TransformerFAM: Feedback attention is working memory
2404.09173
4
100
Abstract
While Transformers have revolutionized deep learning, their quadratic attention complexity hinders their ability to process infinitely long inputs. We propose Feedback Attention Memory (FAM), a novel Transformer architecture that leverages a feedback loop to enable the network to attend to its own latent representations. This design fosters the emergence of working memory within the Transformer, allowing it to process indefinitely long sequences. TransformerFAM requires no additional weights, enabling seamless integration with pre-trained models. Our experiments show that TransformerFAM significantly improves Transformer performance on long-context tasks across various model sizes (1B, 8B, and 24B). These results showcase the potential to empower Large Language Models (LLMs) to process sequences of unlimited length.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Introduces TransformerFAM, a new architecture that integrates feedback attention into the transformer model
- Feedback attention is proposed as a way to leverage working memory and improve the model's ability to learn and reason
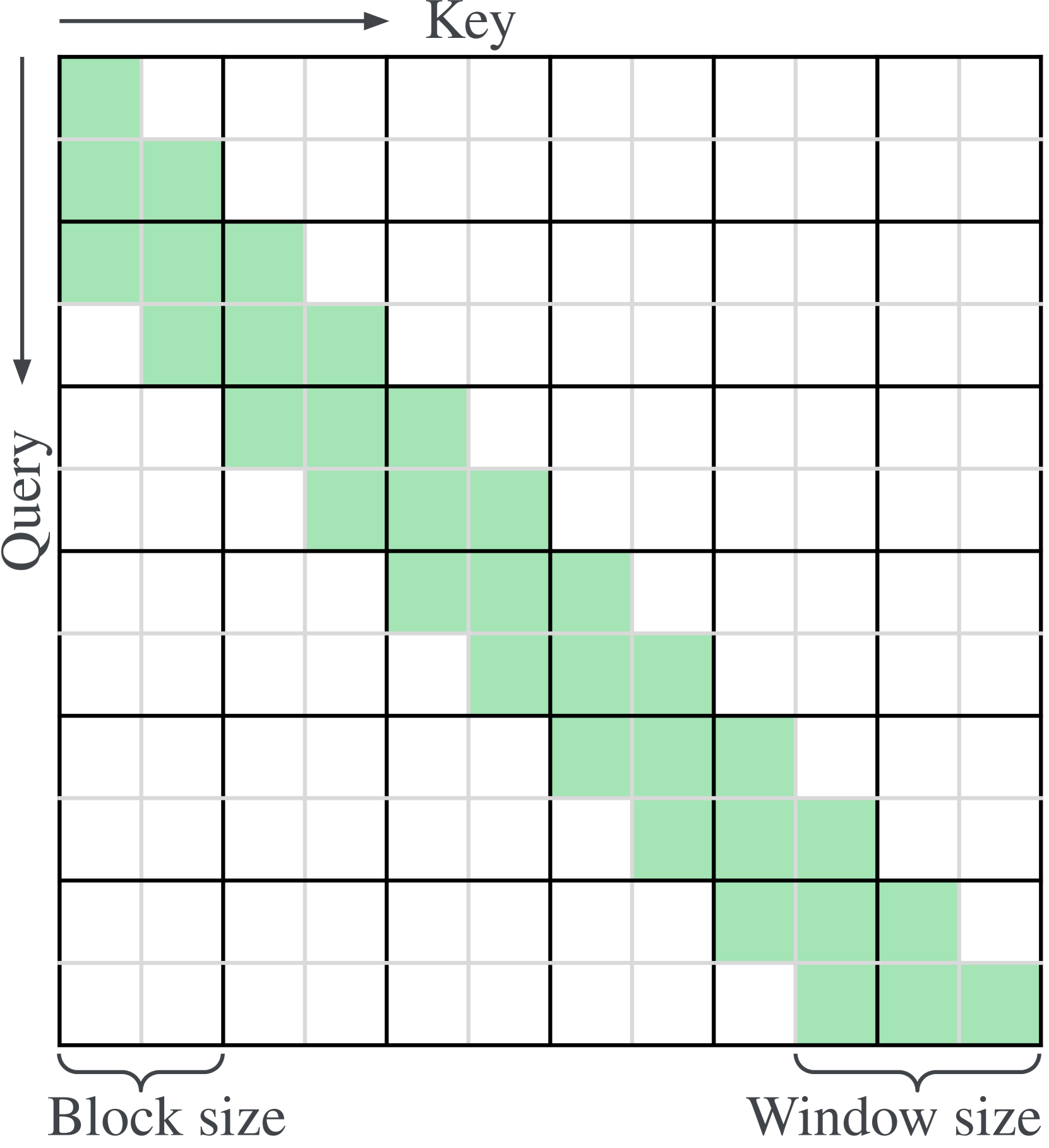
- Key contributions include a new attention mechanism called Block Sliding Window Attention (BSWA) and experiments on various tasks
Plain English Explanation
The paper proposes a new type of transformer model called TransformerFAM, which stands for Transformer with Feedback Attention Mechanism. The key idea is to incorporate "feedback attention" - a way for the model to attend to its own previous outputs and use that information to inform its current predictions.
