Analyzing the Benefits of Prototypes for Semi-Supervised Category Learning

0

Sign in to get full access
Overview
- This paper explores the benefits of using prototypes in semi-supervised category learning tasks.
- Prototypes are representative examples of a category that can help guide the learning process.
- The researchers investigate how prototypes can improve the performance of semi-supervised learning algorithms compared to fully supervised approaches.
Plain English Explanation
When we're learning to categorize things, like recognizing different types of animals or objects, prototypes can be really helpful. Prototypes are example items that are representative of a particular category. For example, a golden retriever could be a prototype for the "dog" category.
In semi-supervised learning, we have a mix of labeled and unlabeled data. The labeled data has category information, but the unlabeled data does not. Prototypes can provide guidance to the learning algorithm, helping it figure out how to categorize the unlabeled data based on the examples it has seen.
This paper looks at how using prototypes in semi-supervised learning can improve the performance compared to fully supervised approaches, where all the data is labeled. The key idea is that the prototypes give the algorithm a better understanding of what each category looks like, allowing it to more accurately categorize the unlabeled data and improve the overall learning process.
Technical Explanation
The paper presents several models for incorporating prototypes into semi-supervised category learning tasks. One approach, called Mixed Prototype Consistency Learning (MPCL), uses prototypes to encourage the model to make consistent predictions for both labeled and unlabeled data. Another model, Evidential Prototype Learning (EPL), uses prototypes to estimate the uncertainty in the model's predictions.
The researchers evaluate these prototype-based models on several benchmark datasets and compare their performance to fully supervised baselines. Their results show that incorporating prototypes can significantly improve the accuracy of semi-supervised category learning, especially when the amount of labeled data is limited.
The paper also discusses the probabilistic foundations underlying these prototype-based models and how they relate to other semi-supervised learning approaches, such as self-training and semantic-embedded similarity.
Critical Analysis
The paper provides a thorough investigation of how prototypes can benefit semi-supervised category learning, and the proposed models appear to be well-designed and effective. However, the researchers acknowledge that the performance of these models may depend on the quality and suitability of the chosen prototypes. In practice, finding or generating appropriate prototypes may be a challenging task, especially for complex or domain-specific applications.
Additionally, the paper does not explore the potential limitations of these prototype-based approaches, such as their sensitivity to outliers or the impact of prototype selection on model robustness. Further research may be needed to understand the broader applicability and limitations of these techniques in real-world scenarios.
Conclusion
This paper demonstrates the substantial benefits of incorporating prototypes into semi-supervised category learning models. By leveraging representative examples of each category, the proposed models can more effectively utilize both labeled and unlabeled data, leading to improved performance compared to fully supervised approaches.
The insights from this research could have important implications for a wide range of applications, from image recognition to medical diagnosis, where semi-supervised learning is often crucial due to the limited availability of labeled data. As the field of machine learning continues to advance, the strategic use of prototypes may become an increasingly important tool for enhancing the capabilities of semi-supervised systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Analyzing the Benefits of Prototypes for Semi-Supervised Category Learning
Liyi Zhang, Logan Nelson, Thomas L. Griffiths
Categories can be represented at different levels of abstraction, from prototypes focused on the most typical members to remembering all observed exemplars of the category. These representations have been explored in the context of supervised learning, where stimuli are presented with known category labels. We examine the benefits of prototype-based representations in a less-studied domain: semi-supervised learning, where agents must form unsupervised representations of stimuli before receiving category labels. We study this problem in a Bayesian unsupervised learning model called a variational auto-encoder, and we draw on recent advances in machine learning to implement a prior that encourages the model to use abstract prototypes to represent data. We apply this approach to image datasets and show that forming prototypes can improve semi-supervised category learning. Additionally, we study the latent embeddings of the models and show that these prototypes allow the models to form clustered representations without supervision, contributing to their success in downstream categorization performance.
Read more6/5/2024

