MLP Can Be A Good Transformer Learner
2404.05657
0
0
Abstract
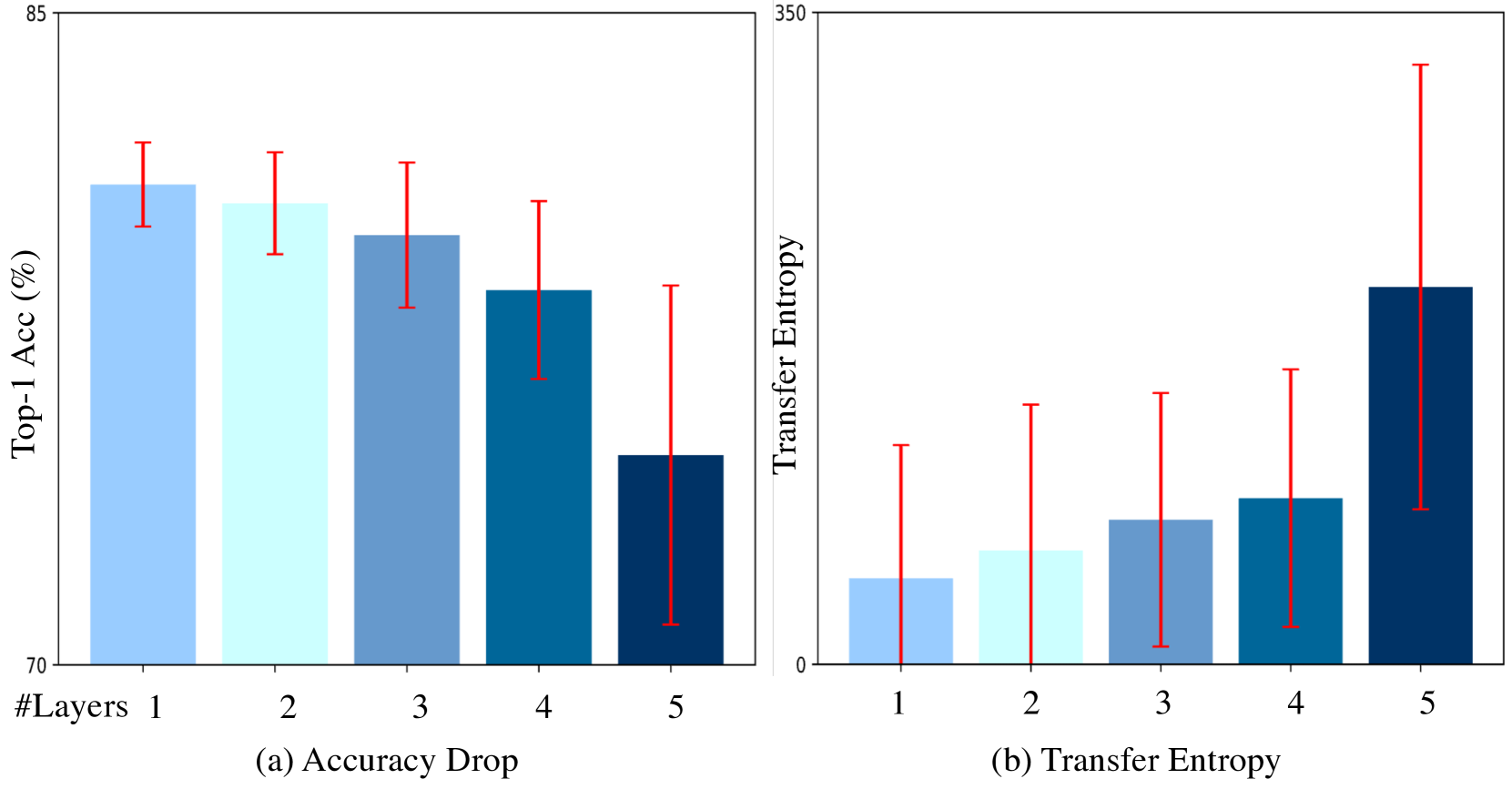
Self-attention mechanism is the key of the Transformer but often criticized for its computation demands. Previous token pruning works motivate their methods from the view of computation redundancy but still need to load the full network and require same memory costs. This paper introduces a novel strategy that simplifies vision transformers and reduces computational load through the selective removal of non-essential attention layers, guided by entropy considerations. We identify that regarding the attention layer in bottom blocks, their subsequent MLP layers, i.e. two feed-forward layers, can elicit the same entropy quantity. Meanwhile, the accompanied MLPs are under-exploited since they exhibit smaller feature entropy compared to those MLPs in the top blocks. Therefore, we propose to integrate the uninformative attention layers into their subsequent counterparts by degenerating them into identical mapping, yielding only MLP in certain transformer blocks. Experimental results on ImageNet-1k show that the proposed method can remove 40% attention layer of DeiT-B, improving throughput and memory bound without performance compromise. Code is available at https://github.com/sihaoevery/lambda_vit.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper investigates whether a simple Multilayer Perceptron (MLP) model can be a good alternative to more complex Transformer models for various language tasks.