This is inspired by the concept of working memory in the human brain, where we actively hold and manipulate information to complete tasks. The researchers hypothesize that by giving the transformer model this kind of feedback mechanism, it will be better able to learn, reason, and make predictions, especially on tasks that require contextual understanding and temporal reasoning.
To implement this, the authors introduce a new attention module called Block Sliding Window Attention (BSWA). This allows the model to efficiently attend to both local and long-range dependencies in the input and output sequences. The TransformerFAM architecture integrates BSWA and the feedback attention mechanism to capture both bottom-up and top-down information flows.
Technical Explanation
The paper introduces a new transformer-based model called TransformerFAM, which integrates a "feedback attention" mechanism to leverage working memory. This is in contrast to standard transformer models, which rely solely on bottom-up processing of the input sequence.
The key technical component is the Block Sliding Window Attention (BSWA) module. BSWA enables the model to efficiently attend to both local and long-range dependencies in the input and output sequences. It does this by splitting the sequence into blocks and applying attention within and across these blocks in a sliding window fashion.
The TransformerFAM architecture then incorporates BSWA alongside a feedback attention mechanism. This allows the model to not only attend to the current input, but also to its own previous outputs, similar to how human working memory operates. The authors hypothesize this will improve the model's ability to learn, reason, and make predictions, especially on tasks requiring contextual understanding and temporal reasoning.
The paper evaluates TransformerFAM on various tasks, including language modeling, question answering, and image denoising. The results demonstrate performance improvements over standard transformer baselines, validating the effectiveness of the feedback attention approach.
Critical Analysis
The paper presents a compelling case for incorporating feedback attention into transformer models, drawing inspiration from cognitive neuroscience research on working memory. The proposed TransformerFAM architecture and BSWA module are well-designed and rigorously evaluated across multiple tasks.
However, the paper does not address certain limitations and potential issues. For example, the feedback attention mechanism adds significant computational complexity to the model, which could hinder its adoption in real-world, resource-constrained applications. Additionally, the experiments are primarily focused on well-defined, narrow tasks, and it's unclear how well the approach would scale to more open-ended, real-world problems that require robust generalization.
Further research is needed to explore the broader implications of the feedback attention concept, such as its applicability to other neural network architectures, its ability to facilitate continual learning, and its potential biases or failure modes. Exploring these areas could lead to a deeper understanding of the role of working memory in machine learning and help guide the development of more human-like reasoning capabilities in artificial systems.
Conclusion
The TransformerFAM paper presents a promising approach to incorporating feedback attention into transformer models, drawing inspiration from the concept of working memory in human cognition. By leveraging both bottom-up and top-down information flows, the model demonstrates improved performance on a variety of tasks, suggesting that this type of architecture could be a valuable tool for building more flexible and reasoning-capable AI systems.
