastic classifier, where the classifier's weights are sampled from a distribution with mean and variance vectors, thus increasing the likelihood of correct classifications, and the batch-norm layer to stabilize the training process. The issue of CF is dealt with the idea of delta parameters, small task-specific trainable parameters while keeping the backbone networks frozen. A non-parametric approach is developed to infer the delta parameters for the model's predictions. The prototype rectification approach is applied to avoid biased prototype calculations due to the issue of data scarcity. The advantage of ROBUSTA is demonstrated through a series of experiments in the benchmark problems where it is capable of outperforming prior arts with big margins without any data augmentation protocols.
5/13/2024
✨
Knowledge Distillation via the Target-aware Transformer
Sihao Lin, Hongwei Xie, Bing Wang, Kaicheng Yu, Xiaojun Chang, Xiaodan Liang, Gang Wang
0
0
Knowledge distillation becomes a de facto standard to improve the performance of small neural networks. Most of the previous works propose to regress the representational features from the teacher to the student in a one-to-one spatial matching fashion. However, people tend to overlook the fact that, due to the architecture differences, the semantic information on the same spatial location usually vary. This greatly undermines the underlying assumption of the one-to-one distillation approach. To this end, we propose a novel one-to-all spatial matching knowledge distillation approach. Specifically, we allow each pixel of the teacher feature to be distilled to all spatial locations of the student features given its similarity, which is generated from a target-aware transformer. Our approach surpasses the state-of-the-art methods by a significant margin on various computer vision benchmarks, such as ImageNet, Pascal VOC and COCOStuff10k. Code is available at https://github.com/sihaoevery/TaT.
4/9/2024
Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
Weihao Jiang, Chang Liu, Kun He
0
0
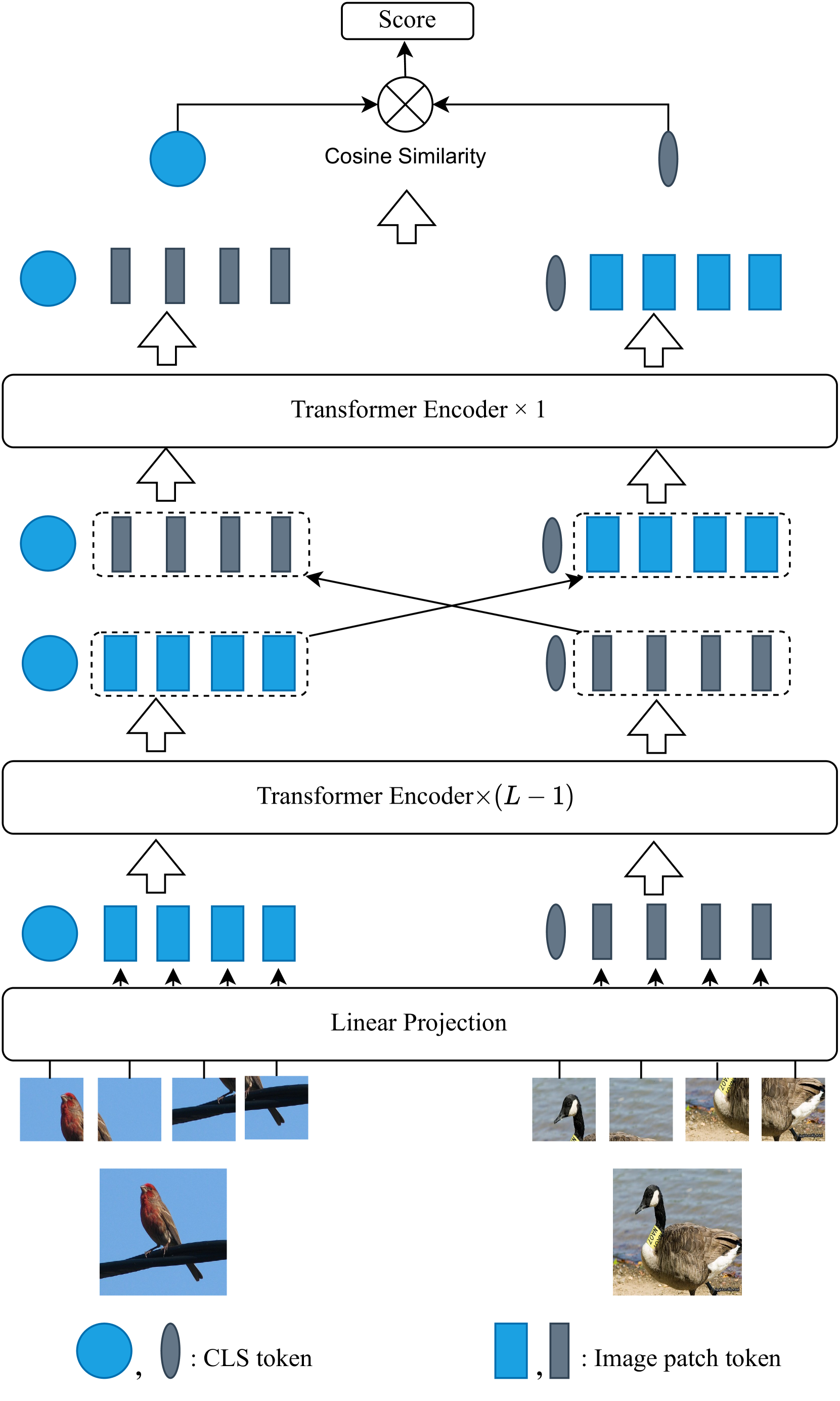
Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios
5/7/2024

Pre-trained Vision and Language Transformers Are Few-Shot Incremental Learners
Keon-Hee Park, Kyungwoo Song, Gyeong-Moon Park
0
0
Few-Shot Class Incremental Learning (FSCIL) is a task that requires a model to learn new classes incrementally without forgetting when only a few samples for each class are given. FSCIL encounters two significant challenges: catastrophic forgetting and overfitting, and these challenges have driven prior studies to primarily rely on shallow models, such as ResNet-18. Even though their limited capacity can mitigate both forgetting and overfitting issues, it leads to inadequate knowledge transfer during few-shot incremental sessions. In this paper, we argue that large models such as vision and language transformers pre-trained on large datasets can be excellent few-shot incremental learners. To this end, we propose a novel FSCIL framework called PriViLege, Pre-trained Vision and Language transformers with prompting functions and knowledge distillation. Our framework effectively addresses the challenges of catastrophic forgetting and overfitting in large models through new pre-trained knowledge tuning (PKT) and two losses: entropy-based divergence loss and semantic knowledge distillation loss. Experimental results show that the proposed PriViLege significantly outperforms the existing state-of-the-art methods with a large margin, e.g., +9.38% in CUB200, +20.58% in CIFAR-100, and +13.36% in miniImageNet. Our implementation code is available at https://github.com/KHU-AGI/PriViLege.
4/3/2024