A Comprehensive Review of Knowledge Distillation in Computer Vision
2404.00936
0
0
👀
Abstract
Deep learning techniques have been demonstrated to surpass preceding cutting-edge machine learning techniques in recent years, with computer vision being one of the most prominent examples. However, deep learning models suffer from significant drawbacks when deployed in resource-constrained environments due to their large model size and high complexity. Knowledge Distillation is one of the prominent solutions to overcome this challenge. This review paper examines the current state of research on knowledge distillation, a technique for compressing complex models into smaller and simpler ones. The paper provides an overview of the major principles and techniques associated with knowledge distillation and reviews the applications of knowledge distillation in the domain of computer vision. The review focuses on the benefits of knowledge distillation, as well as the problems that must be overcome to improve its effectiveness.
Create account to get full access
Overview
- Deep learning models have surpassed previous state-of-the-art machine learning techniques in many domains, especially computer vision.
- However, deep learning models are large and complex, making them challenging to deploy in resource-constrained environments.
- Knowledge Distillation is a technique for compressing complex deep learning models into smaller, simpler models.
Plain English Explanation
Deep learning is a powerful type of artificial intelligence that has achieved remarkable results in tasks like image recognition and object detection. These deep learning models are very sophisticated, with many interconnected layers that allow them to learn complex patterns in data. However, this complexity comes at a cost - deep learning models tend to be large and computationally intensive, making them difficult to run on devices with limited resources, like smartphones or embedded systems.
Knowledge Distillation is a technique that aims to address this problem. The idea is to take a large, complex deep learning model that has been trained to perform well on a task, and use it to train a smaller, simpler model to do the same task. The smaller model learns from the knowledge "distilled" from the larger model, allowing it to achieve similar performance but with much lower computational requirements.
Imagine you have an expert chef who can create gourmet meals, but the recipes are very complex and require expensive equipment. Knowledge Distillation is like taking that expert chef's knowledge and techniques and teaching them to a less experienced cook, who can then make similar meals using more basic tools and ingredients. The end result may not be quite as refined, but it's much more practical for everyday use.
Technical Explanation
This review paper examines the current state of research on knowledge distillation, a technique for compressing complex deep learning models into smaller and simpler models. The paper provides an overview of the major principles and techniques associated with knowledge distillation, as well as a review of its applications in the domain of computer vision.
The key idea behind knowledge distillation is to use the outputs or internal representations of a large, high-performing "teacher" model to guide the training of a smaller "student" model. This allows the student model to learn the same knowledge as the teacher, but with a more compact and efficient architecture. Researchers have explored various strategies for effectively transferring knowledge from the teacher to the student, such as matching the output probabilities, mimicking the hidden layer activations, or aligning the gradients.
The review covers the benefits of knowledge distillation, such as reduced model size, lower computational requirements, and faster inference times, all while maintaining high task performance. However, the paper also discusses the challenges that must be overcome to improve the effectiveness of knowledge distillation, such as the difficulty of optimizing the student model to match the teacher's performance, and the potential loss of generalization capability.
Critical Analysis
The paper provides a comprehensive overview of knowledge distillation and its applications in computer vision, highlighting both the advantages and the limitations of the technique. The authors acknowledge that while knowledge distillation can effectively compress complex deep learning models, there are still difficulties in ensuring the student model fully captures the knowledge of the teacher, especially when it comes to maintaining the teacher's generalization ability.
One potential area for further research mentioned in the paper is the development of more sophisticated knowledge distillation techniques that can better preserve the nuances of the teacher's representations, rather than just matching the output probabilities or activations. Additionally, the paper suggests that exploring the use of knowledge distillation in domains beyond computer vision, such as natural language processing or reinforcement learning, could yield valuable insights.
While the paper provides a thorough review of the current state of knowledge distillation research, it would be useful to see the authors engage in a more critical analysis of the limitations and potential downsides of the technique. For example, the paper could have discussed the risk of the student model becoming overly reliant on the teacher, or the challenges of applying knowledge distillation to more complex, multi-task models.
Conclusion
This review paper offers a comprehensive overview of knowledge distillation, a promising technique for compressing large, complex deep learning models into smaller, more efficient models. By transferring the knowledge from a high-performing "teacher" model to a smaller "student" model, knowledge distillation can significantly reduce the computational and memory requirements of deep learning systems, making them more suitable for deployment in resource-constrained environments.