While the paper lays a solid foundation, further research is needed to explore the broader implications and potential limitations of the feedback attention mechanism. Addressing issues like computational complexity and evaluating the approach on more open-ended, real-world problems could help unlock the full potential of this innovative technique and bring us closer to artificial systems that can learn, reason, and solve problems in a more human-like way.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai, Manaal Faruqui, Siddharth Gopal
0
0
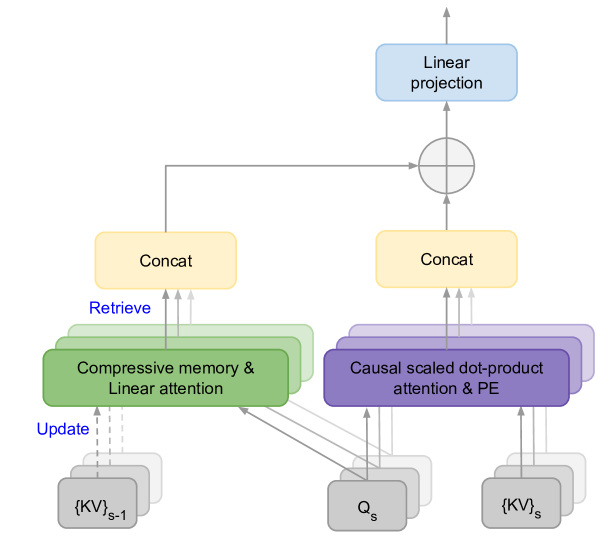
This work introduces an efficient method to scale Transformer-based Large Language Models (LLMs) to infinitely long inputs with bounded memory and computation. A key component in our proposed approach is a new attention technique dubbed Infini-attention. The Infini-attention incorporates a compressive memory into the vanilla attention mechanism and builds in both masked local attention and long-term linear attention mechanisms in a single Transformer block. We demonstrate the effectiveness of our approach on long-context language modeling benchmarks, 1M sequence length passkey context block retrieval and 500K length book summarization tasks with 1B and 8B LLMs. Our approach introduces minimal bounded memory parameters and enables fast streaming inference for LLMs.
4/11/2024
Remembering Transformer for Continual Learning
Yuwei Sun, Ippei Fujisawa, Arthur Juliani, Jun Sakuma, Ryota Kanai
0
0
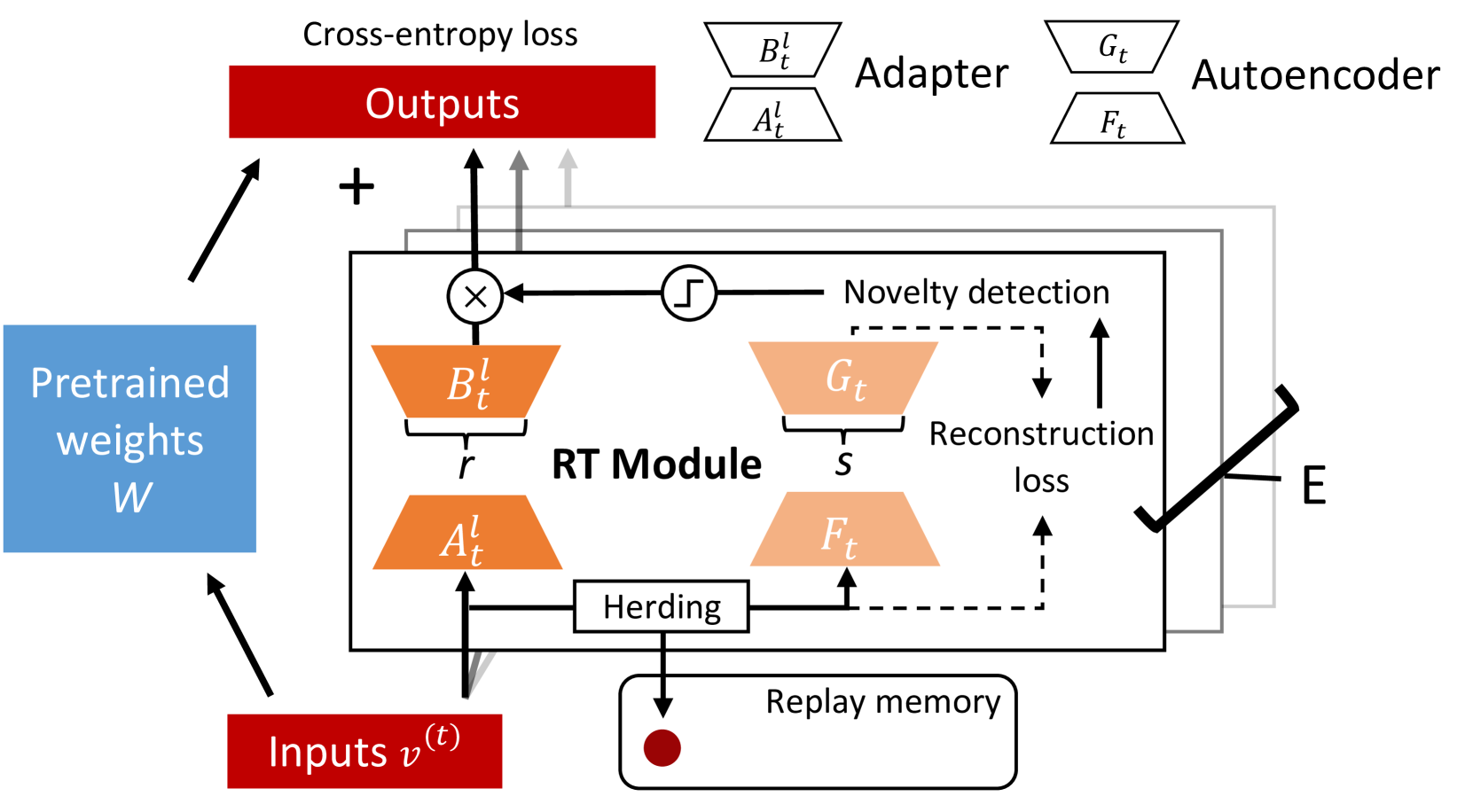
Neural networks encounter the challenge of Catastrophic Forgetting (CF) in continual learning, where new task learning interferes with previously learned knowledge. Existing data fine-tuning and regularization methods necessitate task identity information during inference and cannot eliminate interference among different tasks, while soft