- The authors compare the performance of an MLP model with that of Transformer models on a range of benchmarks, including text classification, question answering, and language modeling.
- The results suggest that a carefully designed MLP model can achieve comparable or even better performance than Transformer models, while being more computationally efficient.
Plain English Explanation
The researchers in this paper wanted to see if a basic Multilayer Perceptron (MLP) model could be just as good as more advanced Transformer models at language tasks. MLPs are simpler neural network architectures compared to Transformers, which use complex attention mechanisms.
The team tested the MLP model and various Transformer models on different language problems, like classifying text, answering questions, and generating text. Surprisingly, they found that the MLP model could match or even outperform the Transformer models in many cases, while being more efficient and faster to train.
This suggests that for certain language tasks, you may not always need the extra complexity of a Transformer model. A well-designed MLP can sometimes do just as well, or even better, using fewer computational resources. This could be useful in scenarios where speed and efficiency are important, like running AI models on mobile devices or in real-time applications.
Technical Explanation
The authors propose an MLP-based model, called MLP-Mixer, as an alternative to standard Transformer architectures for language tasks. MLP-Mixer consists of a series of MLP blocks, without any attention mechanisms.
The researchers compare the performance of MLP-Mixer to several popular Transformer models, including BERT, GPT-2, and T5, on a range of benchmark datasets for text classification, question answering, and language modeling.
The results show that MLP-Mixer can achieve comparable or even better performance than the Transformer models, while being more computationally efficient. The authors attribute this to the simplicity of the MLP architecture and its ability to effectively capture relevant features from the input text.
Critical Analysis
The paper provides a compelling case for the viability of MLP models as an alternative to Transformer architectures for certain language tasks. However, the authors acknowledge that Transformer models may still have advantages in domains that require more complex reasoning or long-range dependencies.
Additionally, the paper focuses on relatively simple language tasks and does not explore the performance of MLP-Mixer on more complex or domain-specific language problems. Further research may be needed to understand the limitations of MLP-Mixer and identify the specific scenarios where it outperforms Transformer models.
Conclusion
This paper challenges the prevailing assumption that Transformer models are always the best choice for language tasks. It demonstrates that a well-designed MLP model can achieve comparable or even superior performance to Transformer models, while being more computationally efficient.