The paper highlights the key principles and techniques of knowledge distillation, as well as its successful application in the computer vision domain. While the technique has shown substantial benefits, the review also identifies areas for further research to address the remaining challenges, such as preserving the teacher's generalization capabilities and exploring the use of knowledge distillation in other domains.
Overall, this review provides a valuable resource for researchers and practitioners interested in leveraging the power of deep learning while overcoming the challenges of model complexity and resource constraints.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
DistilDoc: Knowledge Distillation for Visually-Rich Document Applications
Jordy Van Landeghem, Subhajit Maity, Ayan Banerjee, Matthew Blaschko, Marie-Francine Moens, Josep Llad'os, Sanket Biswas
0
0
This work explores knowledge distillation (KD) for visually-rich document (VRD) applications such as document layout analysis (DLA) and document image classification (DIC). While VRD research is dependent on increasingly sophisticated and cumbersome models, the field has neglected to study efficiency via model compression. Here, we design a KD experimentation methodology for more lean, performant models on document understanding (DU) tasks that are integral within larger task pipelines. We carefully selected KD strategies (response-based, feature-based) for distilling knowledge to and from backbones with different architectures (ResNet, ViT, DiT) and capacities (base, small, tiny). We study what affects the teacher-student knowledge gap and find that some methods (tuned vanilla KD, MSE, SimKD with an apt projector) can consistently outperform supervised student training. Furthermore, we design downstream task setups to evaluate covariate shift and the robustness of distilled DLA models on zero-shot layout-aware document visual question answering (DocVQA). DLA-KD experiments result in a large mAP knowledge gap, which unpredictably translates to downstream robustness, accentuating the need to further explore how to efficiently obtain more semantic document layout awareness.
6/13/2024
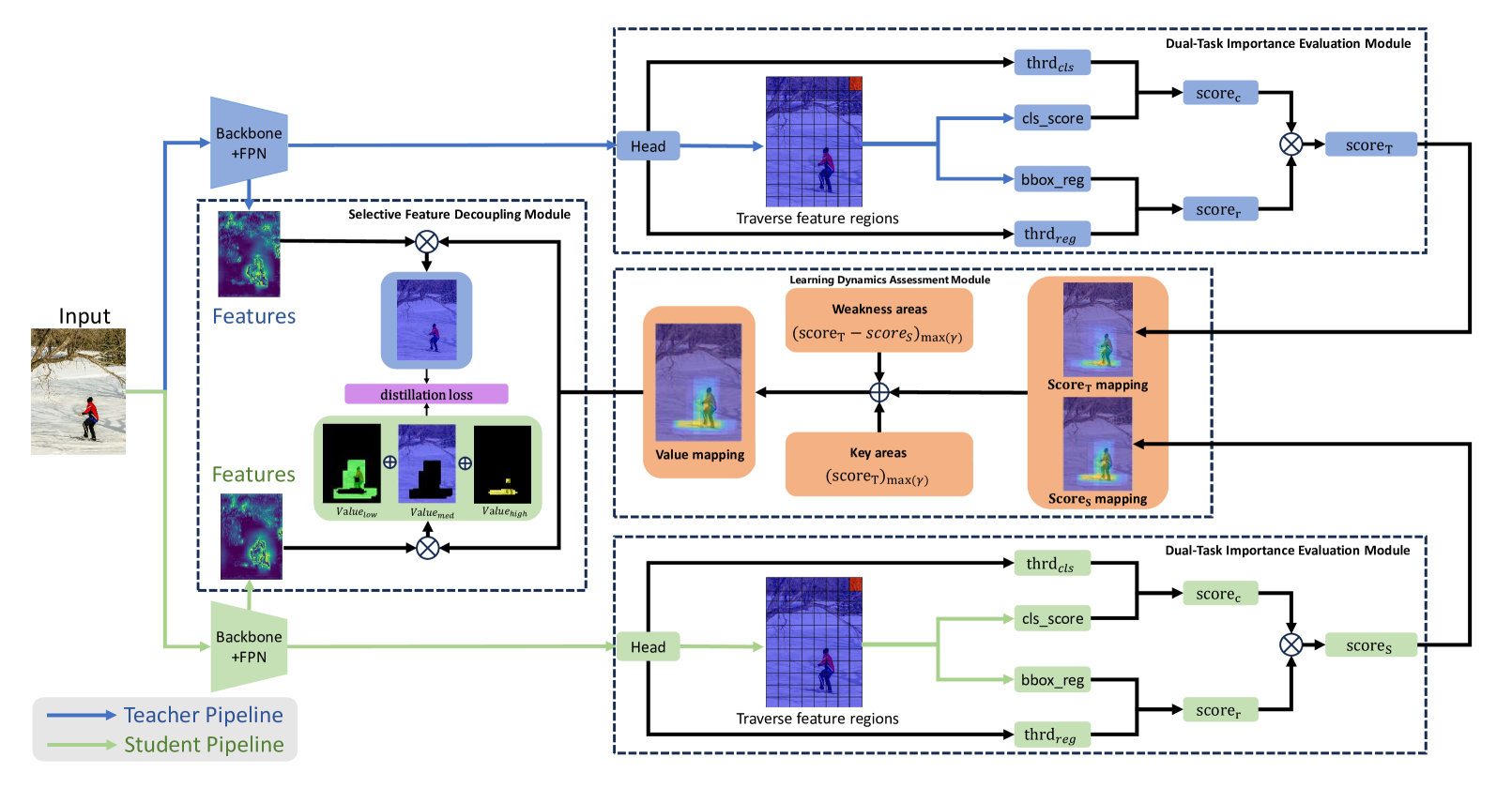
Task Integration Distillation for Object Detectors
Hai Su, ZhenWen Jian, Songsen Yu
0
0
