An Analysis of Sentential Neighbors in Implicit Discourse Relation Prediction

0
Sign in to get full access
Overview
- This paper explores the use of sentential neighbors, or the sentences immediately before and after a given sentence, to improve the prediction of implicit discourse relations in text.
- Implicit discourse relations are connections between sentences that are not explicitly stated, such as causal, contrastive, or temporal relationships.
- The researchers investigate whether incorporating information from sentential neighbors can enhance the performance of machine learning models for predicting these implicit discourse relations.
Plain English Explanation
When we read text, we often understand the connections between sentences even when they are not directly stated. For example, if one sentence says "It was raining outside," and the next sentence says "I decided to stay in," we can infer a causal relationship - the rain led to the decision to stay inside. These implicit connections between sentences are known as
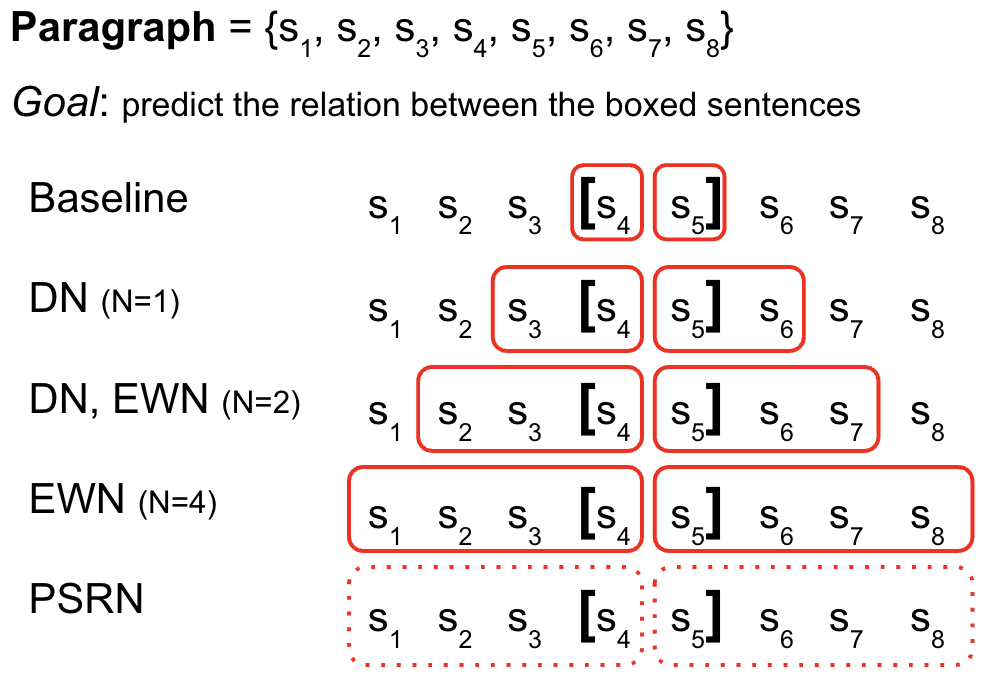
Predicting these implicit discourse relations is a challenging task for machines, as it requires understanding the context and semantics of the text. In this paper, the researchers explore whether incorporating information from the sentences immediately before and after a given sentence (known as
The key idea is that the context provided by the neighboring sentences might contain valuable clues about the relationship between the current sentence and the surrounding text. By taking this additional information into account, the models may be better able to capture the nuances of the discourse and make more accurate predictions.
Technical Explanation
The researchers conducted experiments on several benchmark datasets for implicit discourse relation prediction, including the Penn Discourse Treebank (PDTB) and the [Chinese Discourse Treebank (CDTB)]. They compared the performance of various machine learning models, including Convolutional Neural Networks (CNNs) and Transformer-based models, with and without incorporating information from the sentential neighbors.
The results showed that the models that leveraged the sentential neighbor information consistently outperformed the baseline models that only used the current sentence. This suggests that the context provided by the neighboring sentences can indeed be a valuable signal for predicting implicit discourse relations.
