Analysis of Self-Supervised Speech Models on Children's Speech and Infant Vocalizations

0

Sign in to get full access
Overview
- This research paper analyzes the performance of self-supervised speech models on children's speech and infant vocalizations.
- The study evaluates how well these models can recognize phonemes (basic speech sounds) in children's and infant speech data.
- The researchers also explore ways to enhance the models' performance on these specialized speech types.
Plain English Explanation
Self-supervised speech models are AI systems that can learn to understand and process speech without being explicitly trained on large labeled datasets. This research aims to see how well these models work when analyzing the speech of children and infants, which can be quite different from adult speech.
Children and infants have unique speech patterns - their voices are higher-pitched, they make different sounds, and their language skills are still developing. So standard speech recognition models may struggle with this kind of data. The researchers wanted to test how well self-supervised models can handle these challenges and identify the basic units of speech (phonemes) in child and infant vocalizations.
They also investigated ways to enhance the models' performance on this specialized speech data, such as by fine-tuning the models or incorporating additional phonetic information. The goal is to make these self-supervised models more effective at processing the speech of young children and infants, which could have applications in areas like language learning and early childhood development.
Technical Explanation
The researchers first assessed the baseline phoneme recognition performance of several popular self-supervised speech models (e.g. WavLM, [XLSR-Wav2Vec2]) on datasets of children's speech and infant vocalizations. They found that the models struggled compared to their performance on adult speech, struggling to accurately identify the basic speech sounds.
To address this, the researchers explored techniques to boost the models' performance on the child/infant data. This included fine-tuning the models on the specialized data, as well as incorporating additional phonetic features and information to help the models better recognize the unique qualities of young speakers' voices.
Through their experiments, the researchers gained insights into the strengths and limitations of current self-supervised speech models when it comes to processing non-adult speech. They also identified promising directions for enhancing these models to make them more effective at analyzing children's and infants' vocalizations.
Critical Analysis
The study provides a valuable assessment of self-supervised speech models on an important but underexplored domain - the speech of young children and infants. The researchers acknowledge the limitations of the current models and offer constructive suggestions for improving their performance on this specialized data.
However, the paper could have delved deeper into potential reasons why the models struggled, such as the inherent acoustic differences between adult and child/infant speech, or the lack of diversity in the training data used to develop the self-supervised models. Additionally, the scope of the experiments was relatively narrow, focusing only on phoneme recognition rather than other speech processing tasks.
Further research could investigate how these self-supervised models handle other aspects of child and infant vocalizations, such as emotion recognition, speaker identification, or language development tracking. Exploring a wider range of downstream applications would provide a more comprehensive understanding of the models' capabilities and limitations in this domain.
Conclusion
This research paper takes an important step in evaluating the suitability of self-supervised speech models for processing the unique speech patterns of children and infants. While the current models face challenges in this domain, the study identifies promising directions for enhancing their performance through techniques like fine-tuning and incorporating phonetic information.
Improving the ability of self-supervised speech models to handle young children's and infants' vocalizations could have significant implications for applications in early childhood education, language learning, and developmental monitoring. The insights from this work provide a foundation for further research and development to make these AI systems more effective at understanding the speech of our youngest communicators.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Analysis of Self-Supervised Speech Models on Children's Speech and Infant Vocalizations
Jialu Li, Mark Hasegawa-Johnson, Nancy L. McElwain
To understand why self-supervised learning (SSL) models have empirically achieved strong performances on several speech-processing downstream tasks, numerous studies have focused on analyzing the encoded information of the SSL layer representations in adult speech. Limited work has investigated how pre-training and fine-tuning affect SSL models encoding children's speech and vocalizations. In this study, we aim to bridge this gap by probing SSL models on two relevant downstream tasks: (1) phoneme recognition (PR) on the speech of adults, older children (8-10 years old), and younger children (1-4 years old), and (2) vocalization classification (VC) distinguishing cry, fuss, and babble for infants under 14 months old. For younger children's PR, the superiority of fine-tuned SSL models is largely due to their ability to learn features that represent older children's speech and then adapt those features to the speech of younger children. For infant VC, SSL models pre-trained on large-scale home recordings learn to leverage phonetic representations at middle layers, and thereby enhance the performance of this task.