Knowledge distillation is a widely adopted technique for model lightening. However, the performance of most knowledge distillation methods in the domain of object detection is not satisfactory. Typically, knowledge distillation approaches consider only the classification task among the two sub-tasks of an object detector, largely overlooking the regression task. This oversight leads to a partial understanding of the object detector's comprehensive task, resulting in skewed estimations and potentially adverse effects. Therefore, we propose a knowledge distillation method that addresses both the classification and regression tasks, incorporating a task significance strategy. By evaluating the importance of features based on the output of the detector's two sub-tasks, our approach ensures a balanced consideration of both classification and regression tasks in object detection. Drawing inspiration from real-world teaching processes and the definition of learning condition, we introduce a method that focuses on both key and weak areas. By assessing the value of features for knowledge distillation based on their importance differences, we accurately capture the current model's learning situation. This method effectively prevents the issue of biased predictions about the model's learning reality caused by an incomplete utilization of the detector's outputs.
4/3/2024
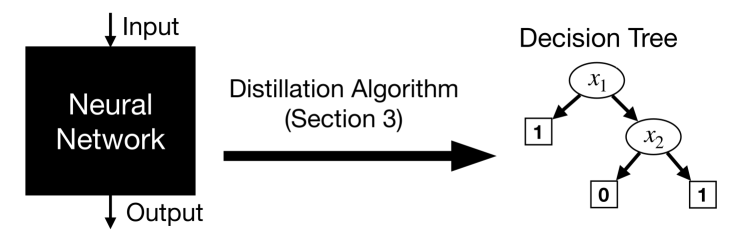
Towards a theory of model distillation
Enric Boix-Adsera
0
0
Distillation is the task of replacing a complicated machine learning model with a simpler model that approximates the original [BCNM06,HVD15]. Despite many practical applications, basic questions about the extent to which models can be distilled, and the runtime and amount of data needed to distill, remain largely open. To study these questions, we initiate a general theory of distillation, defining PAC-distillation in an analogous way to PAC-learning [Val84]. As applications of this theory: (1) we propose new algorithms to extract the knowledge stored in the trained weights of neural networks -- we show how to efficiently distill neural networks into succinct, explicit decision tree representations when possible by using the ``linear representation hypothesis''; and (2) we prove that distillation can be much cheaper than learning from scratch, and make progress on characterizing its complexity.