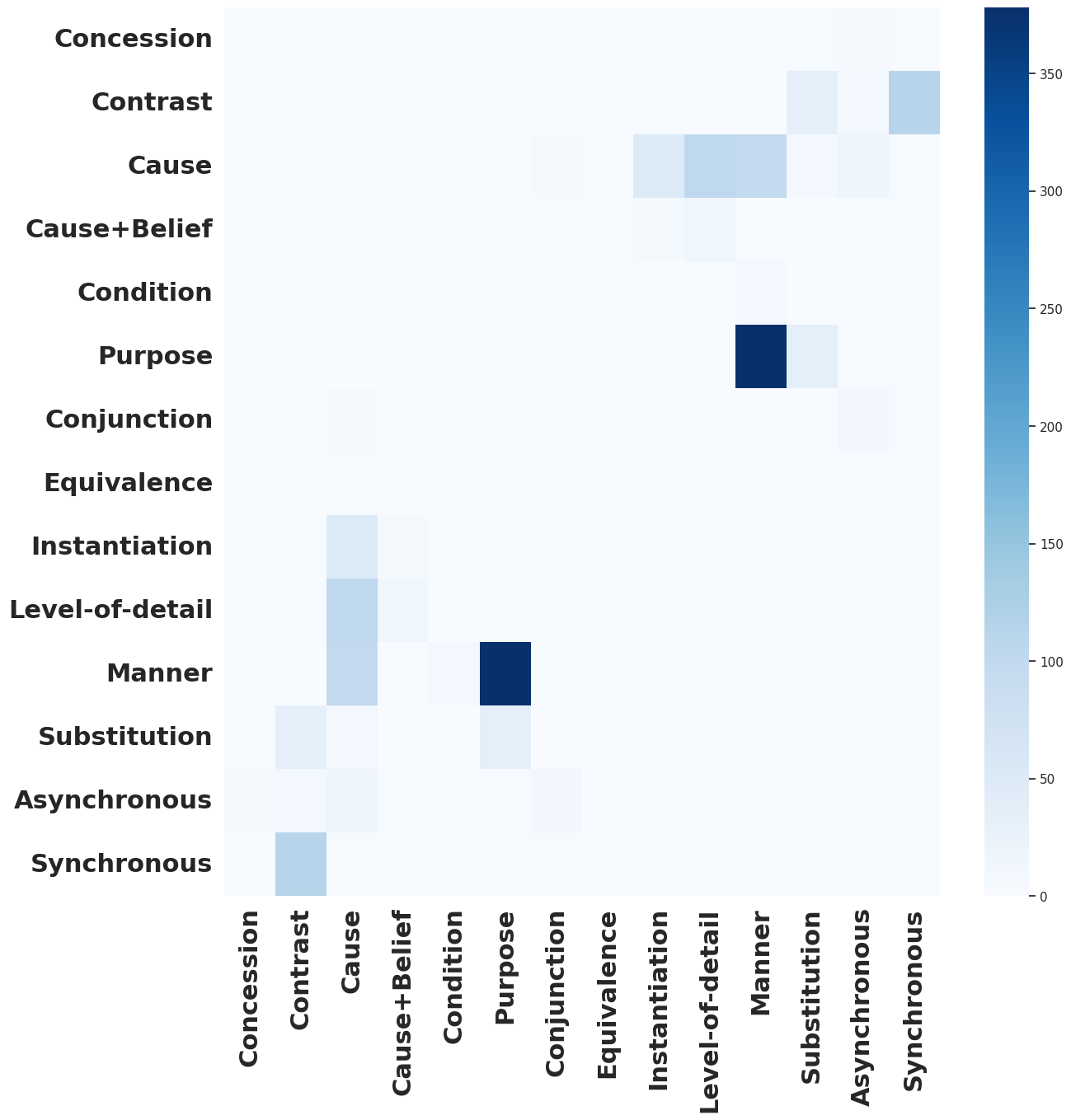
The researchers also analyzed the types of discourse relations where the sentential neighbor information was most helpful. They found that the approach was particularly effective for relations like Cause, Contrast, and Temporal, where the surrounding context is crucial for understanding the connection between sentences.
Critical Analysis
The paper provides a thorough and well-designed study on the use of sentential neighbors for implicit discourse relation prediction. The researchers have carefully selected their datasets, models, and evaluation metrics to ensure the validity and reliability of their findings.
One potential limitation of the study is that it focuses primarily on Western and Chinese languages, and the generalizability of the results to other languages and domains remains to be explored. Additionally, the paper does not delve into the specific mechanisms by which the sentential neighbor information improves the model performance, which could be a valuable area for further investigation.
Further research could explore the potential synergies between the sentential neighbor approach and other techniques for discourse relation prediction, such as analogous instance leveraging or relation-aware models. This could lead to more robust and comprehensive solutions for this challenging natural language processing task.
