Analyzing Feed-Forward Blocks in Transformers through the Lens of Attention Maps
2302.00456
0
0
📈
Abstract
Transformers are ubiquitous in wide tasks. Interpreting their internals is a pivotal goal. Nevertheless, their particular components, feed-forward (FF) blocks, have typically been less analyzed despite their substantial parameter amounts. We analyze the input contextualization effects of FF blocks by rendering them in the attention maps as a human-friendly visualization scheme. Our experiments with both masked- and causal-language models reveal that FF networks modify the input contextualization to emphasize specific types of linguistic compositions. In addition, FF and its surrounding components tend to cancel out each other's effects, suggesting potential redundancy in the processing of the Transformer layer.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Transformers are widely used in various AI tasks, but their internal components, such as feed-forward (FF) blocks, have received less attention despite their significant parameter counts.
- This research analyzes the input contextualization effects of FF blocks by visualizing them in attention maps, a human-friendly approach.
- The experiments with both masked- and causal-language models reveal that FF networks modify the input contextualization to emphasize specific types of linguistic compositions.
- The study also suggests that FF and its surrounding components tend to cancel out each other's effects, hinting at potential redundancy in the processing of the Transformer layer.
Plain English Explanation
Transformers are a type of artificial intelligence (AI) model that are used in a wide variety of tasks, such as natural language processing and computer vision. These models are made up of different components, including feed-forward (FF) blocks, which play a significant role in the model's performance.
In this research, the scientists wanted to better understand how the FF blocks in Transformers affect the way the model processes and understands the input information. They used a special visualization technique to "see" what the FF blocks are doing inside the model.
The researchers found that the FF blocks modify the way the Transformer model contextualizes, or understands, the input information. Specifically, the FF blocks seem to emphasize certain types of linguistic patterns or structures in the input data.
Additionally, the study suggests that the FF blocks and the other components in the Transformer layer tend to cancel out each other's effects. This could mean that there is some redundancy, or unnecessary duplication, in the way the Transformer layer processes the information.
Technical Explanation
The researchers analyzed the input contextualization effects of the feed-forward (FF) blocks in Transformer models by rendering them in attention maps, a visual representation that can be more easily interpreted by humans.
Their experiments were conducted on both masked-language models and causal-language models, which are two common types of Transformer-based language models. The results revealed that the FF networks modify the input contextualization, emphasizing specific linguistic compositions, such as particular grammatical structures or semantic relationships.
Moreover, the study found that the FF blocks and their surrounding components in the Transformer layer tend to cancel out each other's effects. This suggests a potential redundancy in the processing of the Transformer layer, where certain components may be duplicating or counteracting the work of others.
Critical Analysis
The paper provides a novel and insightful approach to analyzing the inner workings of Transformer models, which are widely used in various AI applications. By visualizing the input contextualization effects of the FF blocks, the researchers offer a more user-friendly way to interpret the complex dynamics within these models.
However, the study is limited to the specific architectural choices and experimental setups used in the research. It would be valuable to explore the generalizability of these findings across a broader range of Transformer model architectures and tasks.
Additionally, while the paper suggests potential redundancy in the Transformer layer, further investigation is needed to fully understand the implications and practical consequences of this observation. It may be worthwhile to explore whether such redundancy can be leveraged to improve model efficiency or interpretability.
Conclusion
This research offers a unique perspective on understanding the internal components of Transformer models, focusing on the feed-forward (FF) blocks and their role in input contextualization. The study's findings suggest that the FF blocks play a significant part in shaping the way Transformers process and comprehend input data, emphasizing specific linguistic patterns.