5/7/2024
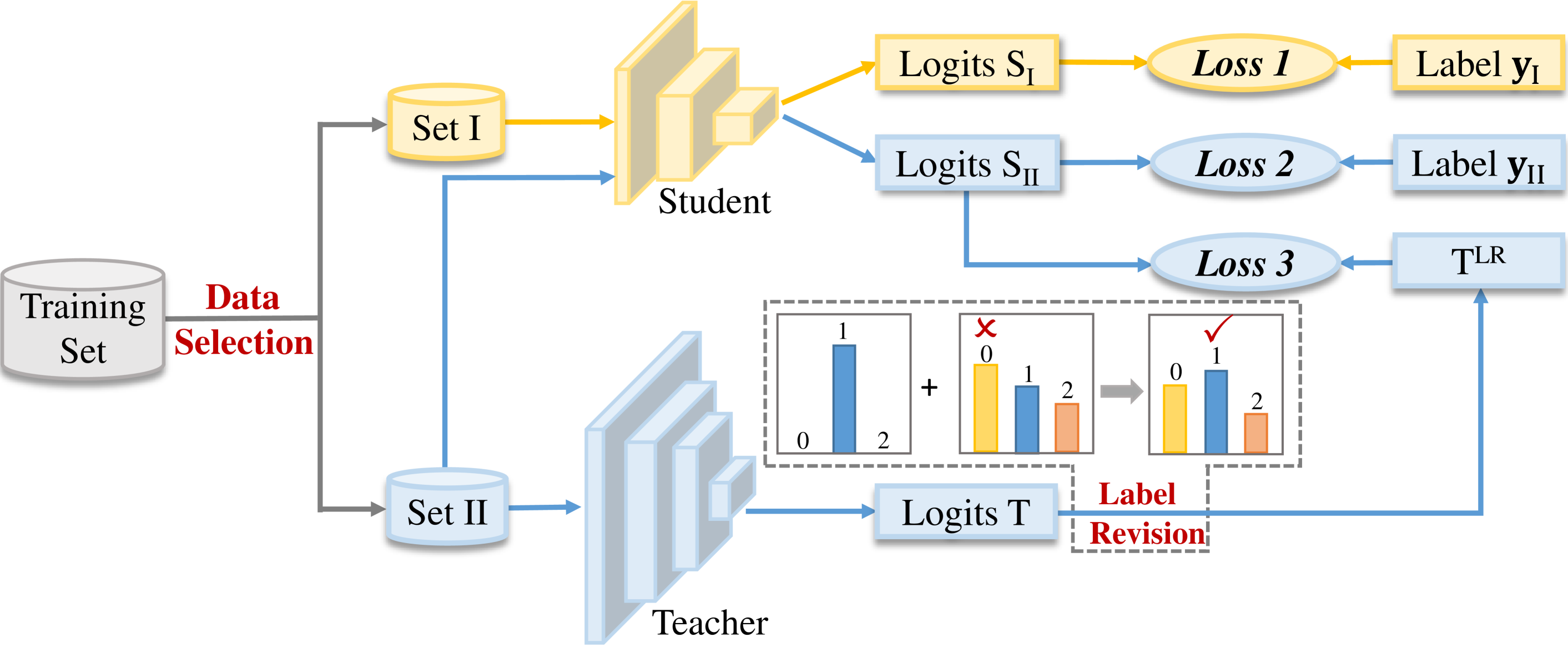
Improve Knowledge Distillation via Label Revision and Data Selection
Weichao Lan, Yiu-ming Cheung, Qing Xu, Buhua Liu, Zhikai Hu, Mengke Li, Zhenghua Chen
0
0
Knowledge distillation (KD) has become a widely used technique in the field of model compression, which aims to transfer knowledge from a large teacher model to a lightweight student model for efficient network development. In addition to the supervision of ground truth, the vanilla KD method regards the predictions of the teacher as soft labels to supervise the training of the student model. Based on vanilla KD, various approaches have been developed to further improve the performance of the student model. However, few of these previous methods have considered the reliability of the supervision from teacher models. Supervision from erroneous predictions may mislead the training of the student model. This paper therefore proposes to tackle this problem from two aspects: Label Revision to rectify the incorrect supervision and Data Selection to select appropriate samples for distillation to reduce the impact of erroneous supervision. In the former, we propose to rectify the teacher's inaccurate predictions using the ground truth. In the latter, we introduce a data selection technique to choose suitable training samples to be supervised by the teacher, thereby reducing the impact of incorrect predictions to some extent. Experiment results demonstrate the effectiveness of our proposed method, and show that our method can be combined with other distillation approaches, improving their performance.
4/8/2024