0
Predefined Prototypes for Intra-Class Separation and Disentanglement
Antonio Almud'evar, Th'eo Mariotte, Alfonso Ortega, Marie Tahon, Luis Vicente, Antonio Miguel, Eduardo Lleida
Prototypical Learning is based on the idea that there is a point (which we call prototype) around which the embeddings of a class are clustered. It has shown promising results in scenarios with little labeled data or to design explainable models. Typically, prototypes are either defined as the average of the embeddings of a class or are designed to be trainable. In this work, we propose to predefine prototypes following human-specified criteria, which simplify the training pipeline and brings different advantages. Specifically, in this work we explore two of these advantages: increasing the inter-class separability of embeddings and disentangling embeddings with respect to different variance factors, which can translate into the possibility of having explainable predictions. Finally, we propose different experiments that help to understand our proposal and demonstrate empirically the mentioned advantages.
Read more6/26/2024
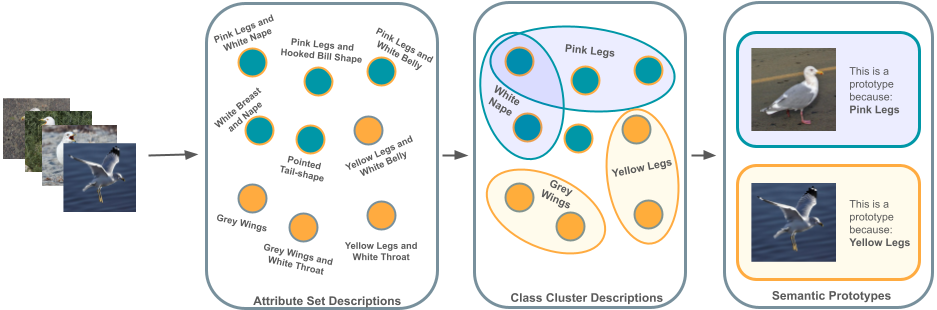
0
Semantic Prototypes: Enhancing Transparency Without Black Boxes
Orfeas Menis-Mastromichalakis, Giorgos Filandrianos, Jason Liartis, Edmund Dervakos, Giorgos Stamou
As machine learning (ML) models and datasets increase in complexity, the demand for methods that enhance explainability and interpretability becomes paramount. Prototypes, by encapsulating essential characteristics within data, offer insights that enable tactical decision-making and enhance transparency. Traditional prototype methods often rely on sub-symbolic raw data and opaque latent spaces, reducing explainability and increasing the risk of misinterpretations. This paper presents a novel framework that utilizes semantic descriptions to define prototypes and provide clear explanations, effectively addressing the shortcomings of conventional methods. Our approach leverages concept-based descriptions to cluster data on the semantic level, ensuring that prototypes not only represent underlying properties intuitively but are also straightforward to interpret. Our method simplifies the interpretative process and effectively bridges the gap between complex data structures and human cognitive processes, thereby enhancing transparency and fostering trust. Our approach outperforms existing widely-used prototype methods in facilitating human understanding and informativeness, as validated through a user survey.
Read more8/20/2024
🖼️
0
Mixture of Gaussian-distributed Prototypes with Generative Modelling for Interpretable and Trustworthy Image Recognition
Chong Wang, Yuanhong Chen, Fengbei Liu, Yuyuan Liu, Davis James McCarthy, Helen Frazer, Gustavo Carneiro
Prototypical-part methods, e.g., ProtoPNet, enhance interpretability in image recognition by linking predictions to training prototypes, thereby offering intuitive insights into their decision-making. Existing methods, which rely on a point-based learning of prototypes, typically face two critical issues: 1) the learned prototypes have limited representation power and are not suitable to detect Out-of-Distribution (OoD) inputs, reducing their decision trustworthiness; and 2) the necessary projection of the learned prototypes back into the space of training images causes a drastic degradation in the predictive performance. Furthermore, current prototype learning adopts an aggressive approach that considers only the most active object parts during training, while overlooking sub-salient object regions which still hold crucial classification information. In this paper, we present a new generative paradigm to learn prototype distributions, termed as Mixture of Gaussian-distributed Prototypes (MGProto). The distribution of prototypes from MGProto enables both interpretable image classification and trustworthy recognition of OoD inputs. The optimisation of MGProto naturally projects the learned prototype distributions back into the training image space, thereby addressing the performance degradation caused by prototype projection. Additionally, we develop a novel and effective prototype mining strategy that considers not only the most active but also sub-salient object parts. To promote model compactness, we further propose to prune MGProto by removing prototypes with low importance priors. Experiments on CUB-200-2011, Stanford Cars, Stanford Dogs, and Oxford-IIIT Pets datasets show that MGProto achieves state-of-the-art image recognition and OoD detection performances, while providing encouraging interpretability results.
Read more6/6/2024