The potential redundancy observed in the Transformer layer raises questions about the optimal design and utilization of these powerful models. As Transformer-based architectures continue to advance and find widespread adoption, studies like this one can contribute to a deeper understanding of these models, paving the way for more efficient and interpretable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
TransformerFAM: Feedback attention is working memory
Dongseong Hwang, Weiran Wang, Zhuoyuan Huo, Khe Chai Sim, Pedro Moreno Mengibar
0
0
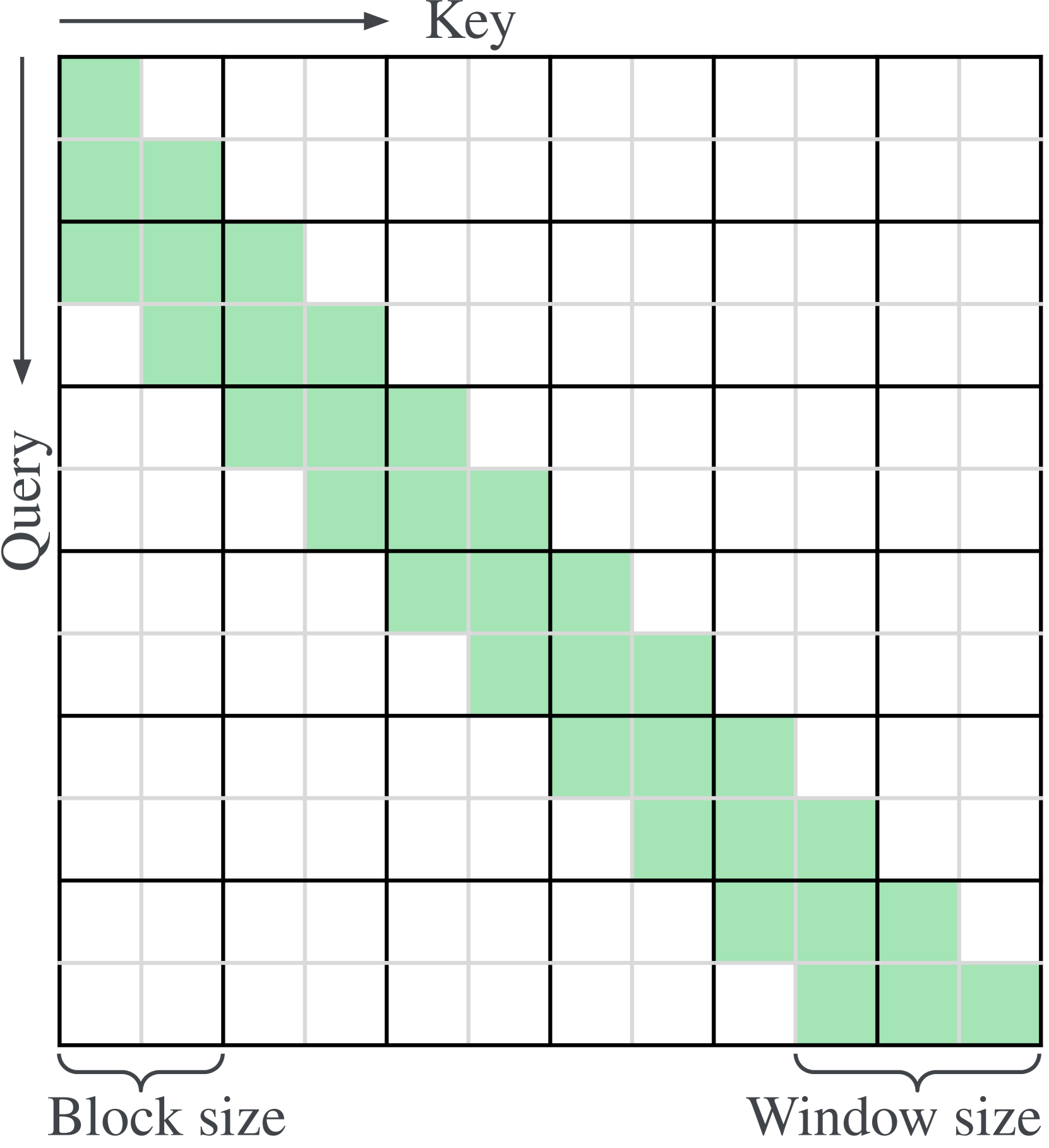
While Transformers have revolutionized deep learning, their quadratic attention complexity hinders their ability to process infinitely long inputs. We propose Feedback Attention Memory (FAM), a novel Transformer architecture that leverages a feedback loop to enable the network to attend to its own latent representations. This design fosters the emergence of working memory within the Transformer, allowing it to process indefinitely long sequences. TransformerFAM requires no additional weights, enabling seamless integration with pre-trained models. Our experiments show that TransformerFAM significantly improves Transformer performance on long-context tasks across various model sizes (1B, 8B, and 24B). These results showcase the potential to empower Large Language Models (LLMs) to process sequences of unlimited length.