parameter sharing approaches encounter the problem of an increasing model parameter size. To tackle these challenges, we propose the Remembering Transformer, inspired by the brain's Complementary Learning Systems (CLS). Remembering Transformer employs a mixture-of-adapters architecture and a generative model-based novelty detection mechanism in a pretrained Transformer to alleviate CF. Remembering Transformer dynamically routes task data to the most relevant adapter with enhanced parameter efficiency based on knowledge distillation. We conducted extensive experiments, including ablation studies on the novelty detection mechanism and model capacity of the mixture-of-adapters, in a broad range of class-incremental split tasks and permutation tasks. Our approach demonstrated SOTA performance surpassing the second-best method by 15.90% in the split tasks, reducing the memory footprint from 11.18M to 0.22M in the five splits CIFAR10 task.
5/17/2024
New!BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
Sun Ao, Weilin Zhao, Xu Han, Cheng Yang, Zhiyuan Liu, Chuan Shi, Maosong Sun
0
0
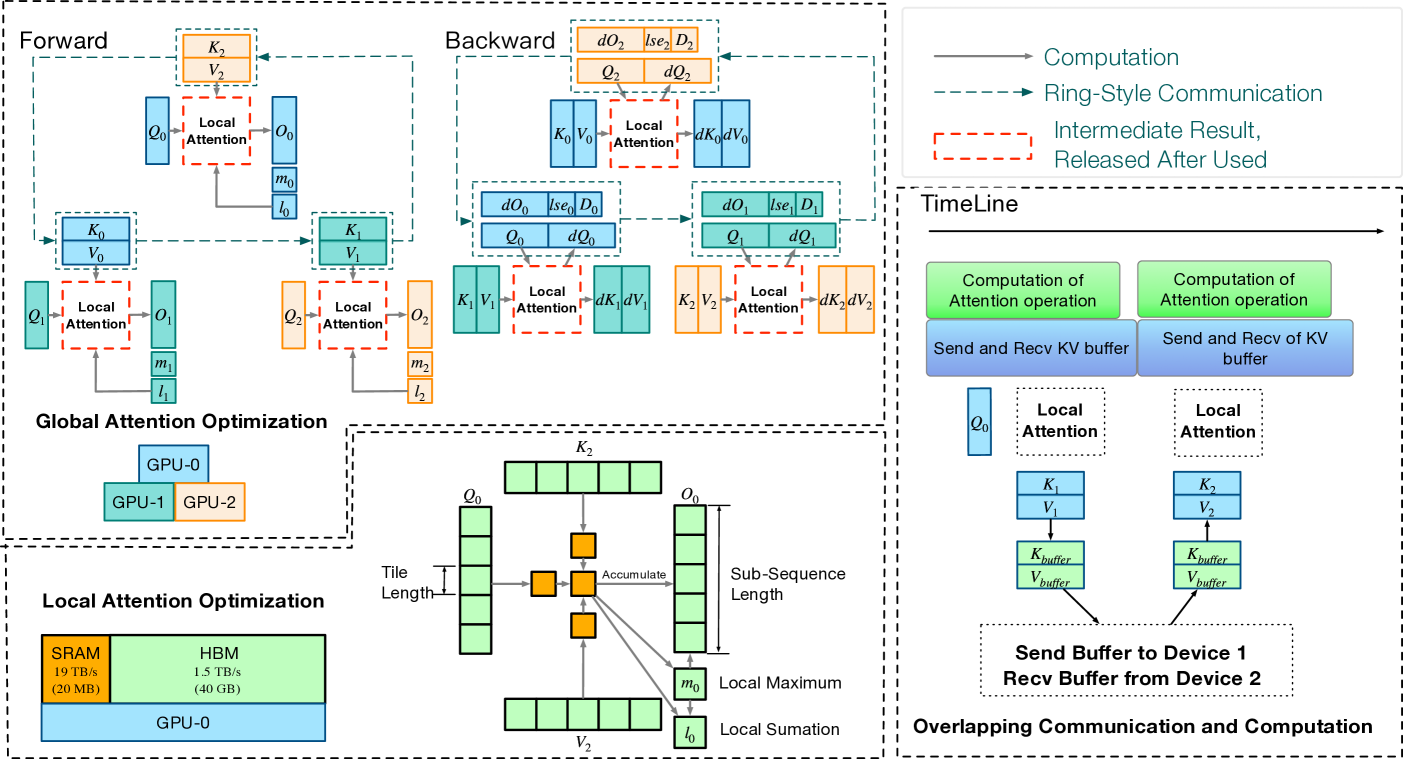
Effective attention modules have played a crucial role in the success of Transformer-based large language models (LLMs), but the quadratic time and memory complexities of these attention modules also pose a challenge when processing long sequences. One potential solution for the long sequence problem is to utilize distributed clusters to parallelize the computation of attention modules across multiple devices (e.g., GPUs). However, adopting a distributed approach inevitably introduces extra memory overheads to store local attention results and incurs additional communication costs to aggregate local results into global ones. In this paper, we propose a distributed attention framework named ``BurstAttention'' to optimize memory access