Conclusion
This paper presents a compelling case for the importance of sentential neighbors in predicting implicit discourse relations. By incorporating information from the sentences immediately before and after a given sentence, the researchers have demonstrated significant improvements in the performance of machine learning models for this task.
The findings have important implications for the development of more advanced natural language understanding systems, which often rely on accurately capturing the discourse-level structure of text. By leveraging the context provided by sentential neighbors, these systems may be better equipped to infer the intended meaning and relationships between sentences, leading to more accurate and nuanced language processing capabilities.
Overall, this research represents an important step forward in the field of implicit discourse relation prediction, offering a promising approach to enhance the capabilities of language models and unlock new possibilities in natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Analysis of Sentential Neighbors in Implicit Discourse Relation Prediction
Evi Judge, Reece Suchocki, Konner Syed
Discourse relation classification is an especially difficult task without explicit context markers (Prasad et al., 2008). Current approaches to implicit relation prediction solely rely on two neighboring sentences being targeted, ignoring the broader context of their surrounding environments (Atwell et al., 2021). In this research, we propose three new methods in which to incorporate context in the task of sentence relation prediction: (1) Direct Neighbors (DNs), (2) Expanded Window Neighbors (EWNs), and (3) Part-Smart Random Neighbors (PSRNs). Our findings indicate that the inclusion of context beyond one discourse unit is harmful in the task of discourse relation classification.
Read more5/20/2024
0
Multi-Label Classification for Implicit Discourse Relation Recognition
Wanqiu Long, N. Siddharth, Bonnie Webber
Discourse relations play a pivotal role in establishing coherence within textual content, uniting sentences and clauses into a cohesive narrative. The Penn Discourse Treebank (PDTB) stands as one of the most extensively utilized datasets in this domain. In PDTB-3, the annotators can assign multiple labels to an example, when they believe that multiple relations are present. Prior research in discourse relation recognition has treated these instances as separate examples during training, and only one example needs to have its label predicted correctly for the instance to be judged as correct. However, this approach is inadequate, as it fails to account for the interdependence of labels in real-world contexts and to distinguish between cases where only one sense relation holds and cases where multiple relations hold simultaneously. In our work, we address this challenge by exploring various multi-label classification frameworks to handle implicit discourse relation recognition. We show that multi-label classification methods don't depress performance for single-label prediction. Additionally, we give comprehensive analysis of results and data. Our work contributes to advancing the understanding and application of discourse relations and provide a foundation for the future study
Read more6/10/2024

0
Sentence-level Media Bias Analysis with Event Relation Graph
Yuanyuan Lei, Ruihong Huang
Media outlets are becoming more partisan and polarized nowadays. In this paper, we identify media bias at the sentence level, and pinpoint bias sentences that intend to sway readers' opinions. As bias sentences are often expressed in a neutral and factual way, considering broader context outside a sentence can help reveal the bias. In particular, we observe that events in a bias sentence need to be understood in associations with other events in the document. Therefore, we propose to construct an event relation graph to explicitly reason about event-event relations for sentence-level bias identification. The designed event relation graph consists of events as nodes and four common types of event relations: coreference, temporal, causal, and subevent relations. Then, we incorporate event relation graph for bias sentences identification in two steps: an event-aware language model is built to inject the events and event relations knowledge into the basic language model via soft labels; further, a relation-aware graph attention network is designed to update sentence embedding with events and event relations information based on hard labels. Experiments on two benchmark datasets demonstrate that our approach with the aid of event relation graph improves both precision and recall of bias sentence identification.
Read more4/3/2024

0
Implicit Discourse Relation Classification For Nigerian Pidgin
Muhammed Saeed, Peter Bourgonje, Vera Demberg
Despite attempts to make Large Language Models multi-lingual, many of the world's languages are still severely under-resourced. This widens the performance gap between NLP and AI applications aimed at well-financed, and those aimed at less-resourced languages. In this paper, we focus on Nigerian Pidgin (NP), which is spoken by nearly 100 million people, but has comparatively very few NLP resources and corpora. We address the task of Implicit Discourse Relation Classification (IDRC) and systematically compare an approach translating NP data to English and then using a well-resourced IDRC tool and back-projecting the labels versus creating a synthetic discourse corpus for NP, in which we translate PDTB and project PDTB labels, and then train an NP IDR classifier. The latter approach of learning a native NP classifier outperforms our baseline by 13.27% and 33.98% in f$_{1}$ score for 4-way and 11-way classification, respectively.
Read more6/28/2024