Read more6/7/2024
0
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
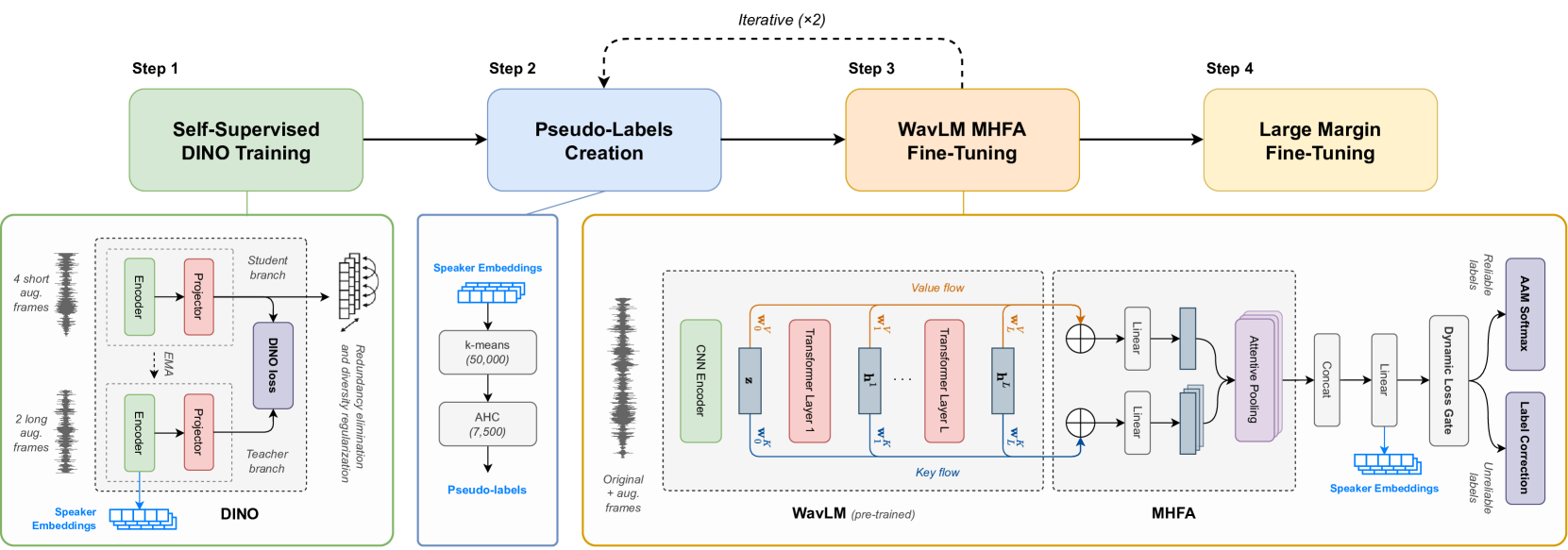
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
Read more6/5/2024
🗣️
0
On the social bias of speech self-supervised models
Yi-Cheng Lin, Tzu-Quan Lin, Hsi-Che Lin, Andy T. Liu, Hung-yi Lee
Self-supervised learning (SSL) speech models have achieved remarkable performance in various tasks, yet the biased outcomes, especially affecting marginalized groups, raise significant concerns. Social bias refers to the phenomenon where algorithms potentially amplify disparate properties between social groups present in the data used for training. Bias in SSL models can perpetuate injustice by automating discriminatory patterns and reinforcing inequitable systems. This work reveals that prevalent SSL models inadvertently acquire biased associations. We probe how various factors, such as model architecture, size, and training methodologies, influence the propagation of social bias within these models. Finally, we explore the efficacy of debiasing SSL models through regularization techniques, specifically via model compression. Our findings reveal that employing techniques such as row-pruning and training wider, shallower models can effectively mitigate social bias within SSL model.
Read more6/10/2024
🏷️
0
Enhancing Child Vocalization Classification with Phonetically-Tuned Embeddings for Assisting Autism Diagnosis
Jialu Li, Mark Hasegawa-Johnson, Karrie Karahalios
The assessment of children at risk of autism typically involves a clinician observing, taking notes, and rating children's behaviors. A machine learning model that can label adult and child audio may largely save labor in coding children's behaviors, helping clinicians capture critical events and better communicate with parents. In this study, we leverage Wav2Vec 2.0 (W2V2), pre-trained on 4300-hour of home audio of children under 5 years old, to build a unified system for tasks of clinician-child speaker diarization and vocalization classification (VC). To enhance children's VC, we build a W2V2 phoneme recognition system for children under 4 years old, and we incorporate its phonetically-tuned embeddings as auxiliary features or recognize pseudo phonetic transcripts as an auxiliary task. We test our method on two corpora (Rapid-ABC and BabbleCor) and obtain consistent improvements. Additionally, we outperform the state-of-the-art performance on the reproducible subset of BabbleCor. Code available at https://huggingface.co/lijialudew
Read more6/7/2024