The findings suggest that researchers and practitioners should not automatically default to Transformer architectures and should instead carefully consider the trade-offs between model complexity and performance, especially in applications where speed and efficiency are critical. The versatility of MLP models shown in this paper opens up new possibilities for building more efficient and practical language AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
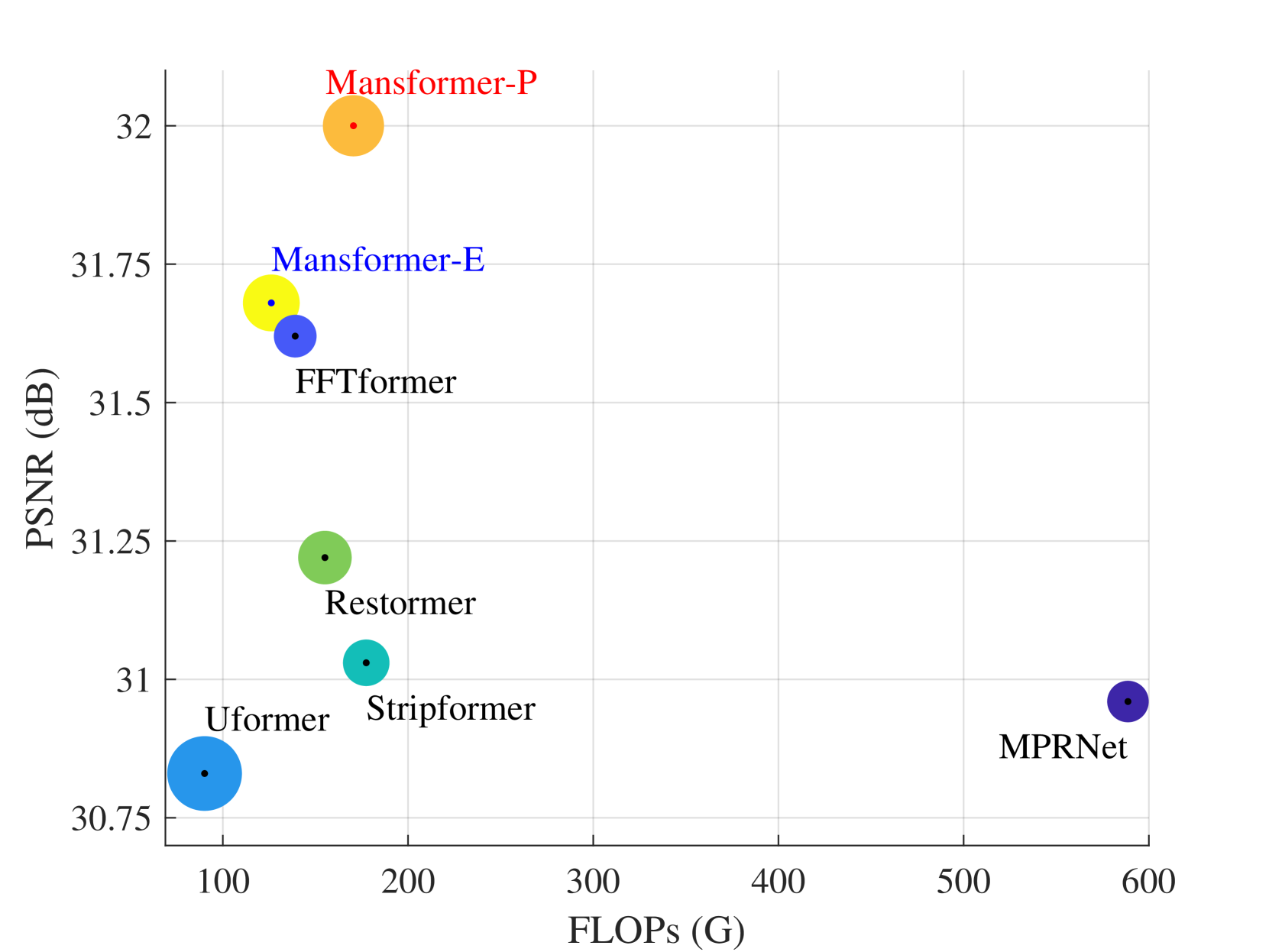
Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Pin-Hung Kuo, Jinshan Pan, Shao-Yi Chien, Ming-Hsuan Yang
0
0
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
4/10/2024
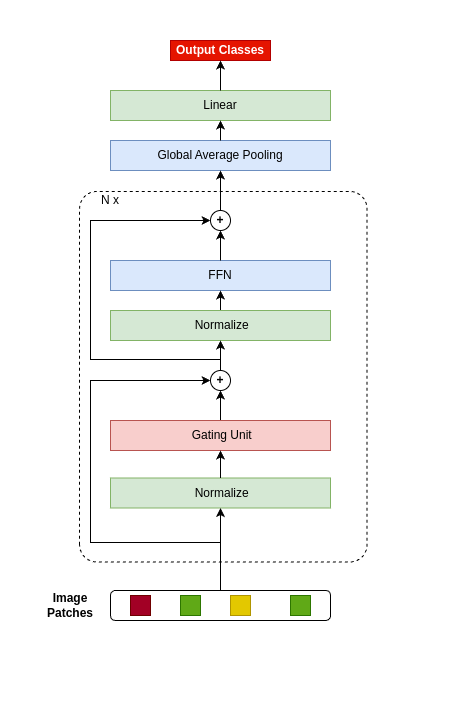
NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
Abdullah Nazhat Abdullah, Tarkan Aydin
0
0
The Attention mechanism is the main component of the Transformer architecture, and since its introduction, it has led to significant advancements in Deep Learning that span many domains and multiple tasks. The Attention Mechanism was utilized in Computer Vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal Attention layers with a Network in Network structure that enhances the static approach of the MLP Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
4/26/2024
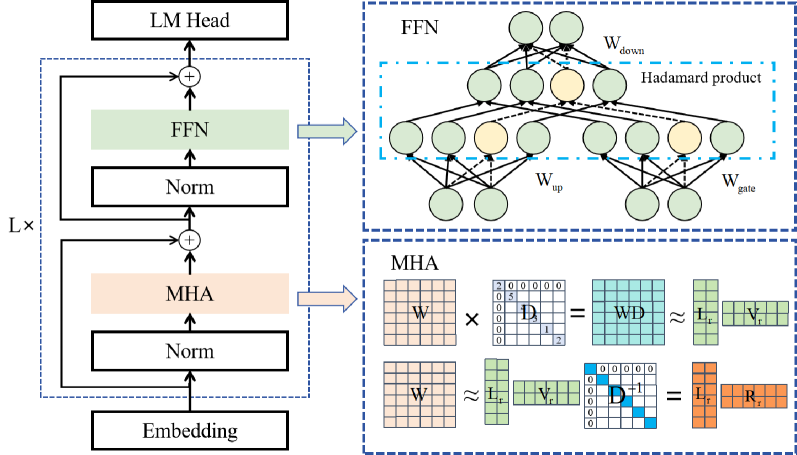
LoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models
Guangyan Li, Yongqiang Tang, Wensheng Zhang
0
0
Large language models (LLMs) show excellent performance in difficult tasks, but they often require massive memories and computational resources. How to reduce the parameter scale of LLMs has become research hotspots. In this study, we make an important observation that the multi-head self-attention (MHA) sub-layer of Transformer exhibits noticeable low-rank structure, while the feed-forward network (FFN) sub-layer does not. With this regard, we design a mixed compression model, which organically combines Low-Rank matrix approximation And structured Pruning (LoRAP). For the MHA sub-layer, we propose an input activation weighted singular value decomposition method to strengthen the low-rank characteristic. Furthermore, we discover