5/8/2024
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
0
0
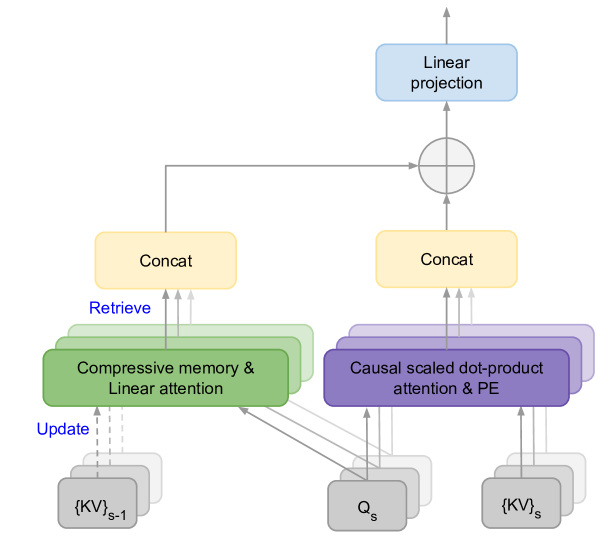
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
4/11/2024
Probing Large Language Models from A Human Behavioral Perspective
Xintong Wang, Xiaoyu Li, Xingshan Li, Chris Biemann
0
0
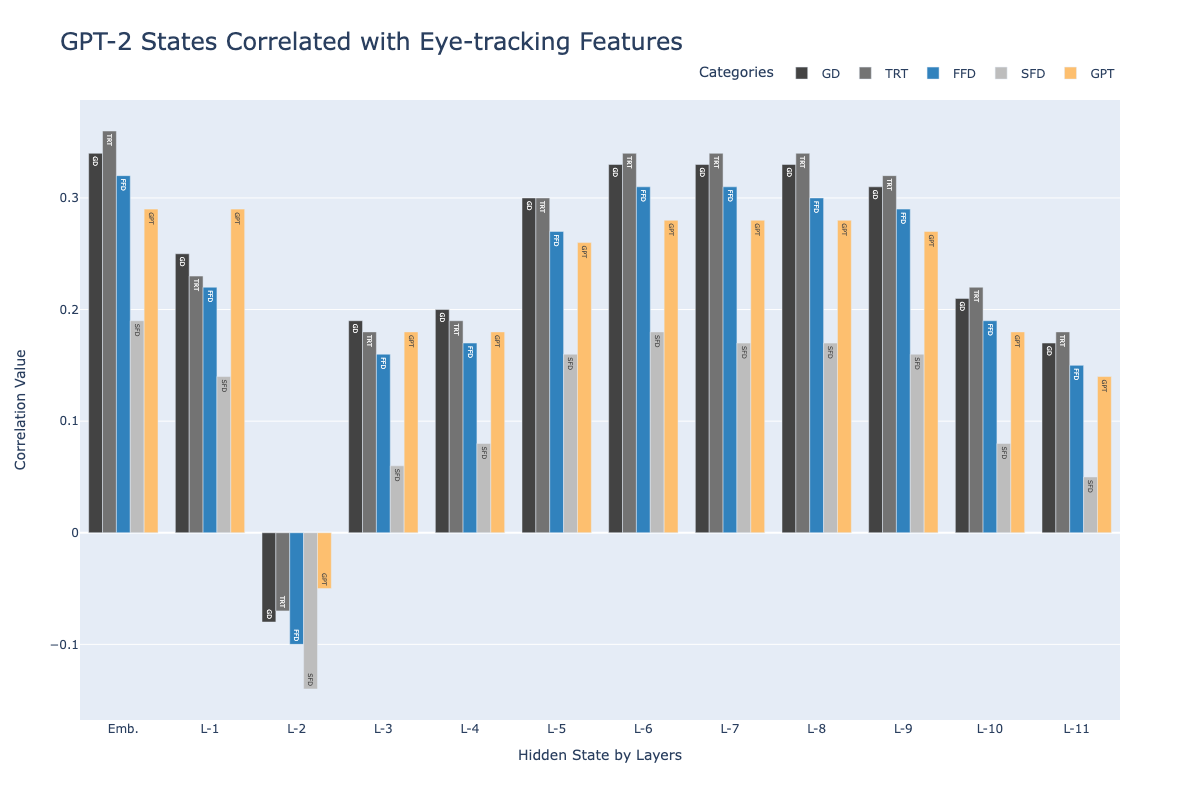
Large Language Models (LLMs) have emerged as dominant foundational models in modern NLP. However, the understanding of their prediction processes and internal mechanisms, such as feed-forward networks (FFN) and multi-head self-attention (MHSA), remains largely unexplored. In this work, we probe LLMs from a human behavioral perspective, correlating values from LLMs with eye-tracking measures, which are widely recognized as meaningful indicators of human reading patterns. Our findings reveal that LLMs exhibit a similar prediction pattern with humans but distinct from that of Shallow Language Models (SLMs). Moreover, with the escalation of LLM layers from the middle layers, the correlation coefficients also increase in FFN and MHSA, indicating that the logits within FFN increasingly encapsulate word semantics suitable for predicting tokens from the vocabulary.
4/16/2024
🚀
A Transformer with Stack Attention
Jiaoda Li, Jennifer C. White, Mrinmaya Sachan, Ryan Cotterell
0
0
Natural languages are believed to be (mildly) context-sensitive. Despite underpinning remarkably capable large language models, transformers are unable to model many context-free language tasks. In an attempt to address this limitation in the modeling power of transformer-based language models, we propose augmenting them with a differentiable, stack-based attention mechanism. Our stack-based attention mechanism can be incorporated into any transformer-based language model and adds a level of interpretability to the model. We show that the addition of our stack-based attention mechanism enables the transformer to model some, but not all, deterministic context-free languages.
5/15/2024