and communication operations at both the global cluster and local device levels. In our experiments, we compare BurstAttention with other competitive distributed attention solutions for long sequence processing. The experimental results under different length settings demonstrate that BurstAttention offers significant advantages for processing long sequences compared with these competitive baselines, reducing 40% communication overheads and achieving 1.37 X speedup during training 128K sequence length on 32 X A100.
5/17/2024
New!Beyond Scaling Laws: Understanding Transformer Performance with Associative Memory
Xueyan Niu, Bo Bai, Lei Deng, Wei Han
0
0
Increasing the size of a Transformer model does not always lead to enhanced performance. This phenomenon cannot be explained by the empirical scaling laws. Furthermore, improved generalization ability occurs as the model memorizes the training samples. We present a theoretical framework that sheds light on the memorization process and performance dynamics of transformer-based language models. We model the behavior of Transformers with associative memories using Hopfield networks, such that each transformer block effectively conducts an approximate nearest-neighbor search. Based on this, we design an energy function analogous to that in the modern continuous Hopfield network which provides an insightful explanation for the attention mechanism. Using the majorization-minimization technique, we construct a global energy function that captures the layered architecture of the Transformer. Under specific conditions, we show that the minimum achievable cross-entropy loss is bounded from below by a constant approximately equal to 1. We substantiate our theoretical results by conducting experiments with GPT-2 on various data sizes, as well as training vanilla Transformers on a dataset of 2M tokens.
5/15/2024