that the weight matrices in MHA sub-layer have different low-rank degrees. Thus, a novel parameter allocation scheme according to the discrepancy of low-rank degrees is devised. For the FFN sub-layer, we propose a gradient-free structured channel pruning method. During the pruning, we get an interesting finding that the least important 1% of parameter actually play a vital role in model performance. Extensive evaluations on zero-shot perplexity and zero-shot task classification indicate that our proposal is superior to previous structured compression rivals under multiple compression ratios.
4/16/2024
SNP: Structured Neuron-level Pruning to Preserve Attention Scores
Kyunghwan Shim, Jaewoong Yun, Shinkook Choi
0
0
Multi-head self-attention (MSA) is a key component of Vision Transformers (ViTs), which have achieved great success in various vision tasks. However, their high computational cost and memory footprint hinder their deployment on resource-constrained devices. Conventional pruning approaches can only compress and accelerate the MSA module using head pruning, although the head is not an atomic unit. To address this issue, we propose a novel graph-aware neuron-level pruning method, Structured Neuron-level Pruning (SNP). SNP prunes neurons with less informative attention scores and eliminates redundancy among heads. Specifically, it prunes graphically connected query and key layers having the least informative attention scores while preserving the overall attention scores. Value layers, which can be pruned independently, are pruned to eliminate inter-head redundancy. Our proposed method effectively compresses and accelerates Transformer-based models for both edge devices and server processors. For instance, the DeiT-Small with SNP runs 3.1$times$ faster than the original model and achieves performance that is 21.94% faster and 1.12% higher than the DeiT-Tiny. Additionally, SNP combine successfully with conventional head or block pruning approaches. SNP with head pruning could compress the DeiT-Base by 80% of the parameters and computational costs and achieve 3.85$times$ faster inference speed on RTX3090 and 4.93$times$ on Jetson Nano.
4/19/2024